Bài 14.1. Nguyên lý và cài đặt Quick Sort cơ bản
Bài 14.1. Nguyên lý và cài đặt Quick Sort cơ bản
Chào mừng trở lại với series bài viết về Cấu trúc dữ liệu và Giải thuật! Hôm nay, chúng ta sẽ cùng nhau khám phá một trong những "ngôi sao" sáng giá nhất trong thế giới các thuật toán sắp xếp: Quick Sort. Nổi tiếng với hiệu suất trung bình tuyệt vời trong thực tế, Quick Sort là một thuật toán dựa trên nguyên lý chia để trị (Divide and Conquer) và là kiến thức nền tảng mà bất kỳ lập trình viên nào cũng nên nắm vững.
Trong bài viết này, chúng ta sẽ đi sâu vào:
- Nguyên lý hoạt động cơ bản của Quick Sort.
- Cơ chế phân hoạch (partitioning) – "trái tim" của thuật toán.
- Cài đặt thuật toán Quick Sort cơ bản bằng ngôn ngữ C++.
Hãy cùng bắt đầu hành trình chinh phục Quick Sort!
Nguyên lý hoạt động của Quick Sort
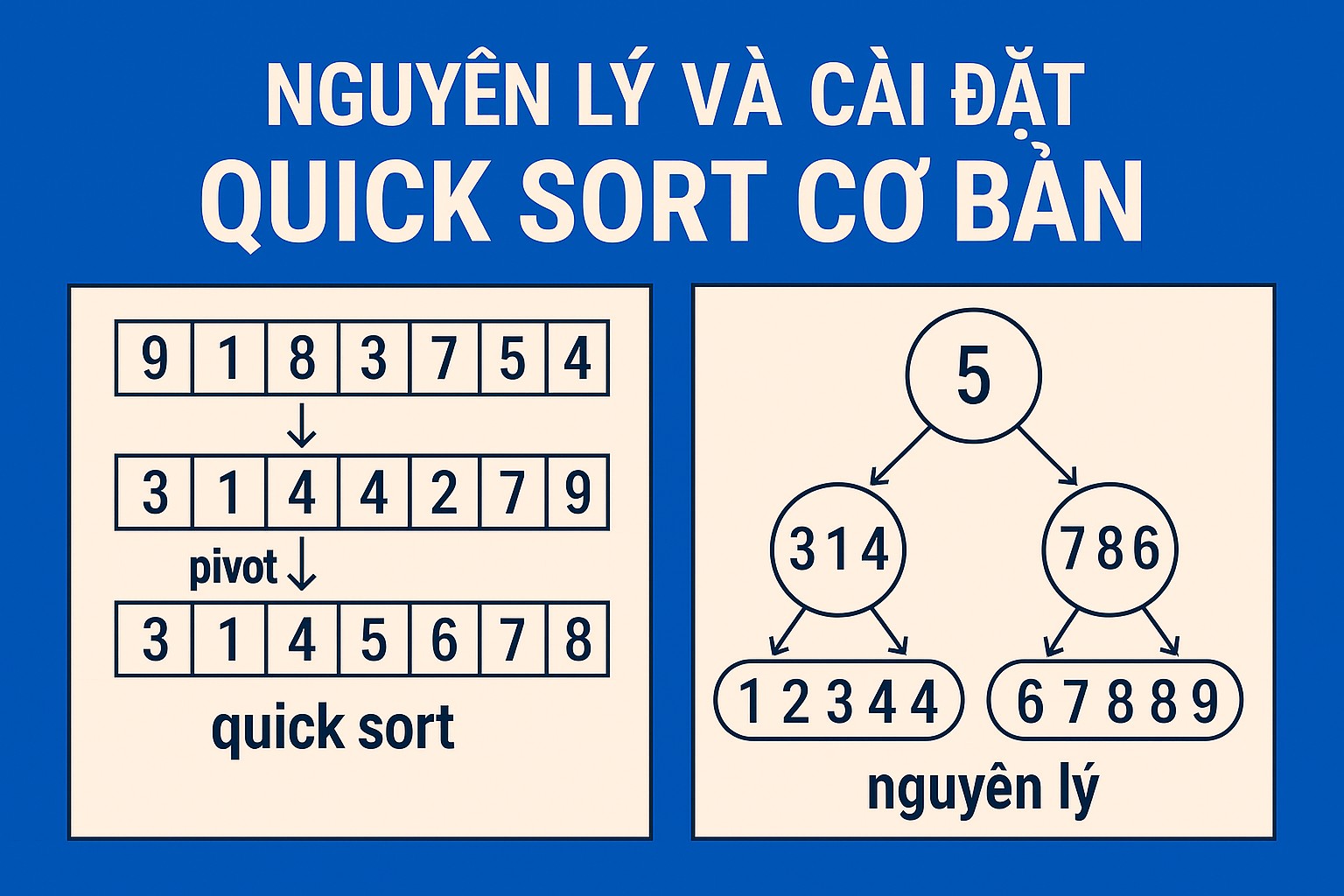
Quick Sort tuân theo nguyên lý chia để trị nổi tiếng. Ý tưởng cốt lõi của nó rất đơn giản nhưng mạnh mẽ:
- Chọn Pivot (Phần tử chốt): Từ mảng (hoặc đoạn mảng) cần sắp xếp, chọn một phần tử bất kỳ làm pivot. Việc chọn pivot có nhiều cách, nhưng trong cài đặt cơ bản, chúng ta thường chọn phần tử cuối cùng hoặc phần tử đầu tiên của đoạn mảng.
- Phân hoạch (Partition): Sắp xếp lại các phần tử trong đoạn mảng sao cho tất cả các phần tử nhỏ hơn hoặc bằng pivot đều nằm ở bên trái pivot, và tất cả các phần tử lớn hơn pivot đều nằm ở bên phải pivot. Sau bước này, pivot sẽ nằm ở vị trí cuối cùng của nó trong mảng đã được sắp xếp hoàn chỉnh.
- Đệ quy (Recursively Sort): Lặp lại quá trình Quick Sort một cách đệ quy trên hai mảng con: mảng con bên trái pivot và mảng con bên phải pivot.
Quá trình đệ quy này tiếp tục cho đến khi các mảng con chỉ còn 0 hoặc 1 phần tử (đây là trường hợp cơ sở - base case), lúc đó chúng coi như đã được sắp xếp. Bằng cách này, toàn bộ mảng ban đầu sẽ được sắp xếp hoàn chỉnh.
Bước Quan Trọng Nhất: Phân hoạch (Partitioning)
Cơ chế phân hoạch chính là linh hồn của Quick Sort. Có nhiều cách để thực hiện phân hoạch, nhưng một trong những phương pháp phổ biến và dễ hiểu là sử dụng hai con trỏ (hoặc chỉ số). Chúng ta sẽ sử dụng phương pháp này để minh họa.
Giả sử chúng ta muốn phân hoạch đoạn mảng từ chỉ số low đến high, và chúng ta chọn phần tử tại arr[high] làm pivot.
Các bước thực hiện phân hoạch:
- Chọn
pivot = arr[high]. - Khởi tạo một chỉ số
i(gọi là chỉ số nhỏ hơn) tại vị trílow - 1. Chỉ sốisẽ theo dõi ranh giới giữa các phần tử nhỏ hơn hoặc bằng pivot và các phần tử chưa được xử lý. - Duyệt qua mảng từ chỉ số
j = lowđếnhigh - 1. - Đối với mỗi phần tử
arr[j]:- Nếu
arr[j] <= pivot: Điều này có nghĩa làarr[j]thuộc về "phần nhỏ hơn hoặc bằng" của pivot. Chúng ta cần đưa nó vào vị trí thích hợp ở phía bên trái. Để làm điều đó, chúng ta tăngilên 1 (để tạo không gian cho phần tử mới) và sau đó hoán đổi (swap)arr[i]vàarr[j].
- Nếu
- Sau khi duyệt xong toàn bộ mảng con (từ
lowđếnhigh - 1), tất cả các phần tử nhỏ hơn hoặc bằng pivot đã được gom về phía bên trái của chỉ sối. Vị tríi + 1hiện tại là nơi pivot nên được đặt vào để hoàn thành phân hoạch. - Hoán đổi
arr[i + 1]vớiarr[high](phần tử pivot ban đầu). - Trả về chỉ số của pivot sau khi hoán đổi, đó là
i + 1.
Hãy hình dung với một ví dụ nhỏ: Mảng [10, 80, 30, 90, 40, 50, 70], low = 0, high = 6. Pivot là arr[6] = 70.
- Ban đầu:
arr = [10, 80, 30, 90, 40, 50, 70],low = 0,high = 6,pivot = 70,i = -1. j = 0,arr[0] = 10.10 <= 70. Tăngilên 0. Swaparr[0]vàarr[0](không đổi).arr = [10, 80, 30, 90, 40, 50, 70],i = 0.j = 1,arr[1] = 80.80 > 70. Không làm gì.arr = [10, 80, 30, 90, 40, 50, 70],i = 0.j = 2,arr[2] = 30.30 <= 70. Tăngilên 1. Swaparr[1]vàarr[2].arr = [10, 30, 80, 90, 40, 50, 70],i = 1.j = 3,arr[3] = 90.90 > 70. Không làm gì.arr = [10, 30, 80, 90, 40, 50, 70],i = 1.j = 4,arr[4] = 40.40 <= 70. Tăngilên 2. Swaparr[2]vàarr[4].arr = [10, 30, 40, 90, 80, 50, 70],i = 2.j = 5,arr[5] = 50.50 <= 70. Tăngilên 3. Swaparr[3]vàarr[5].arr = [10, 30, 40, 50, 80, 90, 70],i = 3.- Vòng lặp kết thúc (
jđã đếnhigh - 1 = 5). - Hoán đổi
arr[i + 1](arr[4]) vớiarr[high](arr[6], pivot). Swaparr[4](80) vàarr[6](70).arr = [10, 30, 40, 50, 70, 90, 80]. - Pivot (70) đã ở đúng vị trí (chỉ số 4). Trả về
i + 1 = 4.
Sau bước phân hoạch này, mảng được chia thành 3 phần: [10, 30, 40, 50] (nhỏ hơn hoặc bằng pivot), [70] (pivot), [90, 80] (lớn hơn pivot). Quick Sort sẽ được gọi đệ quy trên [10, 30, 40, 50] và [90, 80].
Cài đặt Quick Sort bằng C++
Bây giờ, chúng ta sẽ hiện thực hóa nguyên lý và bước phân hoạch vừa học bằng ngôn ngữ C++.
#include <iostream>
#include <vector>
#include <algorithm> // Thư viện chứa std::swap
// Hàm tiện ích để in mảng
void printArray(const std::vector<int>& arr) {
for (int x : arr) {
std::cout << x << " ";
}
std::cout << std::endl;
}
// Hàm hoán đổi hai phần tử
// Có thể dùng std::swap từ thư viện <algorithm> thay thế
void swap(int& a, int& b) {
int t = a;
a = b;
b = t;
}
/*
* Hàm này nhận chỉ mục cuối cùng làm pivot,
* đặt phần tử pivot vào đúng vị trí của nó trong mảng đã sắp xếp,
* và đặt tất cả các phần tử nhỏ hơn (pivot) ở bên trái pivot
* và tất cả các phần tử lớn hơn ở bên phải pivot.
*/
int partition(std::vector<int>& arr, int low, int high) {
// Chọn phần tử cuối cùng làm pivot
int pivot = arr[high];
// Chỉ mục của phần tử nhỏ hơn (chỉ ra vị trí cho phần tử nhỏ hơn hoặc bằng pivot tiếp theo)
int i = (low - 1);
// Duyệt qua tất cả các phần tử từ low đến high-1
for (int j = low; j <= high - 1; j++) {
// Nếu phần tử hiện tại nhỏ hơn hoặc bằng pivot
if (arr[j] <= pivot) {
// Tăng chỉ mục của phần tử nhỏ hơn
i++;
// Hoán đổi phần tử hiện tại với phần tử tại chỉ mục i
swap(arr[i], arr[j]);
}
}
// Cuối cùng, hoán đổi phần tử pivot (arr[high]) với phần tử tại vị trí i + 1
swap(arr[i + 1], arr[high]);
// Trả về chỉ mục của pivot sau khi đã đặt đúng vị trí
return (i + 1);
}
/*
* Hàm chính thực hiện QuickSort
* arr[] --> Mảng cần sắp xếp
* low --> Chỉ mục bắt đầu
* high --> Chỉ mục kết thúc
*/
void quickSort(std::vector<int>& arr, int low, int high) {
// Trường hợp cơ sở: Nếu chỉ mục bắt đầu nhỏ hơn chỉ mục kết thúc
// (tức là mảng con có 2 phần tử trở lên)
if (low < high) {
// pi là chỉ mục phân hoạch, arr[pi] hiện đã ở đúng vị trí
int pi = partition(arr, low, high);
// Sắp xếp đệ quy mảng con bên trái của pivot
quickSort(arr, low, pi - 1);
// Sắp xếp đệ quy mảng con bên phải của pivot
quickSort(arr, pi + 1, high);
}
// Trường hợp cơ sở khi low >= high, mảng con có 0 hoặc 1 phần tử,
// coi như đã sắp xếp, hàm đệ quy dừng lại.
}
// Hàm main để kiểm tra thuật toán
int main() {
std::vector<int> arr = {10, 7, 8, 9, 1, 5};
int n = arr.size();
std::cout << "Mang truoc khi sap xep: ";
printArray(arr);
quickSort(arr, 0, n - 1);
std::cout << "Mang sau khi sap xep: ";
printArray(arr);
std::cout << std::endl;
std::vector<int> arr2 = {4, 5, 3, 7, 2, 1, 8, 6};
n = arr2.size();
std::cout << "Mang truoc khi sap xep: ";
printArray(arr2);
quickSort(arr2, 0, n - 1);
std::cout << "Mang sau khi sap xep: ";
printArray(arr2);
return 0;
}
Giải thích Chi Tiết Code C++
Hãy cùng phân tích từng phần của đoạn mã trên:
Includes và Hàm tiện ích:
#include <iostream>: Để sử dụngstd::coutcho việc in ấn.#include <vector>: Để sử dụngstd::vectorlàm cấu trúc dữ liệu cho mảng.#include <algorithm>: Chứa hàmstd::swapcó thể được sử dụng thay cho hàmswaptự viết.printArray: Một hàm đơn giản để hiển thị nội dung củastd::vector.swap: Hàm hoán đổi giá trị của hai biến (truyền theo tham chiếu&). Mặc dùstd::swaplà lựa chọn tốt hơn trong thực tế, việc tự viết hàm swap giúp hiểu rõ hơn cơ chế.
Hàm
partition(std::vector<int>& arr, int low, int high):- Đây là "trái tim" của thuật toán Quick Sort. Nó chịu trách nhiệm sắp xếp lại đoạn mảng từ
lowđếnhighxung quanh một pivot. int pivot = arr[high];: Chúng ta chọn phần tử cuối cùng của đoạn mảng làm pivot.int i = (low - 1);: Biếniđược khởi tạo làlow - 1. Nó đóng vai trò là ranh giới cuối cùng của vùng chứa các phần tử nhỏ hơn hoặc bằng pivot đã được tìm thấy. Bất kỳ khi nào chúng ta tìm thấy một phần tửarr[j]nhỏ hơn hoặc bằng pivot, chúng ta sẽ tăngilên 1 và đặtarr[j]vào vị tríarr[i].for (int j = low; j <= high - 1; j++): Vòng lặp này duyệt qua tất cả các phần tử trong đoạn mảng ngoại trừ phần tử pivot cuối cùng.if (arr[j] <= pivot): Kiểm tra nếu phần tử hiện tại (arr[j]) nhỏ hơn hoặc bằng pivot.i++; swap(arr[i], arr[j]);: Nếu điều kiện trên đúng, chúng ta đã tìm thấy một phần tử cần được đặt vào vùng "nhỏ hơn hoặc bằng pivot". Ta tăngilên để mở rộng vùng này, và sau đó hoán đổiarr[i](phần tử đầu tiên của vùng "lớn hơn pivot" hoặc vùng chưa xử lý) vớiarr[j](phần tử nhỏ hơn hoặc bằng pivot vừa tìm thấy). Thao tác này đảm bảo rằng sau hoán đổi,arr[i]nằm trong vùng "nhỏ hơn hoặc bằng pivot".swap(arr[i + 1], arr[high]);: Sau khi vòng lặp kết thúc,ilà chỉ số cuối cùng của phần tử nhỏ hơn hoặc bằng pivot đã được đặt vào vị trí đúng. Do đó, vị tríi + 1chính là nơi pivot nên nằm trong mảng đã được phân hoạch. Ta hoán đổi pivot (ban đầu ởarr[high]) với phần tử tạiarr[i + 1].return (i + 1);: Hàm trả về chỉ số cuối cùng của pivot (i + 1), đây là điểm phân chia mảng thành hai mảng con.
- Đây là "trái tim" của thuật toán Quick Sort. Nó chịu trách nhiệm sắp xếp lại đoạn mảng từ
Hàm
quickSort(std::vector<int>& arr, int low, int high):- Đây là hàm đệ quy gọi partition và sau đó tự gọi lại chính nó trên các mảng con.
if (low < high): Đây là điều kiện kiểm tra trường hợp cơ sở (base case). Nếulowkhông còn nhỏ hơnhigh(nghĩa làlow >= high), đoạn mảng chỉ có 0 hoặc 1 phần tử, coi như đã sắp xếp và hàm đệ quy dừng lại ở nhánh này.int pi = partition(arr, low, high);: Gọi hàmpartitionđể phân hoạch đoạn mảng hiện tại.pisẽ là chỉ số của pivot sau khi phân hoạch. Phần tử tạiarr[pi]đã ở đúng vị trí cuối cùng của nó.quickSort(arr, low, pi - 1);: Gọi đệ quy Quick Sort trên mảng con bên trái pivot (từlowđếnpi - 1).quickSort(arr, pi + 1, high);: Gọi đệ quy Quick Sort trên mảng con bên phải pivot (từpi + 1đếnhigh). Lưu ý rằng pivot tại chỉ sốpikhông bao gồm trong các cuộc gọi đệ quy này vì nó đã được sắp xếp.
Hàm
main():- Tạo một hoặc nhiều vector số nguyên để thử nghiệm.
- In mảng ban đầu.
- Gọi
quickSortvới chỉ số bắt đầu0và chỉ số kết thúcn - 1(nlà kích thước mảng). - In mảng sau khi sắp xếp để kiểm tra kết quả.
Ví dụ Minh Họa Chi Tiết (Code và Kết quả)
Khi bạn chạy đoạn code C++ đầy đủ ở trên, với hai mảng ví dụ trong hàm main, kết quả đầu ra sẽ như sau:
Mang truoc khi sap xep: 10 7 8 9 1 5
Mang sau khi sap xep: 1 5 7 8 9 10
Mang truoc khi sap xep: 4 5 3 7 2 1 8 6
Mang sau khi sap xep: 1 2 3 4 5 6 7 8Kết quả này cho thấy thuật toán đã sắp xếp các mảng thành công theo thứ tự tăng dần.
Độ phức tạp của Quick Sort (Sơ lược)
- Trường hợp trung bình (Average Case): Độ phức tạp thời gian của Quick Sort là O(n log n). Đây là lý do tại sao nó được ưa chuộng trong thực tế, bởi vì hiệu suất trung bình của nó rất tốt, thường vượt trội so với các thuật toán O(n log n) khác như Merge Sort trên nhiều bộ dữ liệu thực tế do các yếu tố như locality of reference (khả năng truy cập dữ liệu gần nhau trong bộ nhớ).
- Trường hợp xấu nhất (Worst Case): Độ phức tạp thời gian có thể lên tới O(n^2). Trường hợp này xảy ra khi việc chọn pivot liên tục dẫn đến phân hoạch không cân bằng, ví dụ khi mảng đã được sắp xếp hoặc gần sắp xếp và chúng ta luôn chọn phần tử nhỏ nhất hoặc lớn nhất làm pivot.
- Độ phức tạp không gian (Space Complexity):
- Trường hợp trung bình: O(log n), do độ sâu của cây đệ quy.
- Trường hợp xấu nhất: O(n), khi việc phân hoạch không cân bằng khiến cây đệ quy trở nên "xiên" (skewed) và độ sâu đệ quy bằng n.
Mặc dù có trường hợp xấu nhất là O(n^2), trong thực tế, với cách chọn pivot thông minh (ví dụ: chọn ngẫu nhiên, chọn trung vị của 3 phần tử), trường hợp xấu nhất này rất hiếm xảy ra.
Bài tập ví dụ:
Cuộc phiêu lưu trong vườn táo kỳ diệu
Trong một buổi chạy bộ sáng sớm, FullHouse Dev đã tình cờ gặp một vườn táo kỳ lạ. Họ quyết định biến cuộc chạy bộ thành một trò chơi thú vị với những quả táo này. Với tinh thần đồng đội và sự nhanh nhẹn, FullHouse Dev bắt đầu khám phá vườn táo đặc biệt này.
Bài toán
FullHouse Dev đang ở điểm \((1, 1)\) trong một ma trận. Họ có thể di chuyển theo các bước sau:
- Nếu hàng hiện tại có 1 hoặc nhiều quả táo, họ có thể đi đến cuối hàng đó và đi lên.
- Nếu không, họ chỉ có thể đi lên.
Ma trận chứa \(N\) quả táo. Quả táo thứ \(i\) nằm ở điểm \((x_i, y_i)\). FullHouse Dev có thể ăn những quả táo này trong quá trình di chuyển.
Nhiệm vụ của họ là xác định số lượng táo đã được ăn trước mỗi quả táo.
INPUT FORMAT:
- Dòng đầu tiên chứa một số nguyên \(N\) (1 ≤ N ≤ 10^5) - số lượng quả táo.
- \(N\) dòng tiếp theo, mỗi dòng chứa hai số nguyên \(x_i\) và \(y_i\) (1 ≤ x_i, y_i ≤ 10^9) - tọa độ của quả táo thứ \(i\).
OUTPUT FORMAT:
- In ra \(N\) dòng, mỗi dòng chứa một số nguyên - số lượng táo đã được ăn trước quả táo thứ \(i\).
Ràng buộc:
- \(1 \leq N \leq 10^5\)
- \(1 \leq x_i, y_i \leq 10^9\)
Ví dụ
INPUT
5
1 4
6 7
2 3
2 5
3 7OUTPUT
0
4
2
1
3Giải thích
- Quả táo đầu tiên (1, 4) được ăn trước tiên, nên số táo đã ăn trước đó là 0.
- Quả táo thứ hai (6, 7) được ăn sau cùng, sau khi đã ăn 4 quả táo khác.
- Quả táo thứ ba (2, 3) được ăn sau khi đã ăn 2 quả táo (ở (1, 4) và (2, 5)).
- Quả táo thứ tư (2, 5) được ăn sau khi đã ăn 1 quả táo (ở (1, 4)).
- Quả táo thứ năm (3, 7) được ăn sau khi đã ăn 3 quả táo (ở (1, 4), (2, 3), và (2, 5)).
FullHouse Dev đã hoàn thành cuộc chạy bộ đầy thú vị này, kết hợp giữa việc rèn luyện sức khỏe và giải quyết bài toán thú vị về ăn táo. Họ không chỉ cải thiện thể lực mà còn rèn luyện trí óc, thể hiện tinh thần đồng đội và sự sáng tạo của mình. Chào bạn, đây là hướng dẫn giải bài "Cuộc phiêu lưu trong vườn táo kỳ diệu" một cách ngắn gọn, tập trung vào ý tưởng chính mà không cung cấp code hoàn chỉnh.
Ý tưởng cốt lõi:
Bài toán này không yêu cầu mô phỏng chuyển động trên một ma trận khổng lồ (do tọa độ có thể rất lớn). Thay vào đó, điểm mấu chốt là xác định thứ tự mà FullHouse Dev ăn các quả táo. Một khi thứ tự được xác định, số lượng táo ăn trước một quả táo cụ thể chính là chỉ số của nó trong thứ tự ăn (bắt đầu từ 0).
Xác định thứ tự ăn táo:
- FullHouse Dev luôn di chuyển từ dưới lên (tăng dần theo trục
x). - Trong một hàng
xbất kỳ:- Nếu hàng đó có ít nhất một quả táo, FullHouse Dev sẽ đi ngang hết hàng (từ trái sang phải) rồi mới đi lên hàng tiếp theo. Điều này có nghĩa là tất cả các quả táo trong hàng đó sẽ được ăn, và chúng sẽ được ăn theo thứ tự tăng dần của tọa độ
y. - Nếu hàng đó không có táo, FullHouse Dev chỉ đi thẳng lên hàng tiếp theo mà không ăn quả táo nào ở hàng này.
- Nếu hàng đó có ít nhất một quả táo, FullHouse Dev sẽ đi ngang hết hàng (từ trái sang phải) rồi mới đi lên hàng tiếp theo. Điều này có nghĩa là tất cả các quả táo trong hàng đó sẽ được ăn, và chúng sẽ được ăn theo thứ tự tăng dần của tọa độ
Từ hai quy tắc trên, thứ tự ăn táo chính là:
- Ưu tiên hàng thấp hơn (tọa độ
xnhỏ hơn). - Trong cùng một hàng
x, ưu tiên táo có tọa độynhỏ hơn.
Nói cách khác, thứ tự ăn táo là thứ tự khi sắp xếp các quả táo theo tọa độ x tăng dần, và nếu x bằng nhau thì sắp xếp theo tọa độ y tăng dần.
Các bước giải:
- Đọc dữ liệu và lưu trữ: Đọc
Nquả táo. Với mỗi quả táoi(được nhập ở dòngi+1), lưu trữ tọa độ(x_i, y_i)cùng với chỉ số gốc của nó (tức lài). - Sắp xếp: Sắp xếp danh sách các quả táo đã lưu trữ theo tiêu chí:
- Sắp xếp chính theo tọa độ
xtăng dần. - Nếu hai quả táo có cùng tọa độ
x, sắp xếp phụ theo tọa độytăng dần.
- Sắp xếp chính theo tọa độ
- Xác định số táo đã ăn trước: Duyệt qua danh sách táo đã được sắp xếp.
- Quả táo đầu tiên trong danh sách sắp xếp là quả táo được ăn đầu tiên. Số táo đã ăn trước nó là 0.
- Quả táo thứ hai được ăn sau quả thứ nhất. Số táo đã ăn trước nó là 1.
- Quả táo thứ
k(trong danh sách sắp xếp, bắt đầu từk=0) là quả táo thứk+1được ăn. Số táo đã ăn trước nó làk. - Lưu trữ kết quả
knày vào một mảng kết quả, sử dụng chỉ số gốc của quả táo đó làm chỉ mục.
- In kết quả: Duyệt qua mảng kết quả theo chỉ số gốc từ 0 đến
N-1và in từng giá trị ra trên một dòng mới.
Cấu trúc dữ liệu gợi ý:
- Sử dụng một
structhoặcpairđể lưu trữ(x, y, original_index)cho mỗi quả táo. - Sử dụng
std::vectorđể chứa danh sách các quả táo này. - Sử dụng
std::sortvới một hàm so sánh tùy chỉnh (hoặc overload toán tử<trong struct) để sắp xếp vector. - Sử dụng một
std::vectorkhác (kích thướcN) để lưu trữ kết quả theo chỉ số gốc.
Lưu ý:
- Tọa độ có thể lớn (
10^9), nhưng chỉ cần lưu trữ và so sánh chúng, không cần tạo ma trận thực. Ncó thể lên đến10^5, thuật toán sắp xếp (O(N log N)) và duyệt (O(N)) là hiệu quả.- Đảm bảo xử lý input/output nhanh chóng (ví dụ: sử dụng
ios_base::sync_with_stdio(false); cin.tie(NULL);trong C++).
Làm thêm nhiều bài tập miễn phí tại đây
Khóa học liên quan
 Giảm giá!
Giảm giá!
Comments