Bài 16.1. Linear Search và các trường hợp sử dụng
Bài 16.1. Linear Search và các trường hợp sử dụng
Chào mừng các bạn quay trở lại với hành trình khám phá thế giới đầy thú vị của Cấu trúc dữ liệu và Giải thuật! Sau khi tìm hiểu về các cấu trúc cơ bản, đã đến lúc chúng ta đi sâu vào một trong những nhóm giải thuật quan trọng nhất: các giải thuật tìm kiếm. Và điểm khởi đầu, nền tảng của mọi thứ, chính là thuật toán Linear Search, hay còn gọi là Tìm kiếm tuyến tính.
Nghe có vẻ đơn giản, và đúng là nó rất đơn giản! Nhưng đừng vì thế mà đánh giá thấp nó. Linear Search là một khái niệm cơ bản mà mọi lập trình viên cần nắm vững, và nó vẫn có những "đất diễn" riêng trong thế giới thực.
Vậy, Linear Search là gì và khi nào chúng ta nên "triệu hồi" nó? Hãy cùng đi sâu vào chi tiết nhé!
Linear Search là gì?
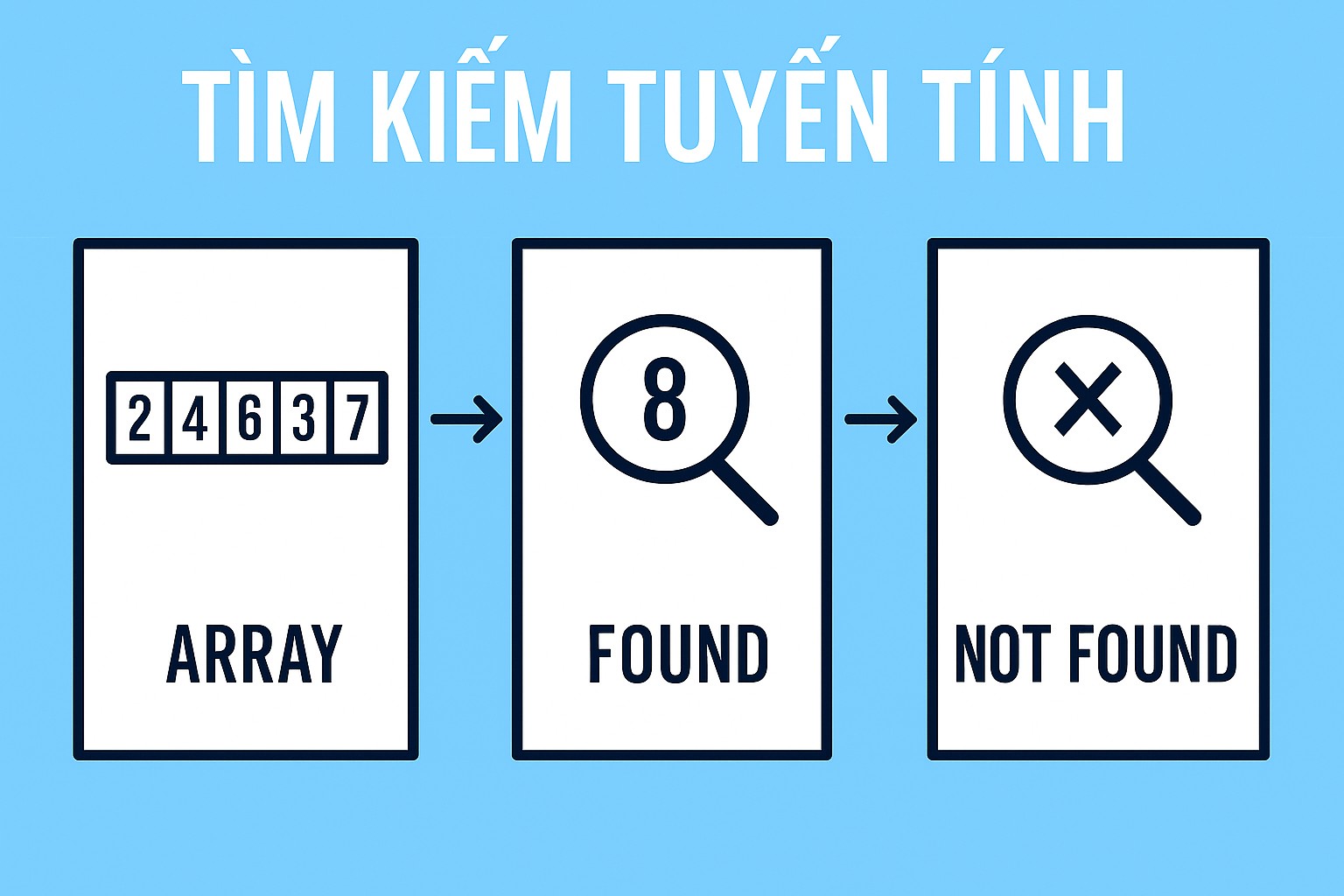
Hãy tưởng tượng bạn đang tìm một cuốn sách cụ thể trong một giá sách không được sắp xếp. Bạn sẽ làm thế nào? Có lẽ cách tự nhiên nhất là bắt đầu từ một đầu giá sách, nhìn vào cuốn đầu tiên, rồi cuốn thứ hai, cuốn thứ ba... cho đến khi tìm thấy cuốn sách mình cần, hoặc duyệt hết cả giá sách mà không thấy nó.
Đó chính là ý tưởng cốt lõi của Linear Search!
Nói một cách kỹ thuật hơn, Linear Search là một giải thuật tìm kiếm tuần tự. Nó hoạt động bằng cách kiểm tra từng phần tử một trong một danh sách (mảng, vector, v.v.) từ đầu đến cuối, cho đến khi tìm thấy phần tử khớp với giá trị đang tìm, hoặc duyệt hết toàn bộ danh sách mà không tìm thấy.
Điểm mấu chốt: Linear Search không yêu cầu dữ liệu phải được sắp xếp. Đây là một lợi thế quan trọng so với nhiều thuật toán tìm kiếm hiệu quả hơn như Binary Search.
Cách Hoạt động
Các bước thực hiện của Linear Search vô cùng trực quan:
- Bắt đầu từ đầu: Bắt đầu duyệt qua danh sách/mảng từ phần tử đầu tiên (thường có chỉ mục 0).
- So sánh: Tại mỗi vị trí, so sánh giá trị của phần tử hiện tại với giá trị mà bạn đang muốn tìm (gọi là target value).
- Tìm thấy? Nếu giá trị hiện tại khớp với target value, chúc mừng, bạn đã tìm thấy! Thuật toán kết thúc và thường trả về vị trí (chỉ mục) của phần tử đó.
- Chưa tìm thấy? Nếu giá trị hiện tại không khớp, chuyển sang kiểm tra phần tử kế tiếp trong danh sách.
- Duyệt hết: Tiếp tục lặp lại các bước 2 và 3 cho đến khi bạn tìm thấy phần tử hoặc đã duyệt qua hết toàn bộ danh sách mà không thấy target value.
- Không tồn tại: Nếu duyệt hết danh sách mà không tìm thấy target value, thuật toán kết thúc và thông báo rằng phần tử không tồn tại (thường bằng cách trả về một giá trị đặc biệt, ví dụ như -1).
Sự đơn giản này làm cho Linear Search trở thành một trong những thuật toán dễ hiểu và dễ cài đặt nhất.
Cài đặt Linear Search với C++
Hãy xem cách triển khai Linear Search bằng ngôn ngữ C++ sử dụng std::vector.
#include <iostream> // Để sử dụng cout và cin
#include <vector> // Để sử dụng std::vector
// Hàm thực hiện tìm kiếm tuyến tính
// Tham số:
// arr: std::vector<int> - Mảng/vector chứa các phần tử cần tìm
// target: int - Giá trị cần tìm kiếm
// Trả về:
// Chỉ mục của phần tử nếu tìm thấy lần đầu tiên
// -1 nếu phần tử không có trong mảng
int linearSearch(const std::vector<int>& arr, int target) {
// Lặp qua từng phần tử của vector từ đầu đến cuối
for (int i = 0; i < arr.size(); ++i) {
// Kiểm tra xem phần tử tại chỉ mục i có bằng giá trị target hay không
if (arr[i] == target) {
// Nếu tìm thấy, trả về chỉ mục hiện tại
return i;
}
}
// Nếu vòng lặp kết thúc mà không tìm thấy phần tử,
// tức là đã duyệt hết vector nhưng không có giá trị target
// Trả về -1 để báo hiệu không tìm thấy
return -1;
}
// Hàm main để minh họa cách sử dụng
int main() {
// Tạo một vector chứa các số nguyên (không cần sắp xếp)
std::vector<int> myVector = { 25, 10, 50, 30, 70, 40, 80, 60 };
int valueToFind = 70; // Giá trị chúng ta muốn tìm
// Gọi hàm linearSearch để tìm kiếm
int foundIndex = linearSearch(myVector, valueToFind);
// Kiểm tra kết quả trả về
if (foundIndex != -1) {
// Nếu foundIndex không phải -1, tức là phần tử đã được tìm thấy
std::cout << "Phan tu " << valueToFind << " duoc tim thay tai chi muc: " << foundIndex << std::endl;
} else {
// Nếu foundIndex là -1, tức là phần tử không có trong vector
std::cout << "Phan tu " << valueToFind << " khong co trong vector." << std::endl;
}
// Một ví dụ khác với giá trị không tồn tại
int anotherValueToFind = 100;
int anotherFoundIndex = linearSearch(myVector, anotherValueToFind);
if (anotherFoundIndex != -1) {
std::cout << "Phan tu " << anotherValueToFind << " duoc tim thay tai chi muc: " << anotherFoundIndex << std::endl;
} else {
std::cout << "Phan tu " << anotherValueToFind << " khong co trong vector." << std::endl;
}
return 0; // Kết thúc chương trình
}
Giải thích mã nguồn C++:
- Chúng ta khai báo một hàm
linearSearchnhận vào mộtstd::vector<int>(kiểu dữ liệu mảng động của C++) và một số nguyêntarget. Sử dụngconst&để tránh sao chép vector lớn và đảm bảo hàm không thay đổi vector gốc. - Vòng lặp
for (int i = 0; i < arr.size(); ++i)sẽ duyệt qua từng chỉ mụcitừ 0 đến kích thước của vector trừ đi 1. Đây chính là "bước đi" tuần tự qua từng phần tử. - Bên trong vòng lặp,
if (arr[i] == target)so sánh phần tử tại chỉ mụci(arr[i]) với giá trịtargetcần tìm. - Nếu chúng bằng nhau (
arr[i] == target), tức là chúng ta đã tìm thấy phần tử. Hàm ngay lập tứcreturn i;để trả về chỉ mục nơi tìm thấy phần tử đầu tiên và kết thúc việc tìm kiếm. - Nếu vòng lặp
forhoàn thành mà không có lần nào điều kiệnifđúng, nghĩa là phần tửtargetkhông tồn tại trong vector. Lúc này, hàm sẽ thoát khỏi vòng lặp và thực hiện lệnhreturn -1;, báo hiệu rằng không tìm thấy phần tử. - Trong hàm
main, chúng ta tạo một vectormyVector, định nghĩa giá trị cần tìmvalueToFind, gọi hàmlinearSearchvà in kết quả dựa trên giá trị trả về (-1hay một chỉ mục hợp lệ).
Đơn giản đúng không? Chỉ vài dòng code là chúng ta đã triển khai xong một thuật toán tìm kiếm!
Phân tích Độ phức tạp Thời gian (Time Complexity)
Đây là lúc chúng ta đánh giá hiệu suất của Linear Search. Độ phức tạp thời gian đo lường số lượng thao tác cần thiết để thuật toán chạy xong, phụ thuộc vào kích thước của dữ liệu đầu vào (thường ký hiệu là n).
Trường hợp Tốt nhất (Best Case): O(1) Nếu phần tử bạn cần tìm là phần tử đầu tiên trong danh sách, thuật toán chỉ cần thực hiện một phép so sánh duy nhất là tìm thấy ngay lập tức. Số thao tác không phụ thuộc vào kích thước
ncủa danh sách.Trường hợp Xấu nhất (Worst Case): O(n) Nếu phần tử bạn cần tìm nằm ở cuối cùng của danh sách, hoặc không có trong danh sách, thuật toán sẽ phải duyệt qua toàn bộ n phần tử. Số phép so sánh sẽ xấp xỉ
n. Khintăng lên, thời gian thực hiện cũng tăng lên tuyến tính theon.Trường hợp Trung bình (Average Case): O(n) Trung bình, nếu phần tử tồn tại, nó có thể nằm ở bất kỳ vị trí nào. Thuật toán sẽ cần duyệt khoảng
n/2phần tử. Tuy nhiên, trong ký hiệu Big O, chúng ta bỏ qua các hằng số, nên độ phức tạp trung bình vẫn là O(n).
Tóm lại, độ phức tạp thời gian của Linear Search là O(n). Điều này có nghĩa là khi kích thước dữ liệu tăng lên gấp đôi, thời gian chạy của thuật toán trong trường hợp xấu nhất cũng sẽ tăng lên gấp đôi.
Phân tích Độ phức tạp Không gian (Space Complexity)
Độ phức tạp không gian đo lường lượng bộ nhớ phụ trợ mà thuật toán cần sử dụng, không tính đến bộ nhớ lưu trữ dữ liệu đầu vào.
Linear Search chỉ cần một vài biến phụ để lưu trữ chỉ mục hiện tại (i) và giá trị target. Lượng bộ nhớ này là không đổi bất kể kích thước của mảng đầu vào lớn đến đâu.
Do đó, độ phức tạp không gian của Linear Search là O(1). Nó sử dụng một lượng bộ nhớ không đổi (hằng số).
Các Trường hợp Sử dụng của Linear Search
Với độ phức tạp thời gian O(n), Linear Search có vẻ chậm chạp so với các thuật toán tìm kiếm khác như Binary Search (O(log n)) khi làm việc với tập dữ liệu lớn. Tuy nhiên, nó vẫn là một công cụ hữu ích trong nhiều tình huống thực tế:
Dữ liệu có kích thước nhỏ: Khi số lượng phần tử (
n) không quá lớn (vài chục, vài trăm, hoặc thậm chí vài nghìn phần tử tùy thuộc vào yêu cầu hiệu suất), sự khác biệt giữa O(n) và O(log n) là không đáng kể. Lúc này, sự đơn giản và dễ cài đặt của Linear Search trở thành một lợi thế.Dữ liệu chưa được sắp xếp: Đây là lợi thế lớn nhất của Linear Search. Các thuật toán hiệu quả hơn như Binary Search yêu cầu dữ liệu phải được sắp xếp trước. Nếu bạn làm việc với dữ liệu không được sắp xếp và chỉ cần tìm kiếm một lần hoặc vài lần trên tập dữ liệu đó, việc sử dụng Linear Search trực tiếp thường nhanh hơn so với việc phải sắp xếp toàn bộ dữ liệu (có độ phức tạp thường là O(n log n)) rồi mới thực hiện Binary Search.
Tính đơn giản và dễ cài đặt/hiểu: Trong các tình huống cần phát triển nhanh, hoặc khi làm việc với những người ít kinh nghiệm hơn, việc cài đặt và debug Linear Search là rất dễ dàng. Đôi khi, "đủ tốt" và đơn giản là quan trọng hơn "tối ưu" nhưng phức tạp.
Khi cần tìm lần xuất hiện đầu tiên: Thuật toán Linear Search cơ bản dừng lại ngay khi tìm thấy phần tử đầu tiên. Nếu yêu cầu chỉ đơn giản là kiểm tra xem một phần tử có tồn tại hay không, hoặc tìm vị trí đầu tiên của nó, Linear Search là đủ dùng.
Dữ liệu được lưu trữ theo cấu trúc chỉ hỗ trợ truy cập tuần tự: Một số cấu trúc dữ liệu (như danh sách liên kết đơn - Singly Linked List) chỉ cho phép truy cập các phần tử theo trình tự từ đầu đến cuối. Trong trường hợp này, Linear Search (duyệt từng node) là phương pháp tìm kiếm tự nhiên và thường là hiệu quả nhất trừ khi có thêm cấu trúc dữ liệu phụ trợ.
Biến thể: Tìm tất cả các lần xuất hiện
Phiên bản Linear Search ở trên chỉ trả về chỉ mục của lần xuất hiện đầu tiên của target. Nếu bạn muốn tìm tất cả các vị trí mà target xuất hiện trong mảng, bạn cần thay đổi logic một chút: không dừng lại khi tìm thấy, mà tiếp tục duyệt hết mảng và ghi lại tất cả các chỉ mục khớp.
Đây là cách thực hiện:
#include <iostream>
#include <vector>
// Hàm tìm tất cả các lần xuất hiện của một giá trị trong vector
// Tham số:
// arr: const std::vector<int>& - Mảng/vector chứa các phần tử cần tìm
// target: int - Giá trị cần tìm kiếm
// Trả về:
// std::vector<int> - Một vector chứa tất cả các chỉ mục nơi target được tìm thấy
std::vector<int> findAllOccurrences(const std::vector<int>& arr, int target) {
std::vector<int> indices; // Vector để lưu trữ các chỉ mục tìm thấy
// Lặp qua toàn bộ vector
for (int i = 0; i < arr.size(); ++i) {
// Nếu phần tử tại chỉ mục i khớp với target
if (arr[i] == target) {
// Thêm chỉ mục i vào vector kết quả
indices.push_back(i);
}
}
// Trả về vector chứa các chỉ mục
return indices;
}
// Hàm main để minh họa
int main() {
std::vector<int> myVector = { 10, 20, 30, 20, 50, 20, 70, 80, 20 };
int valueToFind = 20; // Giá trị chúng ta muốn tìm tất cả vị trí
// Gọi hàm findAllOccurrences
std::vector<int> foundIndices = findAllOccurrences(myVector, valueToFind);
// In kết quả
if (!foundIndices.empty()) {
std::cout << "Phan tu " << valueToFind << " duoc tim thay tai cac chi muc: ";
for (size_t i = 0; i < foundIndices.size(); ++i) {
std::cout << foundIndices[i] << (i == foundIndices.size() - 1 ? "" : ", "); // In chỉ mục, thêm dấu phẩy nếu không phải cuối cùng
}
std::cout << std::endl;
} else {
std::cout << "Phan tu " << valueToFind << " khong co trong vector." << std::endl;
}
// Ví dụ khác với giá trị không có
int anotherValueToFind = 100;
std::vector<int> anotherFoundIndices = findAllOccurrences(myVector, anotherValueToFind);
if (!anotherFoundIndices.empty()) {
std::cout << "Phan tu " << anotherValueToFind << " duoc tim thay tai cac chi muc: ";
for (size_t i = 0; i < anotherFoundIndices.size(); ++i) {
std::cout << anotherFoundIndices[i] << (i == anotherFoundIndices.size() - 1 ? "" : ", ");
}
std::cout << std::endl;
} else {
std::cout << "Phan tu " << anotherValueToFind << " khong co trong vector." << std::endl;
}
return 0;
}
Giải thích mã nguồn biến thể:
- Hàm
findAllOccurrencesbây giờ trả về mộtstd::vector<int>để chứa tất cả các chỉ mục tìm được. - Chúng ta khởi tạo một vector rỗng
indicesđể lưu kết quả. - Vòng lặp
forvẫn duyệt qua toàn bộ vectorarr. - Nếu tìm thấy phần tử khớp (
arr[i] == target), thay vìreturn i;, chúng ta thêm chỉ mục hiện tạiivào vectorindicesbằngindices.push_back(i);. - Sau khi vòng lặp kết thúc (đã duyệt hết vector), hàm trả về vector
indiceschứa tất cả các vị trí màtargetxuất hiện. - Trong
main, chúng ta nhận vector kết quả và lặp qua nó để in ra các chỉ mục tìm thấy.
Biến thể này vẫn có độ phức tạp thời gian là O(n) trong trường hợp xấu nhất (và trung bình) vì nó luôn phải duyệt qua toàn bộ n phần tử của vector để đảm bảo tìm thấy tất cả các lần xuất hiện. Độ phức tạp không gian là O(k) trong đó k là số lần xuất hiện của target (để lưu trữ các chỉ mục), trong trường hợp xấu nhất là O(n) nếu tất cả phần tử đều là target.
So sánh nhanh với các thuật toán khác
Mặc dù có độ phức tạp O(n), Linear Search là nền tảng. Khi dữ liệu được sắp xếp, chúng ta có thể sử dụng Binary Search với độ phức tạp O(log n) hiệu quả hơn rất nhiều cho tập dữ liệu lớn. Tuy nhiên, Binary Search không hoạt động trên dữ liệu chưa sắp xếp, và việc sắp xếp lại dữ liệu có thể tốn kém hơn là chỉ dùng Linear Search cho một lần tìm kiếm.
Bài tập ví dụ:
Đánh giá nhân viên
Trong một dự án mới, FullHouse Dev được giao nhiệm vụ phát triển một hệ thống đánh giá nhân viên tự động cho một công ty công nghệ. Họ quyết định sử dụng trí tuệ nhân tạo để phân tích hiệu suất làm việc của nhân viên. Robot AI của họ được lập trình để đánh giá nhân viên dựa trên số giờ làm việc trong \(N\) ngày làm việc gần đây nhất.
Bài toán
Bạn là quản lý của một công ty IT. Dựa trên hiệu suất làm việc trong \(N\) ngày làm việc gần đây, bạn cần đánh giá nhân viên của mình. Bạn được cung cấp một mảng \(N\) số nguyên gọi là workload, trong đó workload[i] đại diện cho số giờ nhân viên đã làm việc vào ngày thứ i. Nhân viên phải được đánh giá theo tiêu chí sau:
Đánh giá = số ngày làm việc liên tiếp tối đa mà nhân viên đã làm việc hơn 6 giờ.
INPUT FORMAT:
- Dòng đầu tiên chứa một số nguyên \(N\) biểu thị số ngày làm việc.
- Dòng thứ hai chứa một mảng số nguyên workload được phân tách bằng dấu cách, trong đó workload[i] biểu thị số giờ nhân viên đã làm việc vào ngày thứ i.
OUTPUT FORMAT:
- In ra đánh giá của nhân viên.
Ràng buộc:
- \(1 \leq N \leq 10^5\)
- \(0 \leq \text{workload}[i] \leq 24\)
Ví dụ
INPUT
7
3 7 8 12 4 9 8OUTPUT
3Giải thích
Workload với số giờ liên tiếp > 6 = [7 8 12 4 9 8] => Khoảng thời gian dài nhất = [7 8 12]
Do đó, kết quả trả về là 3.
FullHouse Dev đã thành công trong việc phát triển hệ thống đánh giá nhân viên tự động này, giúp công ty công nghệ đối tác có thể đánh giá hiệu quả và công bằng hiệu suất làm việc của nhân viên dựa trên dữ liệu thực tế. Chào bạn, đây là hướng dẫn giải bài toán "Đánh giá nhân viên" bằng C++ một cách ngắn gọn:
- Đọc dữ liệu: Đọc số ngày
N. Sau đó đọcNsố giờ làm việc vào một mảng hoặc vector. - Khởi tạo: Dùng hai biến kiểu số nguyên: một biến để đếm số ngày liên tiếp hiện tại mà nhân viên làm việc trên 6 giờ (
current_streak) và một biến để lưu trữ số ngày liên tiếp tối đa tìm được cho đến nay (max_streak). Khởi tạo cả hai biến bằng 0. - Lặp và kiểm tra: Duyệt qua từng ngày trong mảng giờ làm việc.
- Với mỗi ngày, kiểm tra xem số giờ làm việc có lớn hơn 6 hay không.
- Nếu số giờ làm việc lớn hơn 6: Tăng biến
current_streaklên 1. Cập nhậtmax_streaknếucurrent_streakhiện tại lớn hơnmax_streak. - Nếu số giờ làm việc không lớn hơn 6: Đặt lại biến
current_streakvề 0 (vì chuỗi liên tiếp bị ngắt).
- Kết quả: Sau khi duyệt hết tất cả
Nngày, giá trị của biếnmax_streakchính là kết quả cần tìm. In giá trị này ra màn hình.
Làm thêm nhiều bài tập miễn phí tại đây
Khóa học liên quan
 Giảm giá!
Giảm giá!
Comments