Bài 31.4. So sánh Fenwick Tree và Segment Tree
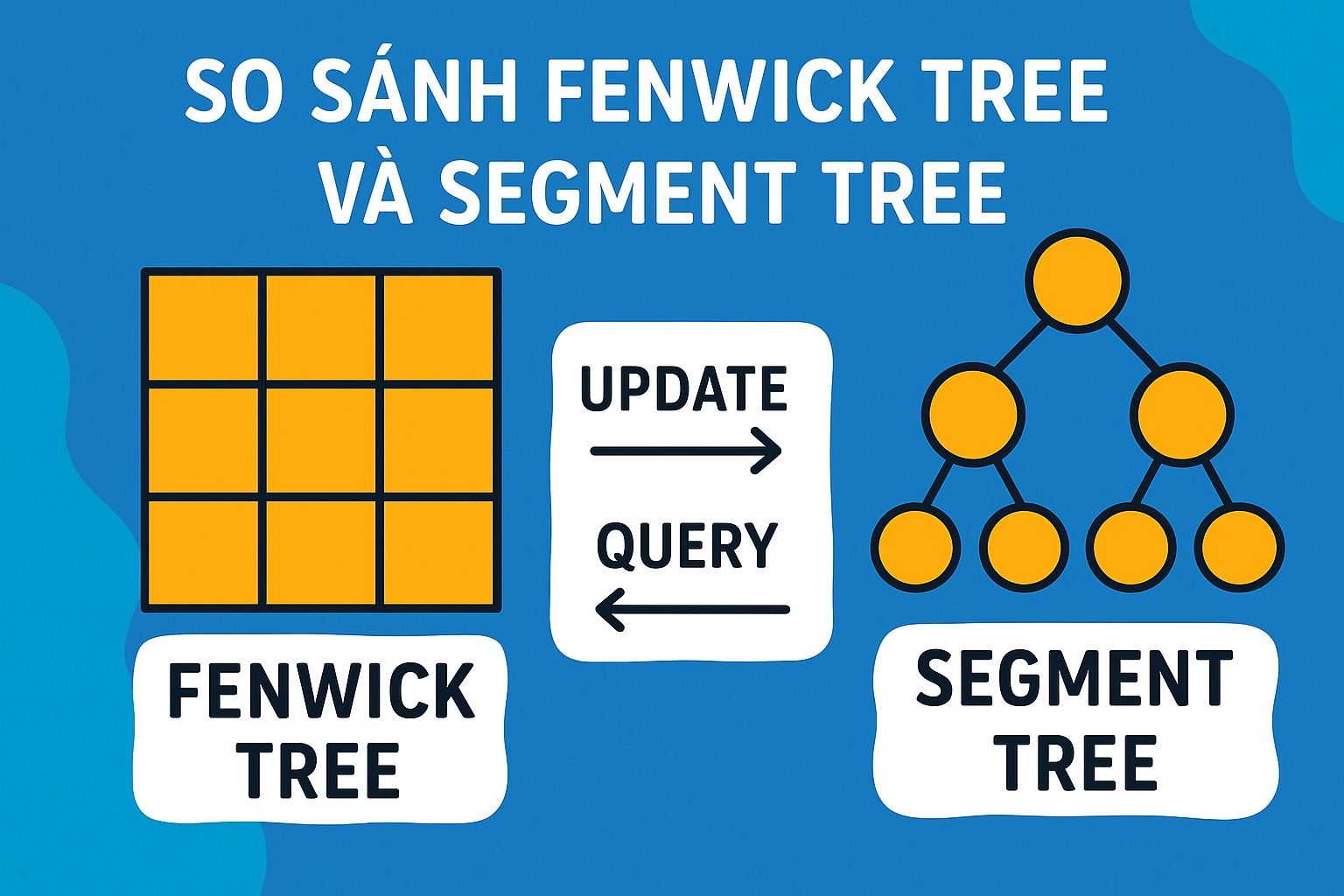
Bài 31.4. So sánh Fenwick Tree và Segment Tree
Trong thế giới lập trình cạnh tranh và xử lý dữ liệu, việc thực hiện các truy vấn trên khoảng (range queries) và cập nhật điểm (point updates) một cách hiệu quả là vô cùng quan trọng. Hai trong số những cấu trúc dữ liệu phổ biến nhất để giải quyết các bài toán này là Fenwick Tree (hay còn gọi là Binary Indexed Tree - BIT) và Segment Tree. Mặc dù cùng mục đích, chúng có cách tiếp cận, hiệu năng và độ phức tạp cài đặt khác nhau. Bài viết này sẽ đi sâu so sánh hai "gã khổng lồ" này để giúp bạn hiểu rõ khi nào nên sử dụng loại nào.
Cả Fenwick Tree và Segment Tree đều cho phép chúng ta thực hiện các thao tác cập nhật điểm (thay đổi giá trị một phần tử trong mảng gốc) và truy vấn khoảng (tính toán một giá trị nào đó trên một đoạn con của mảng) với độ phức tạp thời gian là O(log N), trong đó N là kích thước của mảng. Tuy nhiên, sự khác biệt nằm ở cơ chế hoạt động, độ linh hoạt và độ phức tạp cài đặt.
Hãy cùng tìm hiểu chi tiết về từng cấu trúc và sau đó so sánh chúng.
Fenwick Tree (Binary Indexed Tree - BIT)
Fenwick Tree là một cấu trúc dữ liệu dựa trên mảng, được thiết kế để xử lý hiệu quả các bài toán cập nhật điểm và truy vấn tiền tố (prefix query). Mặc dù tên gọi có từ "Tree", Fenwick Tree không phải là một cây nhị phân theo nghĩa cấu trúc liên kết, mà là một cách tổ chức dữ liệu trong một mảng để tận dụng các tính chất nhị phân của chỉ số.
Ý tưởng cốt lõi của Fenwick Tree là mỗi phần tử bit[i] lưu trữ tổng của một đoạn con đặc biệt của mảng gốc, đoạn con này kết thúc tại chỉ số i và có độ dài được xác định bởi bit cuối cùng của chỉ số i. Cụ thể, đoạn con đó có độ dài là i & (-i), còn được gọi là lowbit(i). Ví dụ, lowbit(12) = lowbit(1100_2) = 100_2 = 4. Do đó, bit[12] lưu tổng của 4 phần tử kết thúc tại chỉ số 12.
Cơ chế hoạt động (Ví dụ với truy vấn tổng)
- Cập nhật (Point Update): Khi bạn thêm một giá trị
valvào phần tử tại chỉ sốidxtrong mảng gốc, bạn cần cập nhật tất cả các đoạn con trong Fenwick Tree mà chứa phần tử tạiidx. Điều này được thực hiện bằng cách di chuyển lên cây theo các chỉ sốidx,idx + lowbit(idx),idx + 2*lowbit(idx), ... cho đến khi vượt quá kích thước mảng. Tại mỗi chỉ số này, bạn cộng thêmval. - Truy vấn Tiền tố (Prefix Query): Để tính tổng các phần tử từ chỉ số 1 đến
idx, bạn chỉ cần cộng dồn giá trị tại các chỉ sốidx,idx - lowbit(idx),idx - 2*lowbit(idx), ... cho đến khi chỉ số trở về 0.
Lưu ý: Fenwick Tree thường được cài đặt với mảng gốc (và mảng bit) dùng chỉ số 1-based để đơn giản hóa thao tác lowbit.
Ví dụ Code C++ (Fenwick Tree cho Point Update và Range Sum Query)
#include <vector>
#include <iostream>
// Fenwick Tree (Binary Indexed Tree) implementation
// Supports point updates and range sum queries
// Assumes 1-based indexing for convenience with lowbit
class FenwickTree {
private:
std::vector<long long> bit; // Mảng BIT, lưu trữ tổng các đoạn con
int size; // Kích thước mảng gốc
// Hàm tính giá trị lowbit(i) = i & (-i)
// lowbit(i) cho biết giá trị của bit có trọng số nhỏ nhất trong biểu diễn nhị phân của i
int lowbit(int i) const {
return i & (-i);
}
public:
// Constructor: Khởi tạo FT với kích thước n
// Mảng bit cần kích thước n+1 cho 1-based indexing
FenwickTree(int n) : size(n), bit(n + 1, 0) {}
// Cập nhật: Thêm giá trị 'val' vào phần tử tại chỉ số 'idx' (1-based)
// Ta đi lên cây bằng cách cộng lowbit(idx) vào idx
void update(int idx, int val) {
for (; idx <= size; idx += lowbit(idx)) {
bit[idx] += val;
}
}
// Truy vấn tiền tố: Tính tổng các phần tử từ chỉ số 1 đến 'idx' (1-based)
// Ta đi xuống cây bằng cách trừ lowbit(idx) khỏi idx
long long query(int idx) const {
long long sum = 0;
for (; idx > 0; idx -= lowbit(idx)) {
sum += bit[idx];
}
return sum;
}
// Truy vấn khoảng: Tính tổng các phần tử trong khoảng [l, r] (1-based)
// Tổng [l, r] = Tổng [1, r] - Tổng [1, l-1]
long long queryRange(int l, int r) const {
if (l > r) return 0;
return query(r) - query(l - 1);
}
// Hàm xây dựng FT từ mảng ban đầu (arr_0based)
// Chú ý: Mảng đầu vào là 0-based, FT sử dụng 1-based.
// Cần gọi update(i+1, arr_0based[i])
void build(const std::vector<int>& arr_0based) {
// Đảm bảo kích thước mảng đầu vào khớp với kích thước FT
if (arr_0based.size() != size) {
// Xử lý lỗi hoặc thông báo
std::cerr << "Kích thước mảng đầu vào không khớp!" << std::endl;
return;
}
// Xây dựng bằng cách cập nhật từng phần tử
for (int i = 0; i < size; ++i) {
update(i + 1, arr_0based[i]);
}
}
};
/*
// Ví dụ sử dụng (bạn có thể bỏ comment để chạy thử)
int main() {
std::vector<int> arr = {1, 2, 3, 4, 5}; // Mảng gốc 0-based
int n = arr.size();
// Khởi tạo và xây dựng Fenwick Tree
FenwickTree ft(n);
ft.build(arr);
// Ví dụ truy vấn tổng
// Query tổng [1, 3] trong mảng gốc (tức là chỉ số 0, 1, 2)
// FT dùng 1-based, nên queryRange(1, 3) tương ứng với mảng gốc arr[0...2]
std::cout << "Sum of arr[0..2]: " << ft.queryRange(1, 3) << std::endl; // Expected: 1+2+3 = 6
// Query tổng [3, 5] trong mảng gốc (tức là chỉ số 2, 3, 4)
std::cout << "Sum of arr[2..4]: " << ft.queryRange(3, 5) << std::endl; // Expected: 3+4+5 = 12
// Ví dụ cập nhật
// Cập nhật phần tử tại chỉ số 1 của mảng gốc (giá trị 2) thành giá trị mới là 10.
// Trong FT (1-based), đây là chỉ số 2. Ta *thêm* 10 vào giá trị hiện tại (2), delta = 10-2 = 8
// Để đơn giản, nếu update(idx, val) nghĩa là *giá trị mới* tại idx là val,
// ta cần tính delta = val - queryRange(idx, idx).
// Hoặc, nếu update(idx, val) nghĩa là *thêm* val vào giá trị hiện tại:
ft.update(2, 8); // Thêm 8 vào phần tử tại chỉ số 2 (1-based), tương ứng arr[1]
// arr[1] từ 2 -> 2+8 = 10
// Truy vấn lại sau khi cập nhật
std::cout << "Sum of arr[0..2] after update: " << ft.queryRange(1, 3) << std::endl; // Expected: 1 + (2+8) + 3 = 14
std::cout << "Sum of arr[0..4] after update: " << ft.queryRange(1, 5) << std::endl; // Expected: 1 + (2+8) + 3 + 4 + 5 = 23
return 0;
}
*/
Giải thích Code Fenwick Tree:
- Class
FenwickTreechứa một vectorbitđể lưu trữ cấu trúc cây, vàsizelà kích thước của mảng gốc. - Hàm
lowbit(i)trả vềi & (-i). Đây là "phép màu" của Fenwick Tree, giúp xác định độ dài đoạn con màbit[i]đại diện và giúp di chuyển giữa các chỉ số liên quan. - Hàm
update(idx, val): Để thêmvalvào phần tử gốc tạiidx(1-based), chúng ta lặp qua các chỉ sốidx,idx + lowbit(idx),idx + 2*lowbit(idx), v.v... và cộngvalvàobittại các chỉ số này. Vòng lặp dừng khiidxvượt quásize. - Hàm
query(idx): Để tính tổng tiền tố đếnidx(1-based), chúng ta lặp qua các chỉ sốidx,idx - lowbit(idx),idx - 2*lowbit(idx), v.v... và cộngbittại các chỉ số này vào tổng. Vòng lặp dừng khiidxtrở thành 0. - Hàm
queryRange(l, r): Dựa trên tính chất tổng tiền tố, tổng trên đoạn[l, r]bằng tổng tiền tố đếnrtrừ đi tổng tiền tố đếnl-1. - Hàm
build(arr_0based): Xây dựng FT từ mảng gốc. Vì FT dùng 1-based, ta duyệt mảng gốc (0-based) và gọiupdate(i+1, arr_0based[i])cho từng phần tử.
Ưu và Nhược điểm của Fenwick Tree:
- Ưu điểm:
- Cài đặt đơn giản: Dựa trên mảng, không cần cấu trúc cây tường minh hay đệ quy phức tạp.
- Không gian: Thường chỉ cần mảng kích thước N+1, hiệu quả về bộ nhớ (~O(N)).
- Hằng số thời gian nhỏ: Các thao tác
updatevàquerytuy cùng độ phức tạp lý thuyết O(log N) với Segment Tree, nhưng hằng số thời gian nhỏ hơn do các vòng lặp đơn giản hơn.
- Nhược điểm:
- Hạn chế về loại thao tác: Fenwick Tree chủ yếu phù hợp với các thao tác có tính chất tiền tố cộng gộp và có thể đảo ngược (như tổng:
Sum(l, r) = Sum(r) - Sum(l-1)). Việc xử lý các thao tác khác như Min/Max trên khoảng là không đơn giản hoặc không khả thi với cấu trúc cơ bản. - Truy vấn khoảng không phải tổng: Khó khăn hơn hoặc không thể trực tiếp.
- Cập nhật khoảng (Range Update): Có thể thực hiện bằng cách sử dụng hai Fenwick Tree (kỹ thuật delta array), nhưng cách này phức tạp hơn Segment Tree với lazy propagation.
- Mở rộng: Mở rộng lên 2D hoặc các cấu trúc phức tạp hơn có thể kém trực quan hơn.
- Hạn chế về loại thao tác: Fenwick Tree chủ yếu phù hợp với các thao tác có tính chất tiền tố cộng gộp và có thể đảo ngược (như tổng:
Segment Tree
Segment Tree là một cây nhị phân, trong đó mỗi nút đại diện cho một khoảng (segment) hoặc đoạn con của mảng gốc. Nút gốc đại diện cho toàn bộ mảng. Các nút con của một nút đại diện cho hai nửa của khoảng mà nút cha nó đại diện. Các nút lá đại diện cho các phần tử riêng lẻ của mảng gốc. Mỗi nút lưu trữ thông tin (ví dụ: tổng, giá trị nhỏ nhất, giá trị lớn nhất) về khoảng mà nó đại diện.
Thông tin tại một nút nội bộ thường được tính toán từ thông tin tại các nút con của nó. Điều này cho phép các truy vấn và cập nhật được thực hiện bằng cách duyệt cây một cách hiệu quả.
Cơ chế hoạt động (Ví dụ với truy vấn tổng)
- Xây dựng (Build): Cây được xây dựng đệ quy. Nút lá được gán giá trị từ mảng gốc. Nút nội bộ tính toán giá trị của nó bằng cách kết hợp giá trị từ hai nút con (ví dụ: tổng = tổng con trái + tổng con phải).
- Cập nhật (Point Update): Để cập nhật phần tử tại chỉ số
idx, bạn duyệt cây từ nút gốc xuống nút lá tương ứng vớiidx. Cập nhật giá trị tại nút lá đó, sau đó đi ngược lên cây, cập nhật giá trị của các nút cha bằng cách kết hợp lại giá trị của các nút con đã thay đổi. - Truy vấn (Range Query): Để truy vấn thông tin trên khoảng
[L, R], bạn bắt đầu từ nút gốc và duyệt cây.- Nếu khoảng của nút hiện tại hoàn toàn nằm ngoài khoảng truy vấn
[L, R], bỏ qua nút này (trả về giá trị "không ảnh hưởng" cho phép toán, ví dụ 0 cho tổng). - Nếu khoảng của nút hiện tại hoàn toàn nằm trong khoảng truy vấn
[L, R], trả về giá trị đã lưu tại nút này. - Nếu khoảng của nút hiện tại cắt khoảng truy vấn
[L, R], đệ quy sang cả hai nút con và kết hợp kết quả.
- Nếu khoảng của nút hiện tại hoàn toàn nằm ngoài khoảng truy vấn
Ví dụ Code C++ (Segment Tree cho Point Update và Range Sum Query)
#include <vector>
#include <iostream>
#include <functional> // For std::function (optional but can make combine clearer)
// Segment Tree implementation
// Supports point updates and range queries
// Can be easily adapted for various associative operations (sum, min, max, etc.)
// Assumes 0-based indexing for the original array
class SegmentTree {
private:
std::vector<long long> tree; // Mảng lưu trữ cây (thường kích thước 4*N)
int size; // Kích thước mảng gốc
// std::function<long long(long long, long long)> combine_op; // Phép kết hợp
// Hàm kết hợp kết quả từ hai nút con (ví dụ: tổng)
// Thay đổi hàm này cho các bài toán Min/Max/GCD...
long long combine(long long left, long long right) const {
return left + right; // Phép cộng cho bài toán tổng
}
// Hàm xây dựng cây (đệ quy)
// node: chỉ số của nút hiện tại trong mảng tree (thường bắt đầu từ 1)
// start, end: khoảng mà nút node đại diện trong mảng gốc
// arr: mảng gốc
void build(const std::vector<int>& arr, int node, int start, int end) {
if (start == end) {
// Nếu là nút lá, lưu giá trị từ mảng gốc
tree[node] = arr[start];
} else {
int mid = (start + end) / 2;
// Xây dựng cây con trái và phải
build(arr, 2 * node, start, mid); // Nút con trái đại diện cho [start, mid]
build(arr, 2 * node + 1, mid + 1, end); // Nút con phải đại diện cho [mid+1, end]
// Kết hợp kết quả từ hai nút con
tree[node] = combine(tree[2 * node], tree[2 * node + 1]);
}
}
// Cập nhật giá trị tại một chỉ số (đệ quy)
// node: chỉ số của nút hiện tại
// start, end: khoảng của nút hiện tại
// idx: chỉ số cần cập nhật trong mảng gốc (0-based)
// val: giá trị mới tại idx
void update(int node, int start, int end, int idx, int val) {
if (start == end) {
// Nếu đến nút lá tương ứng, cập nhật giá trị
tree[node] = val;
} else {
int mid = (start + end) / 2;
if (start <= idx && idx <= mid) {
// Nếu idx nằm trong khoảng con trái, đệ quy sang trái
update(2 * node, start, mid, idx, val);
} else {
// Nếu idx nằm trong khoảng con phải, đệ quy sang phải
update(2 * node + 1, mid + 1, end, idx, val);
}
// Sau khi cập nhật con, cập nhật lại nút cha bằng cách kết hợp con
tree[node] = combine(tree[2 * node], tree[2 * node + 1]);
}
}
// Truy vấn giá trị trên một khoảng [l, r] (đệ quy)
// node: chỉ số của nút hiện tại
// start, end: khoảng của nút hiện tại
// l, r: khoảng cần truy vấn (0-based)
long long query(int node, int start, int end, int l, int r) const {
if (r < start || end < l) {
// Khoảng của nút hiện tại hoàn toàn nằm ngoài khoảng truy vấn
// Trả về giá trị "không ảnh hưởng" cho phép toán (0 cho tổng)
return 0; // Identity for sum
}
if (l <= start && end <= r) {
// Khoảng của nút hiện tại hoàn toàn nằm trong khoảng truy vấn
// Trả về giá trị đã lưu tại nút này
return tree[node];
}
// Khoảng của nút hiện tại cắt khoảng truy vấn hoặc chứa khoảng truy vấn
// Đệ quy sang hai con và kết hợp kết quả
int mid = (start + end) / 2;
long long p1 = query(2 * node, start, mid, l, r);
long long p2 = query(2 * node + 1, mid + 1, end, l, r);
return combine(p1, p2); // Kết hợp kết quả từ hai con
}
public:
// Constructor: Khởi tạo Segment Tree từ mảng gốc
// arr: mảng gốc (0-based)
SegmentTree(const std::vector<int>& arr) {
size = arr.size();
// Kích thước mảng tree thường là 4 * size để đảm bảo đủ chỗ
tree.resize(4 * size);
if (size > 0) {
// Bắt đầu xây dựng từ nút gốc (chỉ số 1), đại diện cho khoảng [0, size-1]
build(arr, 1, 0, size - 1);
}
}
// Public update function (0-based index)
// Cập nhật giá trị tại chỉ số 'idx' thành 'val'
void update(int idx, int val) {
if (idx >= 0 && idx < size) {
update(1, 0, size - 1, idx, val); // Gọi hàm cập nhật đệ quy từ gốc
}
}
// Public query function (0-based range [l, r])
// Truy vấn giá trị trên khoảng [l, r]
long long queryRange(int l, int r) const {
if (l > r || l < 0 || r >= size) {
// Xử lý trường hợp khoảng không hợp lệ
// Trả về giá trị "không ảnh hưởng" cho phép toán (0 cho tổng)
return 0;
}
return query(1, 0, size - 1, l, r); // Gọi hàm truy vấn đệ quy từ gốc
}
};
/*
// Ví dụ sử dụng (bạn có thể bỏ comment để chạy thử)
int main() {
std::vector<int> arr = {1, 2, 3, 4, 5}; // Mảng gốc 0-based
int n = arr.size();
// Khởi tạo và xây dựng Segment Tree
SegmentTree st(arr);
// Ví dụ truy vấn tổng
std::cout << "Sum of arr[0..2]: " << st.queryRange(0, 2) << std::endl; // Expected: 1+2+3 = 6
std::cout << "Sum of arr[2..4]: " << st.queryRange(2, 4) << std::endl; // Expected: 3+4+5 = 12
// Ví dụ cập nhật
// Cập nhật phần tử tại chỉ số 1 của mảng gốc (giá trị 2) thành giá trị mới là 10.
st.update(1, 10); // arr[1] từ 2 -> 10
// Truy vấn lại sau khi cập nhật
std::cout << "Sum of arr[0..2] after update: " << st.queryRange(0, 2) << std::endl; // Expected: 1 + 10 + 3 = 14
std::cout << "Sum of arr[0..4] after update: " << st.queryRange(0, 4) << std::endl; // Expected: 1 + 10 + 3 + 4 + 5 = 23
return 0;
}
*/
Giải thích Code Segment Tree:
- Class
SegmentTreechứa vectortreeđể lưu trữ các giá trị của các nút. Kích thước 4*N là một ước tính an toàn để đảm bảo đủ chỗ cho cây (tối đa khoảng 2N-1 nút cho cây đầy đủ, nhưng mảng biểu diễn cây có thể cần đến 4N ở trường hợp tệ nhất).sizelà kích thước mảng gốc. - Hàm
combine(left, right): Định nghĩa phép kết hợp giá trị từ hai nút con. Với bài toán tổng, đó là phép cộng. Bạn sẽ thay đổi hàm này nếu muốn xử lý Min, Max, GCD, v.v... - Hàm
build(arr, node, start, end): Là hàm đệ quy xây dựng cây.- Trường hợp cơ sở:
start == end, ta ở nút lá, gántree[node]bằngarr[start]. - Trường hợp đệ quy: Tính
mid, gọi đệ quy để xây dựng cây con trái (2*node) và cây con phải (2*node + 1), sau đó kết hợp kết quả từ hai con để lưu vàotree[node].
- Trường hợp cơ sở:
- Hàm
update(node, start, end, idx, val): Là hàm đệ quy cập nhật.- Trường hợp cơ sở:
start == end == idx, tìm thấy nút lá cần cập nhật, gántree[node] = val. - Trường hợp đệ quy: Tính
mid. Nếuidxnằm trong khoảng con trái, gọi đệ quy trái. Nếu nằm trong khoảng con phải, gọi đệ quy phải. Sau khi gọi đệ quy, kết hợp lại giá trị tạitree[node]từ các con.
- Trường hợp cơ sở:
- Hàm
query(node, start, end, l, r): Là hàm đệ quy truy vấn.- Trường hợp 1: Khoảng của nút hiện tại
[start, end]không giao với khoảng truy vấn[l, r]. Trả về giá trị trung lập của phép kết hợp (0 cho tổng). - Trường hợp 2: Khoảng của nút hiện tại
[start, end]nằm hoàn toàn trong khoảng truy vấn[l, r]. Trả vềtree[node]. - Trường hợp 3: Khoảng của nút hiện tại cắt khoảng truy vấn. Chia khoảng của nút làm hai nửa (
[start, mid]và[mid+1, end]), gọi đệ quy trên cả hai nửa và kết hợp kết quả.
- Trường hợp 1: Khoảng của nút hiện tại
- Các hàm
update(idx, val)vàqueryRange(l, r)public chỉ là wrapper gọi các hàm đệ quy private từ nút gốc (node 1) với khoảng ban đầu là[0, size-1].
Ưu và Nhược điểm của Segment Tree:
- Ưu điểm:
- Linh hoạt: Hỗ trợ mọi phép toán kết hợp (associative operation) trên khoảng, không chỉ tổng (Min, Max, GCD, OR, AND...). Bạn chỉ cần thay đổi hàm
combinevà giá trị trung lập cho các trường hợp không giao nhau. - Truy vấn khoảng trực tiếp: Được thiết kế để thực hiện truy vấn trên bất kỳ khoảng nào một cách trực tiếp và trực quan.
- Cập nhật khoảng (Range Update): Có thể mở rộng để hỗ trợ cập nhật trên một khoảng (ví dụ: cộng thêm v vào tất cả phần tử trong khoảng [L, R]) một cách hiệu quả bằng kỹ thuật Lazy Propagation, mặc dù cài đặt phức tạp hơn đáng kể.
- Mở rộng: Mở rộng lên 2D hoặc các cấu trúc phức tạp hơn thường trực quan hơn (cây của cây).
- Linh hoạt: Hỗ trợ mọi phép toán kết hợp (associative operation) trên khoảng, không chỉ tổng (Min, Max, GCD, OR, AND...). Bạn chỉ cần thay đổi hàm
- Nhược điểm:
- Cài đặt phức tạp hơn: Đòi hỏi hiểu biết về đệ quy và quản lý các khoảng.
- Không gian: Thường cần kích thước mảng gấp 4 lần kích thước mảng gốc (~O(N)), tốn bộ nhớ hơn Fenwick Tree.
- Hằng số thời gian lớn hơn: Mặc dù độ phức tạp lý thuyết là O(log N), các thao tác thường chậm hơn một chút so với Fenwick Tree do có nhiều lệnh gọi đệ quy và phân nhánh.
So sánh Trực tiếp: Fenwick Tree vs. Segment Tree
| Đặc điểm | Fenwick Tree (BIT) | Segment Tree |
|---|---|---|
| Cấu trúc | Dựa trên mảng, không phải cây tường minh | Cây nhị phân, thường biểu diễn bằng mảng |
| Cài đặt | Đơn giản hơn | Phức tạp hơn (thường dùng đệ quy) |
| Không gian | ~O(N) (kích thước N+1) | \(O(N) (kích thước \)4N) |
| Thời gian (Update) | O(log N) | O(log N) |
| Thời gian (Query) | O(log N) (chủ yếu cho tiền tố/tổng) | O(log N) (cho mọi khoảng và phép toán kết hợp) |
| Phép toán | Chủ yếu tổng/đếm (cần tính chất tiền tố) | Mọi phép toán kết hợp (min, max, sum, GCD...) |
| Truy vấn khoảng | Cần tính toán dựa trên truy vấn tiền tố (query(r) - query(l-1)) |
Truy vấn trực tiếp trên khoảng (queryRange(l, r)) |
| Cập nhật khoảng | Có thể (dùng 2 BIT, phức tạp) | Có thể (dùng Lazy Propagation, phức tạp) |
| Hằng số thời gian | Nhỏ hơn | Lớn hơn |
| Độ linh hoạt | Kém linh hoạt hơn với các phép toán khác tổng | Rất linh hoạt với các phép toán khác nhau |
Khi nào sử dụng cấu trúc nào?
Việc lựa chọn giữa Fenwick Tree và Segment Tree phụ thuộc vào yêu cầu cụ thể của bài toán:
Sử dụng Fenwick Tree khi:
- Bài toán chỉ yêu cầu cập nhật điểm và truy vấn tổng trên khoảng.
- Bộ nhớ là hạn chế đáng kể.
- Bạn muốn cài đặt nhanh chóng và đơn giản hơn.
- Bạn cần thực hiện cập nhật khoảng và truy vấn điểm (kỹ thuật delta array trên FT rất hiệu quả cho trường hợp này).
Sử dụng Segment Tree khi:
- Bài toán yêu cầu truy vấn khoảng với các phép toán khác tổng (Min, Max, GCD, v.v...).
- Bạn cần hỗ trợ cập nhật khoảng một cách hiệu quả (với lazy propagation).
- Sự linh hoạt để mở rộng hoặc thay đổi phép toán là quan trọng.
- Không gian bộ nhớ không phải là vấn đề quá lớn.
Bài tập ví dụ:
Dãy B
Trong một buổi tập luyện âm nhạc, FullHouse Dev nhận thấy giai điệu của một bản nhạc có đặc điểm rất thú vị. Giai điệu này tăng dần rồi giảm dần, giống như một dãy số đặc biệt mà họ gọi là dãy B. Lấy cảm hứng từ điều này, họ quyết định nghiên cứu sâu hơn về loại dãy số này.
Bài toán
Một dãy \(A\) có độ dài \(n\) được gọi là dãy B khi thỏa mãn các điều kiện sau:
- Dãy ban đầu tăng nghiêm ngặt rồi giảm nghiêm ngặt (phần giảm có thể không tồn tại).
- Mọi phần tử trong dãy \(A\), ngoại trừ phần tử lớn nhất, xuất hiện tối đa hai lần (một lần ở phần tăng và một lần ở phần giảm). Phần tử lớn nhất xuất hiện đúng một lần.
- Tất cả các phần tử xuất hiện ở phần giảm phải đã xuất hiện một lần ở phần tăng.
INPUT FORMAT:
- Dòng đầu tiên chứa số nguyên \(N\) - độ dài của dãy \(S\).
- Dòng thứ hai chứa \(N\) số nguyên cách nhau bởi dấu cách - các phần tử của dãy \(S\).
- Dòng thứ ba chứa số nguyên \(Q\) - số lượng thao tác.
- \(Q\) dòng tiếp theo, mỗi dòng chứa một số nguyên \(val\).
OUTPUT FORMAT:
- Sau mỗi thao tác, in ra độ dài của dãy \(S\) trên một dòng mới.
- Sau tất cả các thao tác, in ra dãy \(S\).
Ràng buộc:
- \(1 \leq N \leq 10^5\)
- \(1 \leq Q \leq 10^5\)
- \(1 \leq val \leq 10^9\)
- Dãy \(S\) ban đầu là một dãy B.
Ví dụ
INPUT
4
1 2 5 2
4
5
1
3
2OUTPUT
4
5
6
6
1 2 3 5 2 1Giải thích
- Thao tác 1: Thêm số 5 vào dãy. Do 5 là phần tử lớn nhất và đã xuất hiện một lần trong dãy, ta không thể thêm. Độ dài dãy = 4.
- Thao tác 2: Thêm số 1 vào dãy. Ta thêm vào phần giảm vì phần tăng đã có số 1. Độ dài dãy = 5.
- Thao tác 3: Thêm số 3 vào phần tăng của dãy. Độ dài dãy = 6.
- Thao tác 4: Không thể thêm số 2 vì số 2 đã xuất hiện hai lần trong dãy. Độ dài dãy = 6.
Dãy cuối cùng: 1 2 3 5 2 1 Tuyệt vời! Đây là hướng dẫn ngắn gọn để giải bài toán "Dãy B" bằng C++, tập trung vào cấu trúc dữ liệu và thuật toán:
Phân tích cấu trúc Dãy B: Dãy B có dạng tăng nghiêm ngặt -> phần tử lớn nhất (đỉnh) -> giảm nghiêm ngặt. Các phần tử (trừ đỉnh) xuất hiện tối đa 2 lần (1 lần ở phần tăng, 1 lần ở phần giảm). Các phần tử ở phần giảm phải đã xuất hiện ở phần tăng.
Chọn Cấu trúc dữ liệu:
- Vì dãy có 2 phần (tăng và giảm) và cần duy trì tính chất thứ tự/giá trị, đồng thời cần kiểm tra và đếm số lần xuất hiện của các phần tử, ta có thể sử dụng các cấu trúc dữ liệu dựa trên cây tìm kiếm nhị phân cân bằng.
- Sử dụng hai
std::multiset<int>: một cho các phần tử ở phần tăng (increasing_elements) và một cho các phần tử ở phần giảm (decreasing_elements). Multiset cho phép lưu trữ các phần tử trùng lặp và duy trì chúng theo thứ tự tăng dần. - Lưu trữ riêng phần tử đỉnh
int peak_val. - Tổng độ dài dãy là
increasing_elements.size() + decreasing_elements.size() + 1(đỉnh).
Khởi tạo:
- Đọc dãy ban đầu
S. Tìm phần tử lớn nhất (đỉnh) và giá trị của nó (peak_val). - Duyệt dãy
S: các phần tử trước đỉnh đưa vàoincreasing_elements, các phần tử sau đỉnh đưa vàodecreasing_elements. Dãy ban đầu đảm bảo là Dãy B hợp lệ.
- Đọc dãy ban đầu
Xử lý thao tác thêm
val:- Kiểm tra điều kiện không hợp lệ:
- Nếu
val == peak_val: không thể thêm (đỉnh chỉ xuất hiện 1 lần). - Tổng số lần xuất hiện của
valhiện tại trong dãy làincreasing_elements.count(val) + decreasing_elements.count(val). Nếu tổng này >= 2, không thể thêmval(các phần tử khác đỉnh xuất hiện tối đa 2 lần).
- Nếu
- Nếu
valcó thể thêm:- Trường hợp 1:
valchưa xuất hiện lần nào (tổng count == 0).valphải được thêm vào phần tăng.- Điều kiện hợp lệ để thêm vào phần tăng:
val < peak_val. - Nếu hợp lệ: thêm
valvàoincreasing_elements(increasing_elements.insert(val)).
- Trường hợp 2:
valđã xuất hiện 1 lần (tổng count == 1).valphải được thêm vào phần giảm.- Điều kiện hợp lệ để thêm vào phần giảm:
valphải đã xuất hiện ở phần tăng. Kiểm tra xemvalcó tồn tại trongincreasing_elementskhông (increasing_elements.count(val) > 0). - Nếu hợp lệ: thêm
valvàodecreasing_elements(decreasing_elements.insert(val)).
- Trường hợp 1:
- Sau khi thêm (nếu hợp lệ): In ra độ dài mới của dãy. Nếu không thêm được, độ dài không đổi.
- Kiểm tra điều kiện không hợp lệ:
In kết quả cuối cùng:
- Sau khi xử lý tất cả các thao tác, in dãy
S. - Duyệt các phần tử trong
increasing_elementsvà in theo thứ tự tăng dần. - In
peak_val. - Duyệt các phần tử trong
decreasing_elementstheo thứ tự giảm dần (sử dụng reverse iterator của multiset) và in ra.
- Sau khi xử lý tất cả các thao tác, in dãy
Lưu ý: Việc sử dụng std::multiset giúp các thao tác kiểm tra sự tồn tại và thêm phần tử có độ phức tạp O(log K) (với K là số phần tử trong multiset), làm cho tổng thời gian xử lý các truy vấn hiệu quả hơn (khoảng O(Q log N)). Việc dựng lại dãy cuối cùng chỉ mất O(N).
Làm thêm nhiều bài tập miễn phí tại đây
Khóa học liên quan
 Giảm giá!
Giảm giá!
Comments