Bài 15.3. Thuật toán Heap Sort và phân tích
Bài 15.3. Thuật toán Heap Sort và phân tích
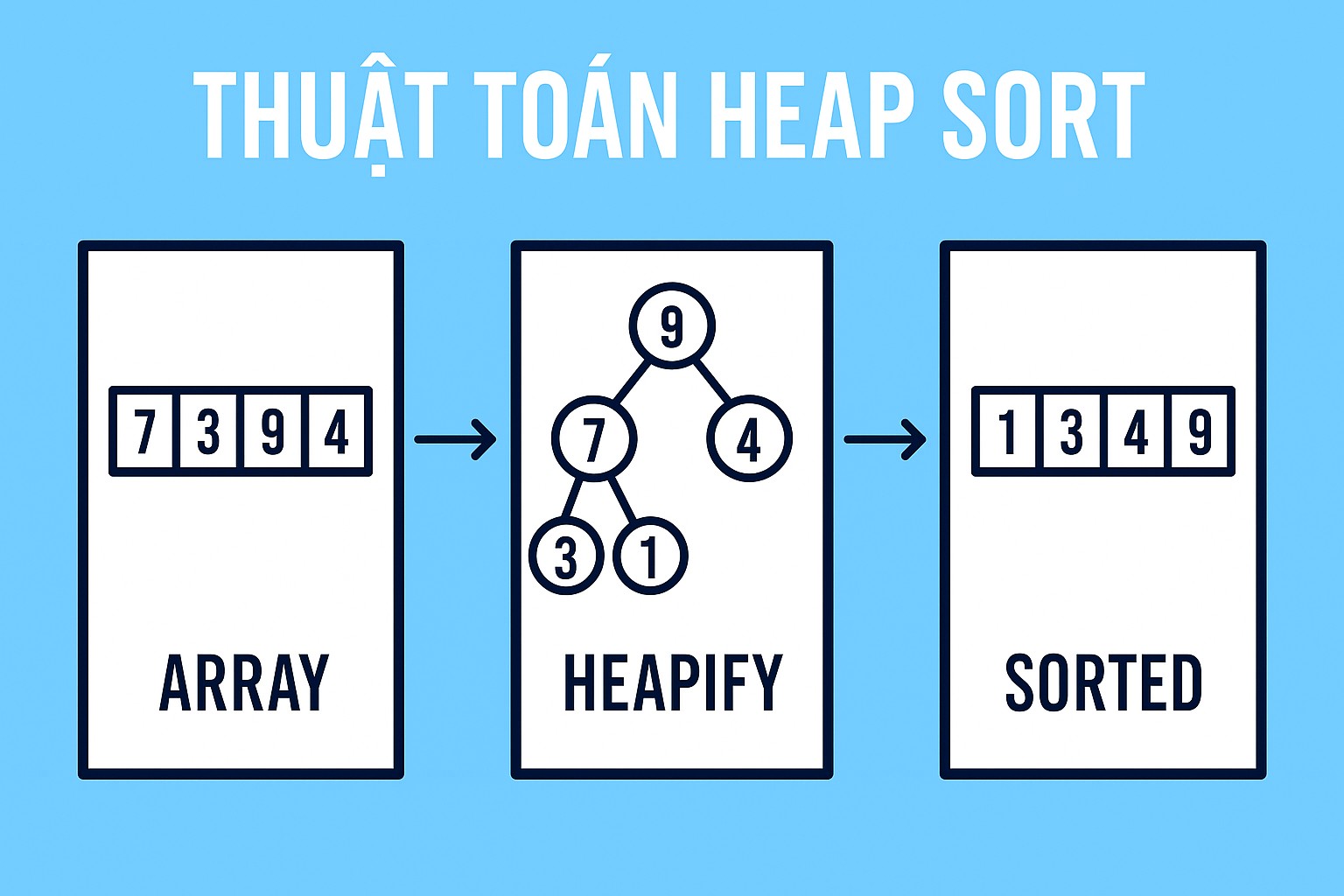
Chào mừng bạn trở lại với series về Cấu trúc dữ liệu và Giải thuật! Hôm nay, chúng ta sẽ khám phá một viên ngọc quý trong thế giới các thuật toán sắp xếp: Heap Sort. Đây là một thuật toán mạnh mẽ, hiệu quả với độ phức tạp thời gian đáng ngưỡng mộ là O(n log n) ngay cả trong trường hợp xấu nhất, và điều tuyệt vời hơn là nó thực hiện sắp xếp tại chỗ (in-place)!
Heap Sort khai thác triệt để sức mạnh của cấu trúc dữ liệu Heap (đống), mà cụ thể ở đây chúng ta sẽ tập trung vào Max-Heap (đống cực đại).
Heap là gì? (Nhắc lại nhanh về Max-Heap)
Trước khi đi sâu vào Heap Sort, hãy nhắc lại một chút về Max-Heap.
Một Heap là một cây nhị phân hoàn chỉnh (hoặc gần hoàn chỉnh) có hai tính chất chính:
- Tính chất cấu trúc (Shape Property): Cây là một cây nhị phân hoàn chỉnh, nghĩa là tất cả các tầng đều đầy đủ ngoại trừ có thể là tầng cuối cùng, và các nút ở tầng cuối cùng được lấp đầy từ trái sang phải. Điều này cho phép chúng ta biểu diễn Heap một cách hiệu quả bằng một mảng (array).
- Tính chất Heap (Heap Property):
- Max-Heap: Giá trị của mỗi nút luôn lớn hơn hoặc bằng giá trị của các nút con của nó. Do đó, phần tử lớn nhất luôn nằm ở gốc (root) của cây (chỉ số 0 trong mảng).
- Min-Heap (chỉ đề cập qua): Giá trị của mỗi nút luôn nhỏ hơn hoặc bằng giá trị của các nút con của nó.
Trong biểu diễn bằng mảng, với nút ở chỉ số i:
- Nút cha (Parent) có chỉ số:
(i - 1) / 2 - Nút con trái (Left Child) có chỉ số:
2 * i + 1 - Nút con phải (Right Child) có chỉ số:
2 * i + 2
Ý Tưởng Cốt Lõi của Heap Sort
Ý tưởng đằng sau Heap Sort khá đơn giản nhưng thiên tài:
- Bước 1: Xây dựng Max-Heap. Chuyển đổi mảng đầu vào thành một Max-Heap. Sau bước này, phần tử lớn nhất trong mảng sẽ nằm ở vị trí đầu tiên (
arr[0]). - Bước 2: Trích xuất phần tử lớn nhất và sắp xếp. Vì phần tử lớn nhất đang ở gốc (vị trí 0), chúng ta sẽ đổi chỗ nó với phần tử cuối cùng của mảng. Bây giờ, phần tử lớn nhất đã nằm đúng vị trí cuối cùng của mảng đã sắp xếp. Sau đó, chúng ta giảm kích thước của Heap đi 1 (không xét phần tử cuối cùng vừa được sắp xếp) và khôi phục lại tính chất Max-Heap cho phần còn lại của mảng bằng cách gọi hàm
heapify(hay còn gọi làsiftDown) trên nút gốc (vị trí 0). Lặp lại bước này cho đến khi kích thước của Heap chỉ còn 1 phần tử.
Kết thúc quá trình, mảng sẽ được sắp xếp theo thứ tự tăng dần.
Thuật Toán Chi Tiết
Heap Sort bao gồm hai giai đoạn chính, sử dụng một hàm phụ trợ quan trọng là heapify.
Hàm heapify (hoặc siftDown)
Đây là trái tim của thuật toán Heap Sort. Hàm này có nhiệm vụ khôi phục lại tính chất Max-Heap cho một cây con cụ thể có gốc tại chỉ số i, giả sử rằng các cây con bên trái và bên phải của i đã là Max-Heap (hoặc không phải là lá).
- Tham số: Mảng
arr, kích thước hiện tại của Heapn, và chỉ số gốc của cây con cầnheapifylài. - Cách hoạt động:
- Tìm phần tử lớn nhất trong ba phần tử: nút gốc hiện tại (
arr[i]), con trái (arr[2*i + 1]), và con phải (arr[2*i + 2]). Cần kiểm tra xem các nút con có nằm trong phạm vi Heap hiện tại (n) hay không. - Nếu phần tử lớn nhất không phải là nút gốc (
arr[i]), thì đổi chỗ phần tử lớn nhất đó vớiarr[i]. - Sau khi đổi chỗ, nút con bị ảnh hưởng (nút mà giá trị lớn nhất ban đầu ở đó) có thể đã vi phạm tính chất Max-Heap. Do đó, chúng ta cần đệ quy hoặc lặp lại quá trình
heapifytrên cây con mới có gốc tại chỉ số của phần tử lớn nhất vừa được đổi chỗ.
- Tìm phần tử lớn nhất trong ba phần tử: nút gốc hiện tại (
Giai đoạn 1: Xây dựng Max-Heap
Chúng ta có một mảng arr gồm n phần tử. Để biến nó thành một Max-Heap, chúng ta có thể bắt đầu từ nút không phải là lá cuối cùng và đi ngược về gốc, gọi hàm heapify cho từng nút.
- Nút không phải là lá cuối cùng nằm ở chỉ số
n/2 - 1. - Chúng ta sẽ lặp từ
i = n/2 - 1xuống đếni = 0, và với mỗii, gọiheapify(arr, n, i).
Tại sao lại bắt đầu từ n/2 - 1 và đi ngược lên? Các nút từ n/2 đến n-1 đều là nút lá. Một cây con chỉ có một nút lá hiển nhiên đã là một Max-Heap (vì không có con để so sánh). Bắt đầu từ nút không phải là lá cuối cùng và đi lên đảm bảo rằng khi chúng ta gọi heapify cho một nút, các cây con của nó (nếu có) đã là Max-Heap.
Giai đoạn 2: Trích xuất phần tử lớn nhất và sắp xếp
Sau khi mảng đã là một Max-Heap, phần tử lớn nhất (arr[0]) là phần tử cần đặt vào vị trí cuối cùng của mảng đã sắp xếp.
- Lặp từ
i = n-1xuống đếni = 1. - Trong mỗi lần lặp:
- Đổi chỗ
arr[0](phần tử lớn nhất hiện tại) vớiarr[i](phần tử cuối cùng của Heap hiện tại). Bây giờ,arr[i]đã nằm đúng vị trí cuối cùng trong mảng sắp xếp của chúng ta. - Giảm kích thước Heap: Coi như Heap chỉ còn
iphần tử (loại bỏ phần tửarr[i]vừa được sắp xếp). - Khôi phục Heap: Gọi
heapify(arr, i, 0)để khôi phục lại tính chất Max-Heap cho Heap mới có kích thướci, bắt đầu từ gốc (chỉ số 0).
- Đổi chỗ
Lặp lại cho đến khi Heap chỉ còn 1 phần tử (khi i bằng 1). Phần tử cuối cùng này (arr[0] sau khi loop kết thúc) hiển nhiên đã đúng vị trí.
Triển khai Heap Sort bằng C++
Hãy cùng xem mã nguồn C++ cho Heap Sort.
#include <iostream> // Dùng cho in/out
#include <vector> // Dùng cho std::vector
#include <algorithm> // Dùng cho std::swap
// Hàm phụ trợ để in mảng
void printArray(const std::vector<int>& arr) {
for (int x : arr) {
std::cout << x << " ";
}
std::cout << std::endl;
}
// Hàm heapify (siftDown)
// arr: mảng
// n: kích thước hiện tại của heap
// i: chỉ số gốc của cây con cần heapify
void heapify(std::vector<int>& arr, int n, int i) {
// Khởi tạo largest là gốc (node i)
int largest = i;
// Chỉ số con trái = 2*i + 1
int left = 2 * i + 1;
// Chỉ số con phải = 2*i + 2
int right = 2 * i + 2;
// Nếu con trái lớn hơn gốc
if (left < n && arr[left] > arr[largest]) {
largest = left;
}
// Nếu con phải lớn hơn phần tử lớn nhất hiện tại (có thể là gốc hoặc con trái)
if (right < n && arr[right] > arr[largest]) {
largest = right;
}
// Nếu phần tử lớn nhất không phải là gốc
if (largest != i) {
// Đổi chỗ gốc với phần tử lớn nhất
std::swap(arr[i], arr[largest]);
// Gọi đệ quy heapify trên cây con bị ảnh hưởng (cây con có gốc mới tại largest)
heapify(arr, n, largest);
}
}
// Hàm chính thực hiện Heap Sort
// arr: mảng cần sắp xếp
void heapSort(std::vector<int>& arr) {
int n = arr.size();
// Giai đoạn 1: Xây dựng Max-Heap từ mảng
// Bắt đầu từ nút không phải là lá cuối cùng và đi ngược về gốc
for (int i = n / 2 - 1; i >= 0; i--) {
heapify(arr, n, i);
}
// Giai đoạn 2: Trích xuất từng phần tử từ heap
// Lặp từ phần tử cuối cùng của mảng về phần tử thứ 2
for (int i = n - 1; i > 0; i--) {
// Đổi chỗ phần tử gốc (lớn nhất) với phần tử cuối cùng của heap hiện tại
std::swap(arr[0], arr[i]);
// Gọi heapify trên heap đã giảm kích thước (kích thước i), bắt đầu từ gốc mới
// arr: mảng
// i: kích thước mới của heap (không bao gồm phần tử vừa đổi chỗ ra cuối mảng)
// 0: chỉ số gốc
heapify(arr, i, 0);
}
}
// Ví dụ minh họa
int main() {
std::vector<int> arr = {12, 11, 13, 5, 6, 7, 1, 50, 2, 9};
std::cout << "Mang ban dau: ";
printArray(arr);
heapSort(arr);
std::cout << "Mang sau khi sap xep (Heap Sort): ";
printArray(arr);
return 0;
}
Giải thích Mã nguồn C++
printArray: Một hàm đơn giản để in nội dung củastd::vector.heapify(std::vector<int>& arr, int n, int i):- Nhận vào mảng
arr, kích thước hiện tại của heapn, và chỉ sốicủa nút gốc cần xử lý. largest = i;: Ban đầu giả định nút gốc (i) là lớn nhất trong cây con.left = 2 * i + 1; right = 2 * i + 2;: Tính chỉ số của con trái và con phải dựa trên chỉ số gốci.- Kiểm tra
if (left < n && arr[left] > arr[largest]): Nếu con trái tồn tại (left < n) và giá trị của nó lớn hơn giá trị hiện tại củalargest, cập nhậtlargestthànhleft. - Kiểm tra
if (right < n && arr[right] > arr[largest]): Tương tự cho con phải. Sau hai lần kiểm tra này,largestsẽ chứa chỉ số của phần tử lớn nhất trong ba nút (gốc, con trái, con phải) trong phạm vi heap hiện tại. if (largest != i): Nếu phần tử lớn nhất không phải là gốc ban đầu (i), nghĩa là cần phải đổi chỗ.std::swap(arr[i], arr[largest]);: Đổi chỗ gốc với phần tử lớn nhất tìm được.heapify(arr, n, largest);: Đây là bước đệ quy quan trọng. Sau khi đổi chỗ, cây con có gốc tại chỉ sốlargest(vị trí mà phần tử gốc ban đầu di chuyển xuống) có thể đã vi phạm tính chất Max-Heap. Do đó, chúng ta phải gọi lạiheapifycho cây con đó để đảm bảo tính chất được giữ vững từ dưới lên.
- Nhận vào mảng
heapSort(std::vector<int>& arr):int n = arr.size();: Lấy kích thước của mảng.- Giai đoạn 1 (Xây dựng Max-Heap):
for (int i = n / 2 - 1; i >= 0; i--): Vòng lặp này duyệt qua tất cả các nút không phải là lá, từ nút cuối cùng (n/2 - 1) đến gốc (0).heapify(arr, n, i);: Gọiheapifycho mỗi nút không phải là lá. Sau khi vòng lặp này kết thúc, toàn bộ mảng đã được biến đổi thành một Max-Heap, với phần tử lớn nhất ởarr[0].
- Giai đoạn 2 (Trích xuất và Sắp xếp):
for (int i = n - 1; i > 0; i--): Vòng lặp này duyệt từ phần tử cuối cùng của mảng (n-1) về đến phần tử thứ hai (1). Biếniở đây đóng vai trò là chỉ số cuối cùng của heap "ảo" đang xét (kích thước heap giảm dần).std::swap(arr[0], arr[i]);: Đổi chỗ phần tử lớn nhất (ở gốcarr[0]) với phần tử cuối cùng của heap hiện tại (arr[i]). Phần tửarr[i]sau khi đổi chỗ sẽ ở đúng vị trí đã sắp xếp của nó.heapify(arr, i, 0);: Gọiheapifytrên phần còn lại của mảng (kích thướci) để khôi phục tính chất Max-Heap cho gốc mới (arr[0]). Lưu ý rằng chúng ta truyềnilàm kích thước heap, chỉ ra rằng phần tửarr[i]trở đi đã được sắp xếp và không còn nằm trong heap nữa.
- Khi vòng lặp kết thúc (
ivề đến 0), tất cả các phần tử (trừ phần tử đầu tiên còn lại, vốn hiển nhiên đã đúng vị trí sau khi các phần tử lớn hơn nó đã được đưa ra sau) đều đã được đặt vào đúng vị trí của chúng, và mảng đã được sắp xếp hoàn chỉnh.
Phân tích Độ phức tạp
Heap Sort có hiệu suất rất ấn tượng, đặc biệt là trong trường hợp xấu nhất.
Độ phức tạp thời gian (Time Complexity):
- Giai đoạn 1 (Xây dựng Max-Heap): Việc xây dựng một heap từ một mảng có
nphần tử có thể được thực hiện trong thời gian O(n). Ban đầu có vẻ khó tin vìheapifycó độ phức tạpO(log n), nhưng khi xem xét tổng công việc của các lần gọiheapifytrên các nút ở các tầng khác nhau, tổng chi phí là tuyến tính. - Giai đoạn 2 (Trích xuất và Sắp xếp): Giai đoạn này lặp lại
n-1lần. Mỗi lần lặp bao gồm một thao tác đổi chỗO(1)và một lần gọiheapifytrên một heap có kích thước giảm dần (tối đa làn). Một lần gọiheapifymất thời gian O(log k), trong đóklà kích thước của heap hiện tại. Tổng cộng cho giai đoạn này là O(n log n) (ví dụ:n * O(log n)). - Tổng cộng: Độ phức tạp thời gian của Heap Sort là O(n) + O(n log n) = O(n log n).
- Điều đáng chú ý là Heap Sort có độ phức tạp O(n log n) trong tất cả các trường hợp (tốt nhất, trung bình, xấu nhất), không giống như Quick Sort có thể xuống O(n²) trong trường hợp xấu nhất.
- Giai đoạn 1 (Xây dựng Max-Heap): Việc xây dựng một heap từ một mảng có
Độ phức tạp không gian (Space Complexity):
- Heap Sort thực hiện sắp xếp tại chỗ (in-place). Nó chỉ cần một vài biến phụ trợ để lưu trữ chỉ số và giá trị khi đổi chỗ.
- Độ phức tạp không gian phụ trợ là O(1).
Ưu điểm và Nhược điểm
Ưu điểm:
- Hiệu quả: Độ phức tạp thời gian O(n log n) đảm bảo hiệu suất tốt ngay cả với dữ liệu lớn và trong trường hợp xấu nhất.
- Tại chỗ (In-place): Chỉ cần không gian bộ nhớ bổ sung cố định O(1), rất hiệu quả về mặt bộ nhớ.
- Không đệ quy sâu: Không như Quick Sort có thể gặp vấn đề với stack overflow trong trường hợp xấu nhất nếu không triển khai cẩn thận, Heap Sort có thể triển khai với
heapifyđệ quy (stack depth O(log n)) hoặc thậm chí lặp (O(1) stack space).
Nhược điểm:
- Không ổn định (Not Stable): Thứ tự tương đối của các phần tử có giá trị bằng nhau không được bảo toàn.
- Hiệu suất thực tế: Mặc dù có độ phức tạp lý thuyết tốt, trong thực tế, Heap Sort thường chậm hơn Quick Sort và Merge Sort một chút do cách truy cập dữ liệu (không liên tục/cache-friendly như các thuật toán khác).
Ví dụ Minh họa Chi tiết từng Bước
Hãy xem xét mảng [12, 11, 13, 5, 6, 7] và áp dụng Heap Sort.
Mảng ban đầu: [12, 11, 13, 5, 6, 7] (n = 6)
Giai đoạn 1: Xây dựng Max-Heap
Last non-leaf node index: n/2 - 1 = 6/2 - 1 = 2. Ta sẽ gọi heapify cho các chỉ số 2, 1, 0.
i = 2:heapify(arr, 6, 2). Cây con gốc 13:[13, 6, 7](tại các chỉ số 2, 5, 6 - chỉ số 6 không tồn tại trong heap kích thước 6, chỉ có con trái 6 tại chỉ số 5). Cây con là[13, 6, 7](giá trị tại index 2, 22+1=5, 22+2=6). Values:arr[2]=13,arr[5]=7. Index 6 is out of bounds (n=6). The subtree is rooted at index 2, children at 5. Values:arr[2]=13,arr[5]=7. Wait, I made a mistake in index calculation earlier. Let's trace correctly using indices:i=2,left=5,right=6.rightis out of bounds (>= n=6). Comparearr[2](13) andarr[5](7).13is larger. No swap needed. Array remains:[12, 11, 13, 5, 6, 7].i = 1:heapify(arr, 6, 1). Cây con gốc 11: children tại2*1+1=3,2*1+2=4. Values:arr[1]=11,arr[3]=5,arr[4]=6. Comparearr[1](11),arr[3](5),arr[4](6).11is largest. No swap needed. Array remains:[12, 11, 13, 5, 6, 7].i = 0:heapify(arr, 6, 0). Cây con gốc 12: children tại2*0+1=1,2*0+2=2. Values:arr[0]=12,arr[1]=11,arr[2]=13. Comparearr[0](12),arr[1](11),arr[2](13). Largest is13at index 2. Swaparr[0](12) andarr[2](13). Array becomes:[13, 11, 12, 5, 6, 7]. Now, need to heapify subtree at index 2 (where 12 moved).heapify(arr, 6, 2). Subtree gốc 12: children tại2*2+1=5,2*2+2=6. Values:arr[2]=12,arr[5]=7. Index 6 is out of bounds. Comparearr[2](12) andarr[5](7).12is largest. No swap needed.
Max-Heap được xây dựng hoàn thành: [13, 11, 12, 5, 6, 7]
Giai đoạn 2: Trích xuất phần tử và sắp xếp
Loop i từ n-1 = 5 xuống 1.
i = 5:- Heap size = 6. Đổi chỗ
arr[0](13) vàarr[5](7). Mảng:[7, 11, 12, 5, 6, 13]. - Phần tử 13 đã ở đúng vị trí cuối cùng. Heap hiện tại là
[7, 11, 12, 5, 6](kích thước 5). heapify(arr, 5, 0). Gốc 7. Children tại 1 (11), 2 (12). Largest là 12 tại index 2. Swaparr[0](7) vàarr[2](12). Mảng:[12, 11, 7, 5, 6, 13].heapify(arr, 5, 2)(gốc 7). Children tại 5 (6). Index 6 out of bounds. Comparearr[2](7) vàarr[5](6).arr[5]is OUT of current heap boundary (n=5), so only comparearr[2](7) with its valid child. Child indices of 2 are 5, 6. Only index 5 (value 6) is within n=5. Comparearr[2](7) andarr[5](6). 7 is larger. No swap needed.- Heap:
[12, 11, 7, 5, 6]. Sorted:[13]. Mảng:[12, 11, 7, 5, 6, 13].
- Heap size = 6. Đổi chỗ
i = 4:- Heap size = 5. Đổi chỗ
arr[0](12) vàarr[4](6). Mảng:[6, 11, 7, 5, 12, 13]. - Phần tử 12 đã ở đúng vị trí. Heap hiện tại là
[6, 11, 7, 5](kích thước 4). heapify(arr, 4, 0). Gốc 6. Children tại 1 (11), 2 (7). Largest là 11 tại index 1. Swaparr[0](6) vàarr[1](11). Mảng:[11, 6, 7, 5, 12, 13].heapify(arr, 4, 1)(gốc 6). Children tại 3 (5), 4 (index 4 is OUT of heap size 4). Comparearr[1](6) vàarr[3](5). 6 is larger. No swap needed.- Heap:
[11, 6, 7, 5]. Sorted:[12, 13]. Mảng:[11, 6, 7, 5, 12, 13].
- Heap size = 5. Đổi chỗ
i = 3:- Heap size = 4. Đổi chỗ
arr[0](11) vàarr[3](5). Mảng:[5, 6, 7, 11, 12, 13]. - Phần tử 11 đã ở đúng vị trí. Heap hiện tại là
[5, 6, 7](kích thước 3). heapify(arr, 3, 0). Gốc 5. Children tại 1 (6), 2 (7). Largest là 7 tại index 2. Swaparr[0](5) vàarr[2](7). Mảng:[7, 6, 5, 11, 12, 13].heapify(arr, 3, 2)(gốc 5). Children tại 5 (out of bounds). No children to compare. No swap.- Heap:
[7, 6, 5]. Sorted:[11, 12, 13]. Mảng:[7, 6, 5, 11, 12, 13].
- Heap size = 4. Đổi chỗ
i = 2:- Heap size = 3. Đổi chỗ
arr[0](7) vàarr[2](5). Mảng:[5, 6, 7, 11, 12, 13]. - Phần tử 7 đã ở đúng vị trí. Heap hiện tại là
[5, 6](kích thước 2). heapify(arr, 2, 0). Gốc 5. Children tại 1 (6). Index 2 out of bounds. Comparearr[0](5) vàarr[1](6). Largest là 6 tại index 1. Swaparr[0](5) vàarr[1](6). Mảng:[6, 5, 7, 11, 12, 13].heapify(arr, 2, 1)(gốc 5). Children tại 3 (out of bounds). No children to compare. No swap.- Heap:
[6, 5]. Sorted:[7, 11, 12, 13]. Mảng:[6, 5, 7, 11, 12, 13].
- Heap size = 3. Đổi chỗ
i = 1:- Heap size = 2. Đổi chỗ
arr[0](6) vàarr[1](5). Mảng:[5, 6, 7, 11, 12, 13]. - Phần tử 6 đã ở đúng vị trí. Heap hiện tại là
[5](kích thước 1). heapify(arr, 1, 0). Gốc 5. Children tại 1 (out of bounds). No children to compare. No swap.- Heap:
[5]. Sorted:[6, 7, 11, 12, 13]. Mảng:[5, 6, 7, 11, 12, 13].
- Heap size = 2. Đổi chỗ
Vòng lặp kết thúc khi i đến 1. Mảng cuối cùng là [5, 6, 7, 11, 12, 13], đã được sắp xếp!
Bài tập ví dụ:
Các truy vấn khác nhau
Trong một buổi thảo luận về thuật toán, FullHouse Dev đã được đưa ra một bài toán thú vị liên quan đến mảng và các truy vấn. Với niềm đam mê toán học và lập trình, nhóm đã bắt tay vào phân tích và giải quyết vấn đề này.
Bài toán
FullHouse Dev được cung cấp một mảng \(A\) có kích thước \(N\). Họ phải thực hiện \(Q\) truy vấn trên mảng này. Mỗi truy vấn thuộc một trong hai loại sau:
- \(1\ L\ R\ X\): Cộng \(X\) vào tất cả các phần tử trong đoạn từ \(L\) đến \(R\).
- \(2\ L\ R\ X\): Đặt giá trị của tất cả các phần tử trong đoạn từ \(L\) đến \(R\) thành \(X\).
Tuy nhiên, không bắt buộc phải thực hiện các truy vấn theo thứ tự. Nhiệm vụ của FullHouse Dev là xác định mảng lớn nhất theo thứ tự từ điển có thể đạt được bằng cách thực hiện tất cả \(Q\) truy vấn.
Lưu ý:
- Các truy vấn không thể bị thay đổi hoặc bỏ qua. Chỉ có thể thay đổi thứ tự thực hiện chúng.
- Nếu tồn tại một chỉ số \(i\) sao cho \(A[i] > B[i]\) và \(A[j] = B[j]\) với mọi \(j < i\), thì mảng \(A\) được coi là lớn hơn mảng \(B\) theo thứ tự từ điển.
INPUT FORMAT:
- Dòng đầu tiên: Hai số nguyên \(N\) và \(Q\) cách nhau bởi dấu cách.
- Dòng thứ hai: \(N\) số nguyên cách nhau bởi dấu cách biểu diễn mảng \(A\).
- \(Q\) dòng tiếp theo: Mỗi dòng chứa một truy vấn theo định dạng \(1\ L\ R\ X\) hoặc \(2\ L\ R\ X\).
OUTPUT FORMAT:
- In ra \(N\) số nguyên cách nhau bởi dấu cách biểu diễn mảng lớn nhất theo thứ tự từ điển có thể đạt được.
Ràng buộc:
- \(1 \leq N \leq 10^5\)
- \(1 \leq Q \leq 10^5\)
- \(1 \leq L \leq R \leq N\)
- \(-10^9 \leq A[i], X \leq 10^9\)
Ví dụ
INPUT
5 3
1 2 3 4 5
1 3 4 2
2 1 2 3
1 4 5 -6OUTPUT
3 3 5 0 -1Giải thích
Trong trường hợp này, thứ tự thực hiện các truy vấn không ảnh hưởng đến kết quả cuối cùng. Giả sử các truy vấn được thực hiện theo thứ tự trong input, mảng sau mỗi truy vấn sẽ như sau:
- Ban đầu: \([1, 2, 3, 4, 5]\)
- Sau truy vấn 1: \([1, 2, 5, 6, 5]\)
- Sau truy vấn 2: \([3, 3, 5, 6, 5]\)
- Sau truy vấn 3: \([3, 3, 5, 0, -1]\)
Lưu ý rằng mảng cuối cùng sẽ giống nhau ngay cả khi các truy vấn được thực hiện theo một thứ tự khác.
#include <iostream>
#include <vector>
#include <tuple>
#include <set>
#include <algorithm>
int main() {
std::ios_base::sync_with_stdio(false);
std::cin.tie(NULL);
int n, q;
std::cin >> n >> q;
std::vector<long long> initial_array(n);
for (int i = 0; i < n; ++i) {
std::cin >> initial_array[i];
}
std::vector<std::tuple<int, int, int, long long>> queries(q);
for (int i = 0; i < q; ++i) {
std::cin >> std::get<0>(queries[i]) >> std::get<1>(queries[i]) >> std::get<2>(queries[i]) >> std::get<3>(queries[i]);
// Adjust L and R to be 0-based indices
std::get<1>(queries[i])--;
std::get<2>(queries[i])--;
}
std::vector<long long> final_result(n);
std::vector<long long> add_effect(n, 0);
std::set<int> active_indices; // Stores indices whose base value hasn't been fixed by a Set yet
for (int i = 0; i < n; ++i) {
active_indices.insert(i);
}
// Process queries in reverse order
for (int j = q - 1; j >= 0; --j) {
int type = std::get<0>(queries[j]);
int l = std::get<1>(queries[j]);
int r = std::get<2>(queries[j]);
long long x = std::get<3>(queries[j]);
auto it = active_indices.lower_bound(l);
std::vector<int> indices_to_remove;
// Iterate through active indices in the range [l, r]
while (it != active_indices.end() && *it <= r) {
int current_idx = *it;
if (type == 2) { // Set query
// This Set query is the latest one (in original input order) encountered
// so far in reverse pass for this index that hasn't been overwritten.
// It determines the base value.
final_result[current_idx] = x;
indices_to_remove.push_back(current_idx);
} else { // Add query
// This Add query applies to the value determined by the latest Set (or initial)
// that will be encountered later in the reverse pass (earlier in original input).
// So, accumulate this addition.
add_effect[current_idx] += x;
}
++it;
}
// Remove indices that were finalized by a Set query in this pass
for (int idx : indices_to_remove) {
active_indices.erase(idx);
}
}
// Combine initial values/Set base values with accumulated Add effects
for (int i = 0; i < n; ++i) {
if (active_indices.count(i)) {
// Index was never finalized by a Set query. Base value is initial.
final_result[i] = initial_array[i] + add_effect[i];
} else {
// Index was finalized by a Set. final_result[i] already holds the base value.
// Add the accumulated effects from Add queries that happened after the latest Set.
final_result[i] += add_effect[i];
}
}
// Print the result
for (int i = 0; i < n; ++i) {
std::cout << final_result[i] << (i == n - 1 ? "" : " ");
}
std::cout << std::endl;
return 0;
}
Làm thêm nhiều bài tập miễn phí tại đây
Khóa học liên quan
 Giảm giá!
Giảm giá!
Comments