Bài 14.3. Quick Sort đệ quy đuôi và không đệ quy
Bài 14.3. Quick Sort đệ quy đuôi và không đệ quy
Chào mừng trở lại với series blog về Cấu trúc dữ liệu và Giải thuật! Trong các bài trước, chúng ta có lẽ đã làm quen với một trong những thuật toán sắp xếp phổ biến và hiệu quả nhất: Quick Sort. Với nguyên tắc "chia để trị" (divide and conquer), Quick Sort hoạt động bằng cách chọn một phần tử gọi là pivot, phân hoạch (partition) mảng xung quanh pivot đó (các phần tử nhỏ hơn hoặc bằng pivot sang một bên, lớn hơn sang bên còn lại), rồi đệ quy sắp xếp hai mảng con.
Phiên bản Quick Sort cơ bản thường được trình bày dưới dạng đệ quy. Tuy nhiên, giống như nhiều thuật toán đệ quy khác, nó có thể gặp vấn đề về chiều sâu stack gọi hàm, đặc biệt trong trường hợp xấu nhất khi lựa chọn pivot không tối ưu. Để giải quyết điều này, chúng ta có thể biến đổi nó thành phiên bản đệ quy đuôi (tail recursion) hoặc hoàn toàn không đệ quy (iterative). Bài viết này sẽ đi sâu vào hai kỹ thuật tối ưu và biến thể thú vị này của Quick Sort.
Nhắc lại: Quick Sort Đệ quy Cơ bản
Trước khi khám phá các biến thể, hãy cùng xem lại Quick Sort đệ quy truyền thống. Cốt lõi của Quick Sort nằm ở hàm partition.
Hàm Partition
Hàm partition nhận một mảng con (xác định bởi chỉ số low và high), chọn một phần tử làm pivot (thường là phần tử cuối cùng), và sắp xếp lại mảng con đó sao cho tất cả các phần tử nhỏ hơn hoặc bằng pivot nằm trước pivot, và tất cả các phần tử lớn hơn pivot nằm sau pivot. Hàm trả về chỉ số cuối cùng của vùng các phần tử nhỏ hơn hoặc bằng pivot (vị trí cuối cùng của pivot sau khi đổi chỗ).
Chúng ta sẽ sử dụng phiên bản Lomuto partition scheme cho dễ hình dung:
#include <iostream>
#include <vector> // Có thể dùng mảng C-style hoặc std::vector
#include <stack> // Cần cho phiên bản không đệ quy
#include <utility> // Cần cho std::pair trong stack
// Hàm đổi chỗ hai phần tử
void swap(int* a, int* b) {
int t = *a;
*a = *b;
*b = t;
}
/*
Hàm này lấy phần tử cuối cùng làm pivot,
đặt phần tử pivot vào đúng vị trí trong mảng đã sắp xếp,
và đặt tất cả các phần tử nhỏ hơn (nhỏ hơn hoặc bằng) pivot
về bên trái của pivot, và tất cả các phần tử lớn hơn
về bên phải của pivot.
*/
int partition(int arr[], int low, int high) {
int pivot = arr[high]; // Chọn pivot là phần tử cuối cùng
int i = (low - 1); // Chỉ số của phần tử nhỏ hơn
// Duyệt từ đầu mảng con đến trước pivot
for (int j = low; j <= high - 1; j++) {
// Nếu phần tử hiện tại nhỏ hơn hoặc bằng pivot
if (arr[j] <= pivot) {
i++; // Tăng chỉ số của phần tử nhỏ hơn
swap(&arr[i], &arr[j]); // Đổi chỗ arr[i] và arr[j]
}
}
// Đổi chỗ pivot (arr[high]) với phần tử đầu tiên của vùng lớn hơn (hoặc bằng)
swap(&arr[i + 1], &arr[high]);
return (i + 1); // Trả về chỉ số của pivot sau khi phân hoạch
}
Giải thích hàm partition:
- Chúng ta chọn phần tử cuối cùng
arr[high]làm pivot. - Biến
itheo dõi ranh giới kết thúc của vùng "nhỏ hơn hoặc bằng pivot". Ban đầu, vùng này trống rỗng nêniđược đặt làlow - 1. - Chúng ta dùng một vòng lặp với chỉ số
jđể duyệt qua các phần tử từlowđếnhigh - 1. - Nếu
arr[j]nhỏ hơn hoặc bằngpivot, điều đó có nghĩa nó thuộc về vùng bên trái của pivot. Ta tăngilên 1 để mở rộng vùng "nhỏ hơn hoặc bằng pivot" và đổi chỗarr[i]vớiarr[j]. Mục đích là đưaarr[j]vào đúng vị trí trong vùng bên trái. - Sau khi vòng lặp kết thúc, tất cả các phần tử từ
lowđếniđều nhỏ hơn hoặc bằng pivot. Vị tríi + 1là nơi mà phần tử đầu tiên lớn hơn pivot nên đứng. - Cuối cùng, ta đổi chỗ pivot (đang ở
arr[high]) với phần tử tạiarr[i + 1]. Lúc này, pivot đã ở đúng vị trí cuối cùng của vùng "nhỏ hơn hoặc bằng pivot", và tất cả các phần tử bên trái nó nhỏ hơn hoặc bằng nó, tất cả các phần tử bên phải nó lớn hơn nó. - Hàm trả về
i + 1, là chỉ số của pivot sau khi phân hoạch.
Hàm Quick Sort Đệ quy
Với hàm partition, Quick Sort đệ quy trở nên đơn giản:
/*
Hàm chính thực hiện QuickSort đệ quy cơ bản
arr[]: Mảng cần sắp xếp
low: Chỉ số bắt đầu của mảng con
high: Chỉ số kết thúc của mảng con
*/
void quickSortRecursive(int arr[], int low, int high) {
// Điều kiện dừng: khi mảng con có 0 hoặc 1 phần tử
if (low < high) {
/* pi là chỉ số phân hoạch, arr[pi] hiện tại nằm
ở đúng vị trí của nó */
int pi = partition(arr, low, high);
// Sắp xếp đệ quy các phần tử trước
// và sau chỉ số phân hoạch
quickSortRecursive(arr, low, pi - 1); // Đệ quy mảng con bên trái
quickSortRecursive(arr, pi + 1, high); // Đệ quy mảng con bên phải
}
}
Giải thích hàm quickSortRecursive:
- Hàm là đệ quy, gọi chính nó cho các mảng con.
- Điều kiện cơ sở để dừng đệ quy là
low >= high, tức là mảng con hiện tại rỗng hoặc chỉ có một phần tử (đã tự sắp xếp). - Nếu
low < high, mảng con cần được xử lý. - Gọi
partition(arr, low, high)để phân hoạch mảng con. Hàm trả vềpi, chỉ số của pivot sau khi phân hoạch. - Pivot
arr[pi]hiện đã ở đúng vị trí cuối cùng của nó trong mảng đã sắp xếp. - Ta gọi đệ quy cho hai mảng con:
arr[low...pi-1](các phần tử bên trái pivot) vàarr[pi+1...high](các phần tử bên phải pivot). - Hai lời gọi đệ quy này sẽ tiếp tục chia nhỏ các mảng con cho đến khi toàn bộ mảng được sắp xếp.
Đây là phiên bản Quick Sort mà chúng ta thường thấy. Nó trực quan và dễ hiểu, nhưng điểm yếu là chiều sâu của stack đệ quy có thể lên tới O(N) trong trường hợp xấu nhất (khi mảng đã gần sắp xếp hoặc ngược thứ tự và pivot luôn là phần tử nhỏ nhất hoặc lớn nhất), dẫn đến nguy cơ tràn stack (stack overflow) với mảng có kích thước rất lớn.
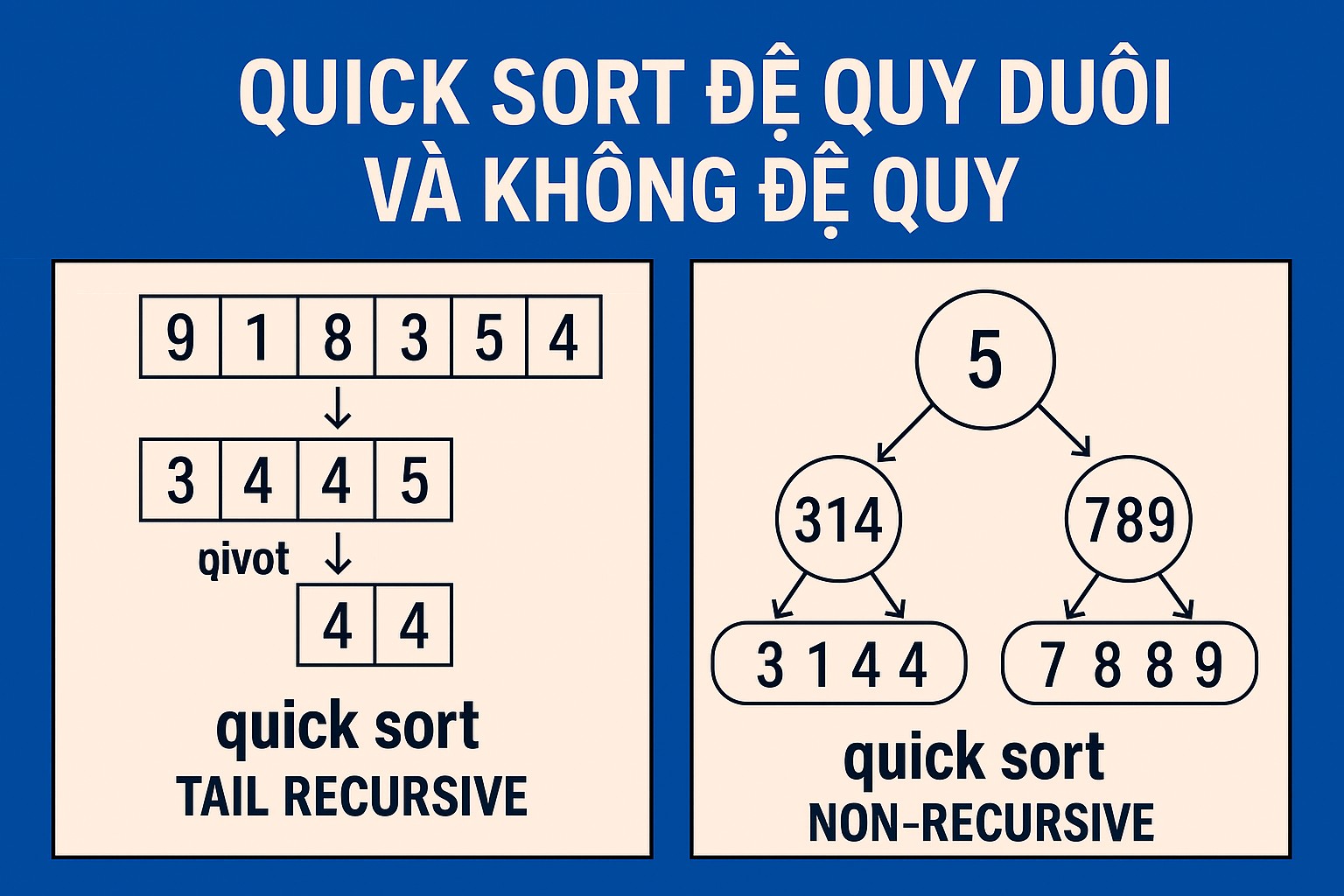
Quick Sort Đệ quy Đuôi (Tail-Recursive Quick Sort)
Khái niệm "đệ quy đuôi" (tail recursion) ám chỉ một lời gọi đệ quy là hành động cuối cùng được thực hiện bởi hàm. Trong một số ngôn ngữ và trình biên dịch hiện đại, lời gọi đệ quy đuôi có thể được tối ưu hóa thành một vòng lặp, giúp tiết kiệm không gian stack bằng cách tái sử dụng khung stack hiện tại thay vì tạo mới.
Quick Sort tiêu chuẩn có hai lời gọi đệ quy, nên không phải là đệ quy đuôi thuần túy. Tuy nhiên, chúng ta có thể biến đổi nó để một trong hai lời gọi đệ quy trở thành đệ quy đuôi và áp dụng kỹ thuật tối ưu stack. Ý tưởng là luôn xử lý mảng con nhỏ hơn bằng đệ quy và xử lý mảng con lớn hơn bằng cách cập nhật các chỉ số low hoặc high và tiếp tục vòng lặp. Bằng cách này, chiều sâu stack tối đa sẽ chỉ bị giới hạn bởi kích thước của mảng con nhỏ hơn, trung bình là O(log N), ngay cả khi trình biên dịch không hỗ trợ tối ưu đệ quy đuôi hoàn toàn.
/*
Hàm Quick Sort sử dụng kỹ thuật đệ quy đuôi tối ưu stack
arr[]: Mảng cần sắp xếp
low: Chỉ số bắt đầu của mảng con
high: Chỉ số kết thúc của mảng con
*/
void quickSortTailRecursive(int arr[], int low, int high) {
// Lặp trong khi mảng con có ít nhất 2 phần tử
while (low < high) {
// pi là chỉ số phân hoạch, arr[pi] hiện tại nằm
// ở đúng vị trí của nó
int pi = partition(arr, low, high);
// **Kỹ thuật tối ưu:**
// So sánh kích thước hai mảng con.
// Đệ quy xử lý mảng con nhỏ hơn
// Lặp xử lý mảng con lớn hơn bằng cách cập nhật ranh giới
if (pi - low < high - pi) { // Nếu mảng con bên trái (low đến pi-1) nhỏ hơn
// Xử lý mảng con bên trái bằng đệ quy
quickSortTailRecursive(arr, low, pi - 1);
// Cập nhật ranh giới để xử lý mảng con bên phải
// trong lần lặp kế tiếp (thay thế lời gọi đệ quy thứ hai)
low = pi + 1;
} else { // Nếu mảng con bên phải (pi+1 đến high) nhỏ hơn hoặc bằng
// Xử lý mảng con bên phải bằng đệ quy
quickSortTailRecursive(arr, pi + 1, high);
// Cập nhật ranh giới để xử lý mảng con bên trái
// trong lần lặp kế tiếp (thay thế lời gọi đệ quy thứ hai)
high = pi - 1;
}
}
}
Giải thích hàm quickSortTailRecursive:
- Thay vì gọi đệ quy hai lần một cách độc lập, chúng ta sử dụng một vòng lặp
while (low < high). Mỗi lần lặp xử lý một phân hoạch chính và chuẩn bị cho phân hoạch tiếp theo. - Sau khi gọi
partition(arr, low, high)và nhận được vị trípicủa pivot, chúng ta cần xử lý hai mảng conarr[low...pi-1]vàarr[pi+1...high]. - Chúng ta so sánh kích thước của hai mảng con này:
pi - low(kích thước mảng trái) vàhigh - pi(kích thước mảng phải). - Nếu mảng con bên trái nhỏ hơn: Chúng ta gọi đệ quy ngay lập tức cho mảng con bên trái:
quickSortTailRecursive(arr, low, pi - 1);. Đây là lời gọi đệ quy duy nhất trong nhánh này. Sau khi lời gọi này kết thúc, chúng ta cập nhật chỉ sốlowthànhpi + 1. Vòng lặpwhilesẽ kiểm tra điều kiệnlow < highmới (tức là phạm viarr[pi+1...high]) và nếu hợp lệ, nó sẽ tiếp tục phân hoạch và xử lý mảng con bên phải trong lần lặp kế tiếp. Kỹ thuật này thay thế lời gọi đệ quy thứ hai bằng một bước lặp. - Ngược lại (mảng con bên phải nhỏ hơn hoặc bằng): Chúng ta gọi đệ quy cho mảng con bên phải:
quickSortTailRecursive(arr, pi + 1, high);. Sau đó, cập nhật chỉ sốhighthànhpi - 1. Vòng lặpwhilesẽ tiếp tục với mảng con bên tráiarr[low...pi-1]trong lần lặp kế tiếp. - Bằng cách luôn đệ quy trên phần nhỏ hơn và lặp trên phần lớn hơn, chúng ta đảm bảo rằng chiều sâu tối đa của stack đệ quy bị giới hạn bởi kích thước của mảng con nhỏ nhất ở mỗi bước, dẫn đến chiều sâu stack trung bình là O(log N). Trong trường hợp xấu nhất (ví dụ mảng đã sắp xếp ngược), mảng con lớn nhất vẫn là O(N), nhưng chúng ta đã chọn xử lý phần nhỏ hơn bằng đệ quy, do đó chiều sâu stack vẫn được giảm thiểu so với phiên bản đệ quy cơ bản trong trường hợp xấu nhất.
Phiên bản này giữ lại một chút tính chất đệ quy nhưng tối ưu đáng kể việc sử dụng stack so với phiên bản gốc, đặc biệt hữu ích khi sắp xếp các mảng rất lớn hoặc trong môi trường có giới hạn về stack, ngay cả khi trình biên dịch không thực hiện tối ưu đệ quy đuôi hoàn hảo.
Quick Sort Không Đệ quy (Iterative Quick Sort)
Đối với những trường hợp muốn loại bỏ hoàn toàn đệ quy (có thể để kiểm soát bộ nhớ stack chặt chẽ hơn, hoặc đơn giản là thích phong cách lặp), chúng ta có thể triển khai Quick Sort một cách không đệ quy bằng cách sử dụng một cấu trúc dữ liệu stack tường minh. Stack này sẽ lưu trữ các cặp chỉ số (low, high) đại diện cho các mảng con cần được sắp xếp.
Quy trình sẽ là:
- Khởi tạo một stack rỗng.
- Đưa cặp chỉ số của toàn bộ mảng cần sắp xếp (
0,N-1) vào stack. Trong khi stack chưa rỗng:
- Lấy (pop) một cặp chỉ số (
low,high) ra khỏi đỉnh stack. - Nếu
low < high(phạm vi hợp lệ):- Thực hiện phân hoạch (
partition) trên mảng conarr[low...high]. Hàm trả về vị trípicủa pivot. - Lúc này, hai mảng con cần xử lý tiếp là
arr[low...pi-1]vàarr[pi+1...high]. - Đẩy hai cặp chỉ số của hai mảng con này (
low,pi-1) và (pi+1,high) vào lại stack nếu chúng là các mảng con hợp lệ (tức là có ít nhất một phần tử,low < high).
- Thực hiện phân hoạch (
Lưu ý về thứ tự đẩy vào stack: Để mô phỏng và tận dụng lợi ích tối ưu stack như phiên bản đệ quy đuôi, chúng ta nên đẩy mảng con lớn hơn vào stack trước, để khi pop ra, mảng con nhỏ hơn sẽ được xử lý trước. Điều này giới hạn kích thước tối đa của stack tường minh xuống O(log N) trong trường hợp trung bình.
- Lấy (pop) một cặp chỉ số (
/*
Hàm Quick Sort không đệ quy sử dụng stack tường minh
arr[]: Mảng cần sắp xếp
n: Kích thước mảng
*/
void quickSortIterative(int arr[], int n) {
// Tạo một stack để lưu trữ các cặp chỉ số (low, high)
std::stack<std::pair<int, int>> s;
// Đẩy toàn bộ mảng ban đầu vào stack
s.push({0, n - 1});
// Lặp trong khi stack không rỗng
while (!s.empty()) {
// Lấy phạm vi cần xử lý từ đỉnh stack
int low = s.top().first;
int high = s.top().second;
s.pop(); // Bỏ phạm vi này khỏi stack
// Nếu phạm vi hợp lệ (có ít nhất 2 phần tử)
if (low < high) {
// Thực hiện phân hoạch trên mảng con arr[low...high]
int pi = partition(arr, low, high);
// **Thứ tự đẩy vào stack để tối ưu không gian:**
// Đẩy mảng con lớn hơn trước để mảng con nhỏ hơn được xử lý trước (khi pop ra).
// Kỹ thuật này giúp giới hạn chiều cao stack tối đa.
if (pi - low < high - pi) { // Nếu mảng con bên trái nhỏ hơn
// Đẩy mảng con bên phải (lớn hơn) vào stack trước
if (pi + 1 < high) s.push({pi + 1, high});
// Sau đó đẩy mảng con bên trái (nhỏ hơn) vào stack
if (pi - 1 > low) s.push({low, pi - 1});
} else { // Nếu mảng con bên phải nhỏ hơn hoặc bằng
// Đẩy mảng con bên trái (lớn hơn hoặc bằng) vào stack trước
if (pi - 1 > low) s.push({low, pi - 1});
// Sau đó đẩy mảng con bên phải (nhỏ hơn) vào stack
if (pi + 1 < high) s.push({pi + 1, high});
}
}
}
}
Giải thích hàm quickSortIterative:
- Chúng ta sử dụng
std::stack<std::pair<int, int>>từ thư viện<stack>và<utility>để lưu trữ các cặp chỉ số(low, high)đại diện cho các mảng con cần được sắp xếp. Mỗi cặp này giống như một "nhiệm vụ" cần hoàn thành. - Ban đầu, "nhiệm vụ" sắp xếp toàn bộ mảng
(0, n-1)được đẩy vào stack. - Vòng lặp
while (!s.empty())tiếp tục cho đến khi không còn "nhiệm vụ" nào trong stack. - Trong mỗi lần lặp, chúng ta lấy (pop) cặp chỉ số
(low, high)từ đỉnh stack – đây là mảng con tiếp theo cần xử lý. - Nếu
low < high(mảng con này có ít nhất 2 phần tử), chúng ta tiến hành phân hoạch bằng hàmpartition(arr, low, high). - Sau khi có vị trí
picủa pivot, chúng ta biết pivot đã ở đúng vị trí. Hai mảng conarr[low...pi-1]vàarr[pi+1...high]cần được sắp xếp tiếp. - Thay vì gọi đệ quy, chúng ta tạo ra hai "nhiệm vụ" mới dưới dạng các cặp chỉ số
(low, pi-1)và(pi+1, high). - Chúng ta kiểm tra xem hai mảng con này có hợp lệ không (tức là có ít nhất một phần tử, ví dụ
pi-1 > lowtương đương mảng trái có ít nhất 2 phần tửlowvàpi-1, hoặc chính xác hơn làlow <= pi-1). Nếu hợp lệ, chúng được đẩy vào stack. - Việc đẩy mảng con lớn hơn vào stack trước giúp đảm bảo rằng mảng con nhỏ hơn sẽ nằm trên đỉnh stack và được xử lý trước. Chiến lược này giới hạn kích thước tối đa của stack tường minh xuống O(log N) trong trường hợp trung bình, tương tự như lợi ích của phiên bản đệ quy đuôi tối ưu.
Phiên bản không đệ quy giúp bạn kiểm soát rõ ràng việc sử dụng bộ nhớ stack, tránh được lỗi tràn stack do đệ quy sâu và có thể được ưa chuộng trong các hệ thống nhúng hoặc khi cần đảm bảo không có đệ quy.
Ví dụ Minh họa
Hãy cùng xem các phiên bản này hoạt động như thế nào với một mảng nhỏ.
#include <iostream>
#include <vector>
#include <stack>
#include <utility>
// (Copy hàm swap, partition, quickSortRecursive, quickSortTailRecursive, quickSortIterative vào đây)
// ... swap function ...
// ... partition function ...
// ... quickSortRecursive function ...
// ... quickSortTailRecursive function ...
// ... quickSortIterative function ...
// Hàm tiện ích để in mảng
void printArray(int arr[], int size) {
for (int i = 0; i < size; i++)
std::cout << arr[i] << " ";
std::cout << std::endl;
}
int main() {
// --- Test QuickSort Đệ quy Cơ bản ---
int arr1[] = {10, 7, 8, 9, 1, 5};
int n1 = sizeof(arr1) / sizeof(arr1[0]);
std::cout << "--- Test De Quy Co Ban ---" << std::endl;
std::cout << "Mang goc: ";
printArray(arr1, n1);
quickSortRecursive(arr1, 0, n1 - 1);
std::cout << "Mang sau khi sap xep: ";
printArray(arr1, n1);
std::cout << std::endl;
// --- Test QuickSort Đệ quy Đuôi ---
int arr2[] = {10, 7, 8, 9, 1, 5}; // Reset mảng
int n2 = sizeof(arr2) / sizeof(arr2[0]);
std::cout << "--- Test De Quy Duoi ---" << std::endl;
std::cout << "Mang goc: ";
printArray(arr2, n2);
quickSortTailRecursive(arr2, 0, n2 - 1);
std::cout << "Mang sau khi sap xep: ";
printArray(arr2, n2);
std::cout << std::endl;
// --- Test QuickSort Không Đệ quy ---
int arr3[] = {10, 7, 8, 9, 1, 5}; // Reset mảng
int n3 = sizeof(arr3) / sizeof(arr3[0]);
std::cout << "--- Test Khong De Quy ---" << std::endl;
std::cout << "Mang goc: ";
printArray(arr3, n3);
quickSortIterative(arr3, n3);
std::cout << "Mang sau khi sap xep: ";
printArray(arr3, n3);
std::cout << std::endl;
// Test với mảng lớn hơn, ví dụ mảng đã sắp xếp ngược (trường hợp xấu cho pivot cuối)
// Dù test này không trực tiếp cho thấy mức sử dụng stack, nó cho thấy tính đúng đắn
// của thuật toán trên các trường hợp khác nhau.
int arr4[20];
for(int i = 0; i < 20; ++i) arr4[i] = 20 - i; // Mảng đảo ngược
std::cout << "--- Test Khong De Quy (Mang dao nguoc, kich thuoc 20) ---" << std::endl;
std::cout << "Mang goc: ";
printArray(arr4, 20);
quickSortIterative(arr4, 20);
std::cout << "Mang sau khi sap xep: ";
printArray(arr4, 20);
std::cout << std::endl;
return 0;
}
Giải thích phần main:
- Trong hàm
main, chúng ta khai báo một mảng số nguyên nhỏarr1,arr2,arr3với cùng các giá trị ban đầu. - Chúng ta in mảng gốc trước khi sắp xếp.
- Lần lượt gọi từng phiên bản của Quick Sort (
quickSortRecursive,quickSortTailRecursive,quickSortIterative) trên các bản sao riêng biệt của mảng để đảm bảo mỗi hàm bắt đầu với dữ liệu gốc. - Sau mỗi lần gọi sắp xếp, chúng ta in mảng đã được xử lý để xác nhận rằng tất cả các phiên bản đều hoạt động chính xác và cho ra kết quả giống nhau (mảng đã sắp xếp).
- Một ví dụ nhỏ với mảng lớn hơn (kích thước 20, đảo ngược) được thêm vào để cho thấy thuật toán vẫn đúng với kích thước khác và trường hợp sắp xếp ngược. Mặc dù để thấy rõ sự khác biệt về stack, bạn cần một mảng cực lớn hoặc sử dụng các công cụ debug đặc biệt để theo dõi mức sử dụng stack. Tuy nhiên, các code minh họa đã trình bày kỹ thuật để đạt được sự tối ưu đó.
Bài tập ví dụ:
Tìm số tiếp theo
Trong một buổi dạ tiệc hoàng gia, công chúa đã đưa ra một thử thách cho FullHouse Dev. Nàng yêu cầu họ giải quyết một bài toán đầy thú vị về dãy số. Với tinh thần quyết tâm và trí tuệ sắc bén, FullHouse Dev đã bắt tay vào phân tích và giải quyết vấn đề này.
Bài toán
FullHouse Dev được cung cấp một mảng \(A\) có độ dài \(N\). Với mỗi số nguyên \(X\) cho trước, họ cần tìm một số nguyên \(Z\) lớn hơn \(X\) và không xuất hiện trong mảng \(A\). Nhiệm vụ của họ là tìm giá trị \(Z\) nhỏ nhất thỏa mãn điều kiện trên.
INPUT FORMAT:
- Dòng đầu tiên chứa hai số nguyên \(N\) và \(Q\), cách nhau bởi dấu cách, lần lượt là số phần tử trong mảng \(A\) và số lượng truy vấn.
- Dòng thứ hai chứa \(N\) số nguyên cách nhau bởi dấu cách, biểu diễn các phần tử của mảng \(A\).
- \(Q\) dòng tiếp theo, mỗi dòng chứa một số nguyên \(X\).
OUTPUT FORMAT:
- In ra \(Q\) dòng, mỗi dòng là câu trả lời cho truy vấn tương ứng.
Ràng buộc:
- \(1 \leq N, Q \leq 10^5\)
- \(1 \leq A[i], X \leq 10^9\)
Ví dụ
INPUT
5 2
2 7 5 9 15
3
9OUTPUT
4
10Giải thích
- Đối với truy vấn đầu tiên, số nguyên nhỏ nhất lớn hơn 3 và không có trong mảng là 4.
- Đối với truy vấn thứ hai, số nguyên nhỏ nhất lớn hơn 9 và không có trong mảng là 10.
Với sự thông minh và nhanh nhẹn, FullHouse Dev đã giải quyết thành công bài toán, khiến công chúa vô cùng hài lòng và ấn tượng với tài năng của họ. Okay, đây là hướng dẫn giải bài toán "Tìm số tiếp theo" bằng C++ một cách hiệu quả, tập trung vào ý tưởng chính và cấu trúc dữ liệu cần dùng, không cung cấp code hoàn chỉnh:
Phân tích bài toán và Ràng buộc:
- Bài toán: Cho mảng
A, với mỗi truy vấnX, tìm số nguyên nhỏ nhấtZsao choZ > XvàZkhông có trongA. - Ràng buộc:
N, Q <= 10^5,A[i], X <= 10^9. Ràng buộc về kích thướcNvàQcho thấy một giải pháp O(N) hoặc O(N log N) cho mỗi truy vấn là quá chậm (tổng O(QN) hoặc O(QN log N)). Chúng ta cần một giải pháp hiệu quả hơn cho mỗi truy vấn, có thể O(log N), O(log(N+Q)) hoặc O(1) sau bước tiền xử lý. Ràng buộc về giá trị (10^9) loại trừ việc sử dụng mảng boolean trực tiếp để đánh dấu sự xuất hiện.
Ý tưởng Naive (Chưa hiệu quả):
Với mỗi truy vấn X, bắt đầu kiểm tra từ Z = X + 1, sau đó X + 2, X + 3,... Với mỗi giá trị Z, kiểm tra xem nó có tồn tại trong mảng A hay không. Số Z đầu tiên tìm được mà không có trong A chính là đáp án.
Để kiểm tra sự tồn tại của Z trong A nhanh hơn, có thể sắp xếp mảng A và dùng tìm kiếm nhị phân (O(log N)). Tuy nhiên, vòng lặp kiểm tra Z = X+1, X+2, ... có thể chạy tối đa N lần trong trường hợp xấu nhất (ví dụ: A = {X+1, X+2, ..., X+N}). Như vậy, mỗi truy vấn vẫn có thể mất O(N log N), tổng cộng O(Q * N log N), vẫn quá chậm.
Ý tưởng Tối ưu: Sử dụng cấu trúc dữ liệu để kiểm tra nhanh và "nhảy" qua các số đã xuất hiện:
Kiểm tra sự tồn hiện nhanh: Cần một cách cực nhanh để biết một số có nằm trong
Ahay không.std::unordered_settrong C++ là lựa chọn tốt nhất cho việc này. Có thể tiền xử lý bằng cách đưa tất cả các phần tử củaAvàostd::unordered_set. Việc này mất O(N) trung bình. Kiểm tra sự tồn tại sau đó mất O(1) trung bình.Tìm số tiếp theo nhỏ nhất: Vấn đề là vòng lặp
Z = X+1, Z+1, ...vẫn có thể đi qua nhiều số nếu chúng liên tiếp và đều có trongA. Cần một cách để "nhảy" qua các dãy số liên tiếp có trongA.Quan sát chính: Giả sử chúng ta đang tìm số nhỏ nhất
Zkhông có trongA, bắt đầu kiểm tra từ một sốY.- Nếu
Ykhông có trongA, thìYchính là số nhỏ nhất>= Ykhông có trongA. - Nếu
Ycó trongA, thì số nhỏ nhất>= Ykhông có trongAchắc chắn phải lớn hơnY. Cụ thể, nó phải là số nhỏ nhất>= Y+1không có trongA.
- Nếu
Áp dụng memoization: Quan sát trên dẫn đến ý tưởng sử dụng quy hoạch động hoặc đệ quy có nhớ (memoization). Chúng ta có thể định nghĩa một hàm (ví dụ:
find_next_available(Y)) trả về số nguyên nhỏ nhấtZsao choZ >= YvàZkhông có trongA.find_next_available(Y):- Nếu kết quả cho
Yđã được tính toán và lưu lại (trong một map/bảng nhớ), trả về kết quả đó ngay lập tức. - Kiểm tra xem
Ycó trongunordered_setcủaAkhông. - Nếu
Ycó trongunordered_set: Điều này có nghĩa làYkhông phải là đáp án cho những truy vấn cần số>= Y. Số nhỏ nhất không có trongAvà>= Ychính là số nhỏ nhất không có trongAvà>= Y+1. Vậy,find_next_available(Y) = find_next_available(Y + 1). Ta gọi đệ quyfind_next_available(Y + 1), lưu kết quả vào bảng nhớ choY, rồi trả về kết quả đó. - Nếu
Ykhông có trongunordered_set: Điều này có nghĩa làYchính là số nhỏ nhất không có trongAvà>= Y. Vậy,find_next_available(Y) = Y. Ta lưuYvào bảng nhớ choY, rồi trả vềY.
- Nếu kết quả cho
Cấu trúc dữ liệu cho Memoization: Do các giá trị
Ycó thể lên tới10^9 + N, chúng ta không thể dùng mảng thông thường.std::map<int, int>là lựa chọn phù hợp để lưu trữ kết quảfind_next_available(Y). Key làY, value là kết quảZ.Trả lời truy vấn: Với mỗi truy vấn
X, ta cần số nhỏ nhấtZ > Xkhông có trongA. Điều này tương đương với việc tìm số nhỏ nhấtZ >= X+1không có trongA. Do đó, câu trả lời cho truy vấnXchính là kết quả của lời gọifind_next_available(X + 1).
Cách triển khai (Không code hoàn chỉnh):
- Tạo một
std::unordered_set<int>(ví dụ:a_set) và đọc các phần tử củaAvào đó. - Tạo một
std::map<int, int>(ví dụ:memo) để làm bảng nhớ cho hàmfind_next_available. - Viết hàm đệ quy
int find_next_available(int y, unordered_set<int>& a_set, map<int, int>& memo)(hoặc truyềna_setvàmemoglobal/tĩnh).- Bên trong hàm: Kiểm tra
memo.count(y). Nếu có, trả vềmemo[y]. - Kiểm tra
a_set.count(y). - Nếu
a_setchứay:int result = find_next_available(y + 1, a_set, memo); memo[y] = result; return result; - Nếu
a_setkhông chứay:memo[y] = y; return y;
- Bên trong hàm: Kiểm tra
- Trong hàm main, sau khi đọc N, Q và điền
a_set, đọc Q truy vấnXlần lượt. Với mỗiX, gọifind_next_available(X + 1, a_set, memo)và in kết quả.
Độ phức tạp:
- Tiền xử lý (
unordered_set): O(N) trung bình. - Mỗi truy vấn: Lời gọi
find_next_available(X+1)có thể dẫn đến các lời gọi đệ quy. Tuy nhiên, nhờ có memoization, mỗi giá trịYchỉ được tính toán kết quảfind_next_available(Y)lần đầu tiên nó được gặp (hoặc được yêu cầu). Các giá trịYđược tính toán là các giá trịX_i+1ban đầu cộng với các giá trịy+1khiynằm trongAvà nằm trong một chuỗi liên tiếp được duyệt qua. Tổng số các giá trịYkhác nhau màfind_next_available(Y)cần tính toán lần đầu tiên là O(N + Q). Mỗi lần tính toán này bao gồm O(1) kiểm traunordered_set(trung bình) và O(log(N+Q)) cho các thao tác trênmap. - Tổng độ phức tạp: O(N + (N+Q) log(N+Q)). Đây là độ phức tạp phù hợp với ràng buộc của bài toán.
Làm thêm nhiều bài tập miễn phí tại đây
Khóa học liên quan
 Giảm giá!
Giảm giá!
Comments