Bài 13.4. Thuật toán Radix Sort và các trường hợp sử dụng
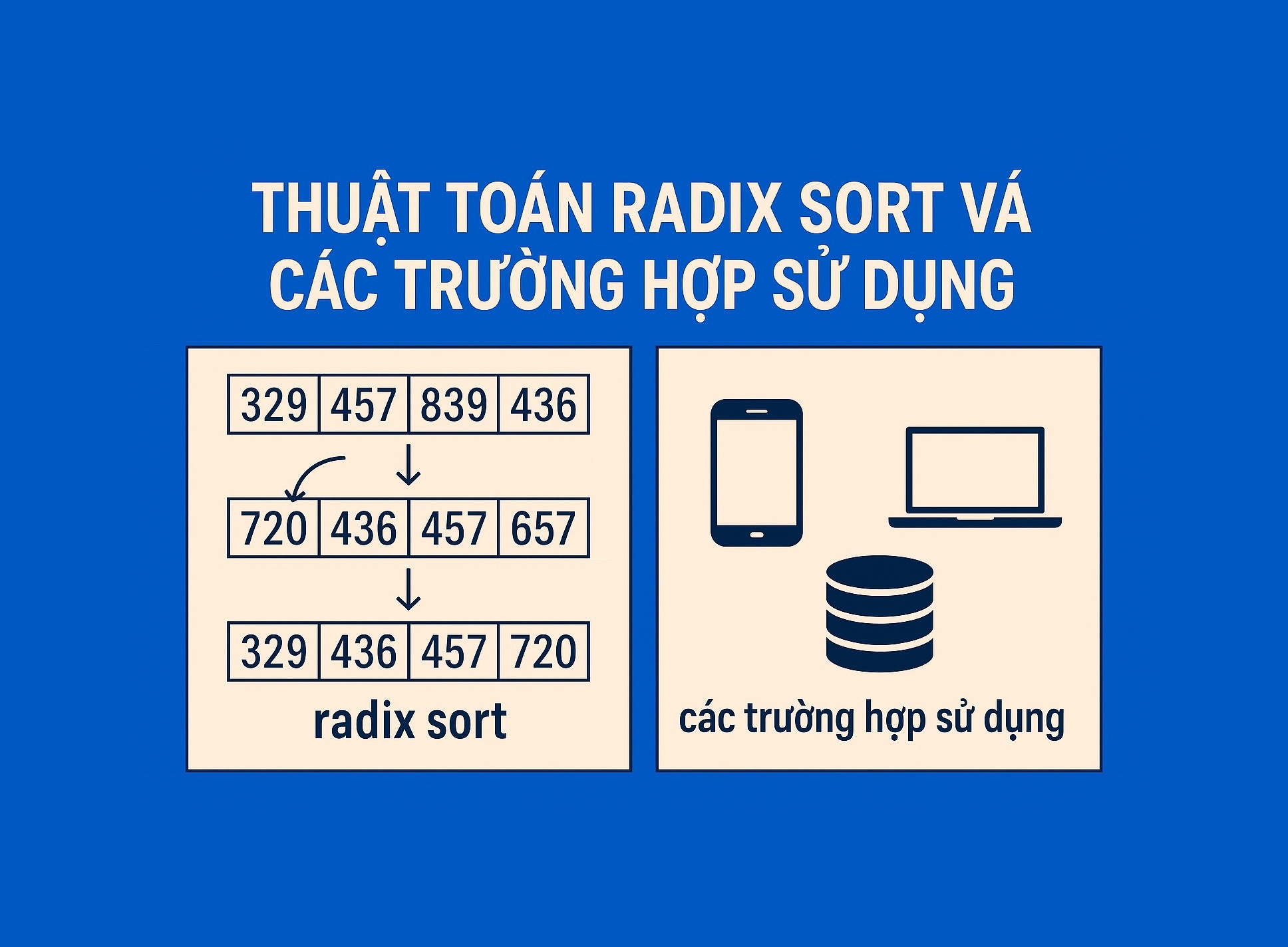
Bài 13.4. Thuật toán Radix Sort và các trường hợp sử dụng
Trong thế giới muôn màu của các thuật toán sắp xếp (sorting algorithms), chúng ta đã làm quen với nhiều "ngôi sao" như QuickSort, MergeSort hay HeapSort. Đây đều là các thuật toán sắp xếp dựa trên phép so sánh (comparison-based sort), với giới hạn lý thuyết tốt nhất là $O(n \log n)$.
Tuy nhiên, có một họ thuật toán đặc biệt không dựa vào việc so sánh trực tiếp các phần tử với nhau. Chúng tận dụng cấu trúc hoặc giá trị của chính các phần tử để xác định vị trí của chúng. Radix Sort chính là một thành viên nổi bật của họ này – một thuật toán phi so sánh (non-comparison sort) có thể đạt được hiệu suất tuyến tính $O(n)$ trong những điều kiện lý tưởng!
Vậy Radix Sort hoạt động như thế nào? Khi nào nó là lựa chọn tối ưu? Hãy cùng khám phá!
Radix Sort là gì? Ý tưởng cốt lõi
Thay vì so sánh hai số $A$ và $B$ để xem $A > B$ hay $A < B$, Radix Sort hoạt động bằng cách xử lý các phần tử từng chữ số một (digit by digit) hoặc từng phần cấu thành một (component by component), bắt đầu từ chữ số ít quan trọng nhất (Least Significant Digit - LSD) hoặc chữ số quan trọng nhất (Most Significant Digit - MSD).
Ý tưởng chính là:
- Xác định "chữ số": Chia các phần tử (thường là số nguyên) thành các "chữ số" dựa trên một hệ cơ số (radix), thường là hệ cơ số 10.
- Sắp xếp ổn định theo từng chữ số: Thực hiện sắp xếp mảng dựa trên giá trị của chữ số hiện tại. Điểm mấu chốt ở đây là thuật toán sắp xếp con được sử dụng phải là một thuật toán ổn định (stable sort). Thuật toán ổn định là thuật toán giữ nguyên thứ tự tương đối của các phần tử có giá trị bằng nhau.
- Lặp lại: Lặp lại quá trình sắp xếp ổn định cho tất cả các chữ số, từ chữ số ít quan trọng nhất đến chữ số quan trọng nhất (hoặc ngược lại, tùy biến thể).
Sau khi sắp xếp theo chữ số cuối cùng (hoặc đầu tiên, tùy biến thể), toàn bộ mảng sẽ được sắp xếp hoàn chỉnh.
Biến thể phổ biến và dễ hiểu nhất là LSD Radix Sort (sắp xếp từ chữ số ít quan trọng nhất). Chúng ta sẽ tập trung vào biến thể này.
Cơ chế hoạt động của LSD Radix Sort
Giả sử chúng ta có một mảng các số nguyên dương và muốn sắp xếp chúng theo thứ tự tăng dần. LSD Radix Sort sẽ thực hiện các bước sau:
- Tìm số lớn nhất: Xác định số lớn nhất trong mảng để biết số lượng chữ số tối đa cần xử lý.
- Lặp qua các chữ số: Lặp lại quy trình sắp xếp ổn định cho từng vị trí chữ số: hàng đơn vị, hàng chục, hàng trăm, v.v., cho đến chữ số của số lớn nhất.
- Sắp xếp ổn định theo chữ số: Ở mỗi lần lặp cho một vị trí chữ số cụ thể, sử dụng một thuật toán sắp xếp ổn định (thường là Counting Sort) để sắp xếp toàn bộ mảng chỉ dựa trên giá trị của chữ số tại vị trí đó.
Ví dụ minh họa (với hệ cơ số 10):
Giả sử mảng ban đầu là: [170, 45, 75, 90, 802, 24, 2, 66]
Lần 1: Sắp xếp theo chữ số hàng đơn vị (exp = 1)
- Các chữ số hàng đơn vị là: [0, 5, 5, 0, 2, 4, 2, 6]
- Sắp xếp ổn định theo các chữ số này, ta được:
[17**0**, 9**0**, 80**2**, **2**, 2**4**, 4**5**, 7**5**, 6**6**]->[170, 90, 802, 2, 24, 45, 75, 66](Lưu ý: 170 và 90 đều có chữ số hàng đơn vị là 0, thứ tự ban đầu 170 trước 90 được giữ nguyên. Tương tự với 802 và 2, hay 45 và 75).
Lần 2: Sắp xếp theo chữ số hàng chục (exp = 10)
- Mảng hiện tại:
[170, 90, 802, 2, 24, 45, 75, 66] - Các chữ số hàng chục là: [7, 9, 0, 0, 2, 4, 7, 6] (lấy
(số / 10) % 10) - Sắp xếp ổn định theo các chữ số này, ta được:
[802, **2**, 2**4**, **4**5, **6**6, 1**7**0, **7**5, **9**0]->[802, 2, 24, 45, 66, 170, 75, 90](Lưu ý: 802 và 2 đều có chữ số hàng chục là 0, thứ tự 802 trước 2 được giữ nguyên).
- Mảng hiện tại:
Lần 3: Sắp xếp theo chữ số hàng trăm (exp = 100)
- Mảng hiện tại:
[802, 2, 24, 45, 66, 170, 75, 90] - Các chữ số hàng trăm là: [8, 0, 0, 0, 0, 1, 0, 0] (lấy
(số / 100) % 10) - Sắp xếp ổn định theo các chữ số này, ta được:
[**2**, **2**4, **4**5, **6**6, **7**5, **9**0, **1**70, **8**02]->[2, 24, 45, 66, 75, 90, 170, 802]
- Mảng hiện tại:
Mảng đã được sắp xếp hoàn chỉnh!
Thuật toán sắp xếp ổn định: Counting Sort
Như đã nói, điểm sống còn của Radix Sort là sử dụng một thuật toán sắp xếp ổn định làm thuật toán con. Counting Sort là lựa chọn tuyệt vời cho vai trò này, đặc biệt khi chúng ta chỉ cần sắp xếp các giá trị trong một phạm vi nhỏ và biết trước phạm vi đó (ví dụ: các chữ số từ 0 đến 9).
Counting Sort hoạt động như sau:
- Đếm số lần xuất hiện: Tạo một mảng đếm (
count) để lưu số lần xuất hiện của mỗi giá trị (chữ số) trong mảng đầu vào. Kích thước mảngcountbằng phạm vi giá trị (ví dụ: 10 cho chữ số 0-9). - Tính tổng tích lũy: Thay đổi mảng
countsao chocount[i]chứa vị trí thực tế của phần tử có giá trịitrong mảng đầu ra. Tức là,count[i]sẽ chứa tổng số phần tử nhỏ hơn hoặc bằngi. - Xây dựng mảng đầu ra: Duyệt mảng đầu vào từ phải sang trái. Với mỗi phần tử, tìm vị trí của nó trong mảng đầu ra bằng cách sử dụng mảng
count(giảm giá trị trongcountsau khi sử dụng). Duyệt từ phải sang trái đảm bảo tính ổn định.
Áp dụng Counting Sort cho một chữ số:
Để sắp xếp mảng arr theo chữ số tại vị trí exp (ví dụ: exp=1 cho hàng đơn vị, exp=10 cho hàng chục, v.v.), chúng ta sẽ sử dụng (arr[i] / exp) % 10 để lấy giá trị của chữ số đó.
Code C++ minh họa
Hãy cùng triển khai Radix Sort sử dụng Counting Sort bằng C++.
Đầu tiên, chúng ta cần một hàm phụ trợ để tìm số lớn nhất trong mảng, giúp xác định số lần lặp (số chữ số tối đa).
#include <iostream>
#include <vector>
#include <algorithm>
// Hàm tìm giá trị lớn nhất trong mảng
int getMax(const std::vector<int>& arr) {
int max_val = arr[0];
for (size_t i = 1; i < arr.size(); ++i) {
if (arr[i] > max_val) {
max_val = arr[i];
}
}
return max_val;
}
// Hàm sắp xếp con sử dụng Counting Sort
// Sắp xếp arr theo chữ số được biểu thị bởi exp.
// exp là 10^i, với i là chỉ số chữ số (0 cho đơn vị, 1 cho chục, ...)
void countingSort(std::vector<int>& arr, int exp) {
int n = arr.size();
std::vector<int> output(n); // Mảng đầu ra
std::vector<int> count(10, 0); // Mảng đếm cho các chữ số 0-9
// 1. Đếm số lần xuất hiện của các chữ số tại vị trí exp
for (int i = 0; i < n; ++i) {
// Lấy chữ số tại vị trí exp: (số / exp) % 10
count[(arr[i] / exp) % 10]++;
}
// 2. Thay đổi count[i] để count[i] chứa vị trí thực tế của chữ số này trong mảng output
for (int i = 1; i < 10; ++i) {
count[i] += count[i - 1];
}
// 3. Xây dựng mảng output
// Duyệt mảng gốc từ phải sang trái để đảm bảo tính ổn định
for (int i = n - 1; i >= 0; --i) {
// Lấy chữ số tại vị trí exp của arr[i]
int digit = (arr[i] / exp) % 10;
// count[digit] hiện đang lưu vị trí cuối cùng của các số có chữ số 'digit'
// trong mảng output. Vì duyệt từ phải sang trái, chúng ta đặt phần tử
// hiện tại vào vị trí count[digit] - 1 và sau đó giảm count[digit]
output[count[digit] - 1] = arr[i];
count[digit]--;
}
// Sao chép các phần tử từ output trở lại arr
for (int i = 0; i < n; ++i) {
arr[i] = output[i];
}
}
// Hàm chính Radix Sort
// Sắp xếp arr có kích thước n sử dụng Radix Sort
void radixSort(std::vector<int>& arr) {
// Tìm số lớn nhất để biết số lượng chữ số
int max_val = getMax(arr);
// Thực hiện counting sort cho từng chữ số.
// exp là 10^i (1, 10, 100, ...).
// Lặp cho đến khi exp lớn hơn số lớn nhất (đã xử lý hết các chữ số)
for (int exp = 1; max_val / exp > 0; exp *= 10) {
countingSort(arr, exp);
}
}
// Hàm tiện ích để in mảng
void printArray(const std::vector<int>& arr) {
for (int x : arr) {
std::cout << x << " ";
}
std::cout << std::endl;
}
// Chương trình chính để kiểm thử Radix Sort
int main() {
std::vector<int> arr = {170, 45, 75, 90, 802, 24, 2, 66};
int n = arr.size();
std::cout << "Mang ban dau: ";
printArray(arr);
radixSort(arr);
std::cout << "Mang sau khi sap xep: ";
printArray(arr);
std::vector<int> arr2 = {1, 999, 50, 5, 234, 87, 1234, 9, 72};
std::cout << "\nMang ban dau 2: ";
printArray(arr2);
radixSort(arr2);
std::cout << "Mang sau khi sap xep 2: ";
printArray(arr2);
std::vector<int> arr3 = {329, 457, 657, 839, 436, 720, 355};
std::cout << "\nMang ban dau 3: ";
printArray(arr3);
radixSort(arr3);
std::cout << "Mang sau khi sap xep 3: ";
printArray(arr3);
return 0;
}
Giải thích Code C++
getMax(const std::vector<int>& arr): Hàm đơn giản này duyệt qua mảng để tìm giá trị lớn nhất. Mục đích là để xác định số chữ số tối đa mà chúng ta cần xử lý.countingSort(std::vector<int>& arr, int exp): Đây là trái tim của Radix Sort. Hàm này nhận mảngarrvàexp(viết tắt của exponent) làm tham số.expcó giá trị là $10^0, 10^1, 10^2, \dots$ tương ứng với việc chúng ta đang sắp xếp theo chữ số hàng đơn vị, hàng chục, hàng trăm, v.v.outputvàcountlà hai vector tạm thời.outputlưu trữ mảng đã được sắp xếp sau bước hiện tại, còncountdùng để đếm số lần xuất hiện của mỗi chữ số (0-9).count[(arr[i] / exp) % 10]++: Đây là cách lấy giá trị của chữ số tại vị tríexp. Ví dụ:- Nếu
arr[i] = 170vàexp = 1:(170 / 1) % 10 = 170 % 10 = 0. Chữ số hàng đơn vị là 0. - Nếu
arr[i] = 170vàexp = 10:(170 / 10) % 10 = 17 % 10 = 7. Chữ số hàng chục là 7. - Nếu
arr[i] = 170vàexp = 100:(170 / 100) % 10 = 1 % 10 = 1. Chữ số hàng trăm là 1.
- Nếu
- Vòng lặp thứ hai biến
countthành mảng tổng tích lũy.count[i]sẽ chứa tổng số phần tử có chữ số nhỏ hơn hoặc bằngitại vị tríexp. Điều này giúp xác định vị trí cuối cùng của mỗi số trong mảng đầu ra. - Vòng lặp quan trọng
for (int i = n - 1; i >= 0; --i)duyệt mảng gốc từ phải sang trái. Đối với mỗi phần tửarr[i], nó lấy chữ số tương ứng, tìm vị trí trong mảngoutputdựa vàocountvà đặtarr[i]vào đó. Sau đó, nó giảmcountđể chuẩn bị cho phần tử tiếp theo có cùng chữ số. Duyệt ngược và giảmcountlà chìa khóa để giữ tính ổn định. - Cuối cùng, mảng
outputđược sao chép trở lạiarr.
radixSort(std::vector<int>& arr): Hàm này điều phối toàn bộ quá trình. Nó gọigetMaxđể biết số lần cần lặp. Vòng lặpfor (int exp = 1; max_val / exp > 0; exp *= 10)sẽ lần lượt gọicountingSortchoexp = 1(đơn vị),exp = 10(chục),exp = 100(trăm), v.v., cho đến khiexpvượt quá giá trị của số lớn nhất (nghĩa là đã xử lý hết các chữ số).printArrayvàmain: Các hàm tiện ích và hàm chính để minh họa cách sử dụng. Chúng tạo ra các mảng thử nghiệm, gọiradixSortvà in kết quả.
Độ phức tạp của Radix Sort
Độ phức tạp thời gian:
- Hàm
getMax: $O(n)$, với $n$ là số lượng phần tử. - Hàm
countingSort: $O(n + k)$, với $n$ là số lượng phần tử và $k$ là phạm vi giá trị của các chữ số (thường là 10 cho hệ cơ số 10). - Hàm
radixSort: Lặp lạicountingSort$d$ lần, với $d$ là số lượng chữ số tối đa của các phần tử. Số lượng chữ số $d$ của một số $M$ trong hệ cơ số $b$ là khoảng $log_b(M)$. - Tổng cộng, độ phức tạp thời gian của Radix Sort là $O(d * (n + k))$.
- Nếu chúng ta xem $k$ (phạm vi chữ số) là hằng số (ví dụ: 10), và $d$ (số chữ số) là nhỏ và cũng có thể xem là hằng số (hoặc tăng rất chậm so với $n$, ví dụ khi giới hạn giá trị tối đa của số), thì Radix Sort có thể đạt hiệu suất $O(n)$.
- Trong trường hợp tổng quát với số nguyên 32-bit, số chữ số trong hệ cơ số 10 là khoảng 10. Với hệ cơ số 2 (bit), số chữ số là 32. Nếu dùng hệ cơ số $2^m$, số chữ số là $32/m$. Nếu chọn $m$ sao cho $2^m \approx n$, thì $d \approx 32/log_2(n)$ và $k \approx n$, độ phức tạp là $O((32/log_2(n)) (n+n)) = O(n 64 / log_2(n))$, vẫn tốt hơn $O(n \log n)$. Tuy nhiên, cách phân tích phổ biến nhất là $O(d \cdot (n+k))$.
- Hàm
Độ phức tạp không gian:
countingSortcần một mảngoutputkích thước $n$ và một mảngcountkích thước $k$.- Tổng cộng, độ phức tạp không gian là $O(n + k)$.
Ưu điểm và Nhược điểm của Radix Sort
Ưu điểm:
- Hiệu suất cao: Có thể đạt hiệu suất tuyến tính $O(n)$ trong điều kiện lý tưởng (khi số chữ số $d$ và phạm vi chữ số $k$ nhỏ hoặc hằng số). Điều này có thể nhanh hơn đáng kể so với các thuật toán so sánh $O(n \log n)$ cho các tập dữ liệu lớn.
- Không dựa trên so sánh: Tận dụng cấu trúc dữ liệu thay vì so sánh trực tiếp, mở ra khả năng xử lý các loại dữ liệu khác ngoài số nguyên.
- Ổn định: Biến thể LSD Radix Sort sử dụng thuật toán con ổn định nên Radix Sort cũng là một thuật toán sắp xếp ổn định.
Nhược điểm:
- Yêu cầu dữ liệu: Hoạt động tốt nhất trên các dữ liệu có thể được biểu diễn dưới dạng "chữ số" hoặc "thành phần" có cùng cấu trúc hoặc phạm vi giá trị giới hạn (thường là số nguyên).
- Không gian phụ trợ: Cần không gian $O(n+k)$ cho mảng tạm
outputvà mảngcount, có thể tốn kém hơn so với một số thuật toán tại chỗ (in-place) như QuickSort. - Cần biết phạm vi/số chữ số: Việc triển khai hiệu quả đòi hỏi phải biết phạm vi giá trị hoặc số lượng chữ số tối đa để xác định số lần lặp và kích thước mảng
count. - Hiệu suất thực tế: Mặc dù có độ phức tạp lý thuyết tốt, hằng số ẩn trong $O()$ có thể lớn hơn do chi phí của
countingSortvà việc sao chép mảng. Với các tập dữ liệu nhỏ hoặc trung bình, các thuật toán $O(n \log n)$ như QuickSort (có hằng số nhỏ hơn trong trường hợp trung bình) thường nhanh hơn.
Các trường hợp sử dụng của Radix Sort
Radix Sort tỏa sáng trong các tình huống sau:
- Sắp xếp các số nguyên lớn: Khi bạn cần sắp xếp một lượng lớn các số nguyên dương và biết phạm vi giá trị của chúng (hoặc số chữ số tối đa).
- Sắp xếp dữ liệu có cấu trúc dạng số: Ví dụ, sắp xếp địa chỉ IP, số điện thoại, mã sản phẩm có cấu trúc chữ số/ký tự nhất quán.
- Sắp xếp chuỗi ký tự (Strings): Radix Sort có thể được áp dụng để sắp xếp các chuỗi có độ dài cố định (hoặc có thể được đệm để có độ dài cố định). Ta coi mỗi ký tự là một "chữ số" trong hệ cơ số 256 (hoặc kích thước bảng mã ký tự).
- Sử dụng làm thuật toán con: Đôi khi Radix Sort được sử dụng như một phần của các thuật toán phức tạp hơn.
Radix Sort không phải là thuật toán sắp xếp "phổ thông" như QuickSort hay MergeSort, nhưng nó là một công cụ cực kỳ mạnh mẽ và hiệu quả khi dữ liệu đầu vào phù hợp với giả định của nó – đó là dữ liệu có thể phân tách thành các "chữ số" hoặc "thành phần" có phạm vi giới hạn.
Biến thể: Radix Sort MSD
Mặc dù LSD Radix Sort phổ biến hơn cho số nguyên có độ dài khác nhau, vẫn có biến thể MSD Radix Sort (sắp xếp từ chữ số quan trọng nhất).
- Cách hoạt động: Bắt đầu sắp xếp dựa trên chữ số quan trọng nhất. Sau khi sắp xếp, mảng được chia thành các "thùng" (bucket) dựa trên giá trị của chữ số đó. Sau đó, mỗi thùng con được sắp xếp đệ quy dựa trên chữ số quan trọng nhất tiếp theo.
- Ưu điểm: Có thể dừng sớm nếu dữ liệu đã được phân loại hoàn toàn chỉ sau vài chữ số đầu tiên. Tự nhiên hơn khi sắp xếp chuỗi có độ dài khác nhau.
- Nhược điểm: Việc triển khai phức tạp hơn (thường sử dụng đệ quy), xử lý các nhóm có cùng giá trị chữ số (tie) và các phần tử có độ dài khác nhau đòi hỏi logic phức tạp hơn LSD.
Với số nguyên, LSD Radix Sort thường là lựa chọn đơn giản và hiệu quả hơn.
Bài tập ví dụ:
Kiến trên vòng tròn
Trong một chuyến dã ngoại tại công viên, FullHouse Dev bắt gặp một hiện tượng thú vị: những chú kiến đang di chuyển trên một vòng tròn. Điều này khiến họ nghĩ ra một bài toán thú vị về sự di chuyển của kiến.
Bài toán
Trong một quốc gia, tất cả kiến di chuyển trên một vòng tròn. Vòng tròn được đánh dấu với \(n\) điểm đánh số từ \(1\) đến \(n\) theo chiều kim đồng hồ. Có \(m\) con kiến trên vòng tròn. Ban đầu, không có hai con kiến nào đứng trên cùng một điểm đánh dấu. Chúng ta biết hướng di chuyển của mỗi con kiến. Nếu hai con kiến gặp nhau trong quá trình di chuyển, mỗi con sẽ bắt đầu di chuyển theo hướng ngược lại. Nhiệm vụ của FullHouse Dev là xác định vị trí của các con kiến sau \(t\) giây di chuyển.
INPUT FORMAT:
- Dòng đầu tiên chứa ba số nguyên \(n\), \(m\) và \(t\).
- \(m\) dòng tiếp theo, mỗi dòng chứa hai số nguyên \(p_i\) và \(d_i\):
- \(p_i\) là vị trí ban đầu của con kiến thứ \(i\).
- \(d_i\) là hướng di chuyển của con kiến: \(1\) nếu di chuyển theo chiều kim đồng hồ, \(-1\) nếu ngược chiều kim đồng hồ.
OUTPUT FORMAT:
- In ra một dòng chứa \(m\) số nguyên theo thứ tự tăng dần, biểu thị vị trí của các con kiến sau \(t\) giây.
Ràng buộc:
- \(2 \leq n \leq 10^9\)
- \(1 \leq m \leq 10^5\)
- \(0 \leq t \leq 10^9\)
- \(1 \leq p_i \leq n\)
- \(d_i = 1\) hoặc \(d_i = -1\)
Ví dụ
INPUT
5 2 1
2 1
3 -1OUTPUT
2 3Giải thích
Trong ví dụ này, con kiến thứ nhất và con kiến thứ hai đổi vị trí cho nhau sau 1 giây. Tuyệt vời! Bài toán "Kiến trên vòng tròn" là một bài kinh điển về sự tương đương giữa va chạm và bỏ qua va chạm trong một số trường hợp. Hướng giải bài này dựa trên nhận xét quan trọng sau:
Nhận xét then chốt: Khi hai con kiến gặp nhau và đổi hướng, hiệu ứng trên tập hợp vị trí cuối cùng của các con kiến sau thời gian t là giống hệt như khi chúng đi xuyên qua nhau mà không đổi hướng. Sự khác biệt duy nhất là con kiến nào (dựa trên vị trí ban đầu) sẽ kết thúc ở vị trí cuối cùng nào.
Với nhận xét này, ta có thể chia bài toán thành hai phần:
Tính toán vị trí cuối cùng nếu các con kiến đi xuyên qua nhau:
- Đối với mỗi con kiến
iở vị trí ban đầup_ivới hướngd_i, sautgiây, vị trí của nó trên một đường thẳng vô hạn sẽ làp_i + d_i * t. - Trên vòng tròn kích thước
n, vị trí cuối cùng của nó (khi đi xuyên qua nhau) sẽ là(p_i + d_i * t)modulon. Cần cẩn thận với phép modulo cho số âm. Vị trí 1-indexedp_icó thể chuyển sang 0-indexed làp_i - 1. Vị trí cuối cùng 0-indexed sẽ là((long long)(p_i - 1) + (long long)d_i * t). Sau đó, áp dụng modulonvà đảm bảo kết quả trong khoảng[0, n-1]. Công thức(x % n + n) % ngiúp làm điều này cho số nguyênxbất kỳ vàn > 0. Cuối cùng, chuyển lại sang 1-indexed bằng cách cộng 1. - Tính toán này cho ta một danh sách các vị trí cuối cùng. Tập hợp các vị trí này chính là tập hợp các vị trí cuối cùng thực sự của các con kiến sau
tgiây (khi có va chạm).
- Đối với mỗi con kiến
Xác định con kiến nào kết thúc ở vị trí nào:
- Khi các con kiến đi xuyên qua nhau, thứ tự tương đối của chúng có thể thay đổi tùy thuộc vào tốc độ và hướng.
- Khi các con kiến va chạm và đổi hướng, thứ tự tương đối của chúng cũng thay đổi, nhưng theo cách khác.
- Tuy nhiên, sự thay đổi tổng thể về "thứ hạng" của mỗi con kiến trong danh sách được sắp xếp là nhất quán. Cụ thể, con kiến thứ
ktrong danh sách các con kiến được sắp xếp theo vị trí ban đầu sẽ kết thúc ở vị trí thứ(k + shift) % mtrong danh sách các vị trí cuối cùng (được tính ở bước 1 và sắp xếp lại), trong đóshiftlà một giá trị dịch chuyển cố định. - Giá trị
shiftnày liên quan đến tổng số lần các con kiến vượt qua "điểm xuất phát" (ví dụ: vị trí 1) theo chiều dương (vòng). Mỗi lần một con kiến "lướt" qua điểm này, nó đóng góp vào sự dịch chuyển tổng thể của thứ tự. - Số lần "vượt qua" (laps) của một con kiến
icó thể được tính dựa trên sự khác biệt giữa vị trí cuối cùng trên đường thẳng vô hạn (p_i - 1 + d_i * t) và vị trí cuối cùng trên vòng tròn (wrapped_final_pos_0indexed) chia chon. Công thứclaps_i = ((long long)(p_i - 1) + (long long)d_i * t - wrapped_final_pos_0indexed) / nsẽ cho số nguyên laps (có thể âm). - Tổng số laps của tất cả các con kiến:
TotalLaps = Sum(laps_i). - Sự dịch chuyển thứ hạng trong danh sách sắp xếp là
(TotalLaps % m + m) % m. Gọi đây làCyclicShift.
Các bước thực hiện:
- Đọc
n,m,t. - Tạo một danh sách lưu trữ cặp
{vị trí ban đầu, chỉ số gốc}chomcon kiến. Đọcp_i,d_icho từng con kiếni. Lưu{p_i, i}vào danh sách này. - Tạo một danh sách lưu trữ vị trí cuối cùng (0-indexed, đã áp dụng modulo
n) cho mỗi con kiến khi di chuyển xuyên qua nhau. - Khởi tạo
TotalLaps = 0(dùng kiểulong long). - Với mỗi con kiến
i:- Tính vị trí cuối cùng trên đường thẳng (0-indexed):
raw_final_pos = (long long)(p_i - 1) + (long long)d_i * t. - Tính vị trí cuối cùng trên vòng tròn (0-indexed):
wrapped_final_pos = (raw_final_pos % n + n) % n. - Lưu
wrapped_final_posvào danh sách vị trí cuối cùng. - Tính số laps:
laps = (raw_final_pos - wrapped_final_pos) / n. - Cộng
lapsvàoTotalLaps.
- Tính vị trí cuối cùng trên đường thẳng (0-indexed):
- Sắp xếp danh sách
{vị trí ban đầu, chỉ số gốc}theo vị trí ban đầu. Điều này cho ta thứ tự ban đầu của các con kiến. Gọi danh sách đã sắp xếp này làSortedInitial. Ant thứktrong danh sách ban đầu (0-indexed) là con có chỉ số gốcSortedInitial[k].second. - Sắp xếp danh sách các vị trí cuối cùng (đã áp dụng modulo
n). Gọi danh sách đã sắp xếp này làSortedFinalPositions.SortedFinalPositions[k]là vị trí thứk(0-indexed) trong tập hợp các vị trí cuối cùng. - Tính dịch chuyển chu kỳ:
CyclicShift = (TotalLaps % m + m) % m. - Tạo một mảng kết quả
FinalPositionsForOriginalAntcó kích thướcm. - Với mỗi
ktừ0đếnm-1:- Con kiến ban đầu có chỉ số gốc
original_idx = SortedInitial[k].secondlà con thứktheo vị trí ban đầu. - Nó sẽ kết thúc ở vị trí thứ
(k + CyclicShift) % mtrong danh sách các vị trí cuối cùng đã sắp xếp. - Vị trí cuối cùng của nó (1-indexed) là
SortedFinalPositions[(k + CyclicShift) % m] + 1. - Gán giá trị này vào
FinalPositionsForOriginalAnt[original_idx].
- Con kiến ban đầu có chỉ số gốc
- In ra các phần tử của mảng
FinalPositionsForOriginalAnt.
Lưu ý:
- Cần sử dụng kiểu dữ liệu
long longcho các phép tính liên quan đếntvàn(raw_final_pos,TotalLaps) vì chúng có thể rất lớn. - Phép modulo cho số âm trong C++ có thể cho kết quả âm. Công thức
(x % n + n) % n(với n > 0) đảm bảo kết quả trong khoảng[0, n-1]. - Phép chia
(raw_final_pos - wrapped_final_pos) / nđể tính laps là chính xác vìraw_final_pos - wrapped_final_poschắc chắn là bội số củantheo cách ta định nghĩawrapped_final_pos.
Làm thêm nhiều bài tập miễn phí tại đây
Khóa học liên quan
 Giảm giá!
Giảm giá!
Comments