Bài 15.4. Các biến thể cơ bản của Merge Sort
Bài 15.4. Các biến thể cơ bản của Merge Sort
Chào mừng các bạn quay trở lại với chuỗi bài viết về Cấu trúc dữ liệu và Giải thuật!
Trong bài trước, chúng ta đã cùng tìm hiểu về Merge Sort - một giải thuật sắp xếp dựa trên nguyên lý "Chia để trị" (Divide and Conquer) nổi tiếng. Chúng ta đã thấy cách nó chia mảng thành các nửa nhỏ hơn, sắp xếp chúng một cách đệ quy, và sau đó trộn (merge) các mảng con đã sắp xếp lại với nhau. Kết quả là một giải thuật ổn định, có độ phức tạp thời gian O(n log n) trong mọi trường hợp và độ phức tạp không gian O(n) (do cần mảng phụ để trộn).
Tuy nhiên, giải thuật này không chỉ tồn tại ở một dạng duy nhất. Có một số biến thể cơ bản của Merge Sort được sử dụng trong thực tế, mỗi biến thể có những ưu và nhược điểm riêng, hoặc được thiết kế để tối ưu hóa cho các trường hợp cụ thể.
Hãy cùng đi sâu vào khám phá các biến thể này nhé!
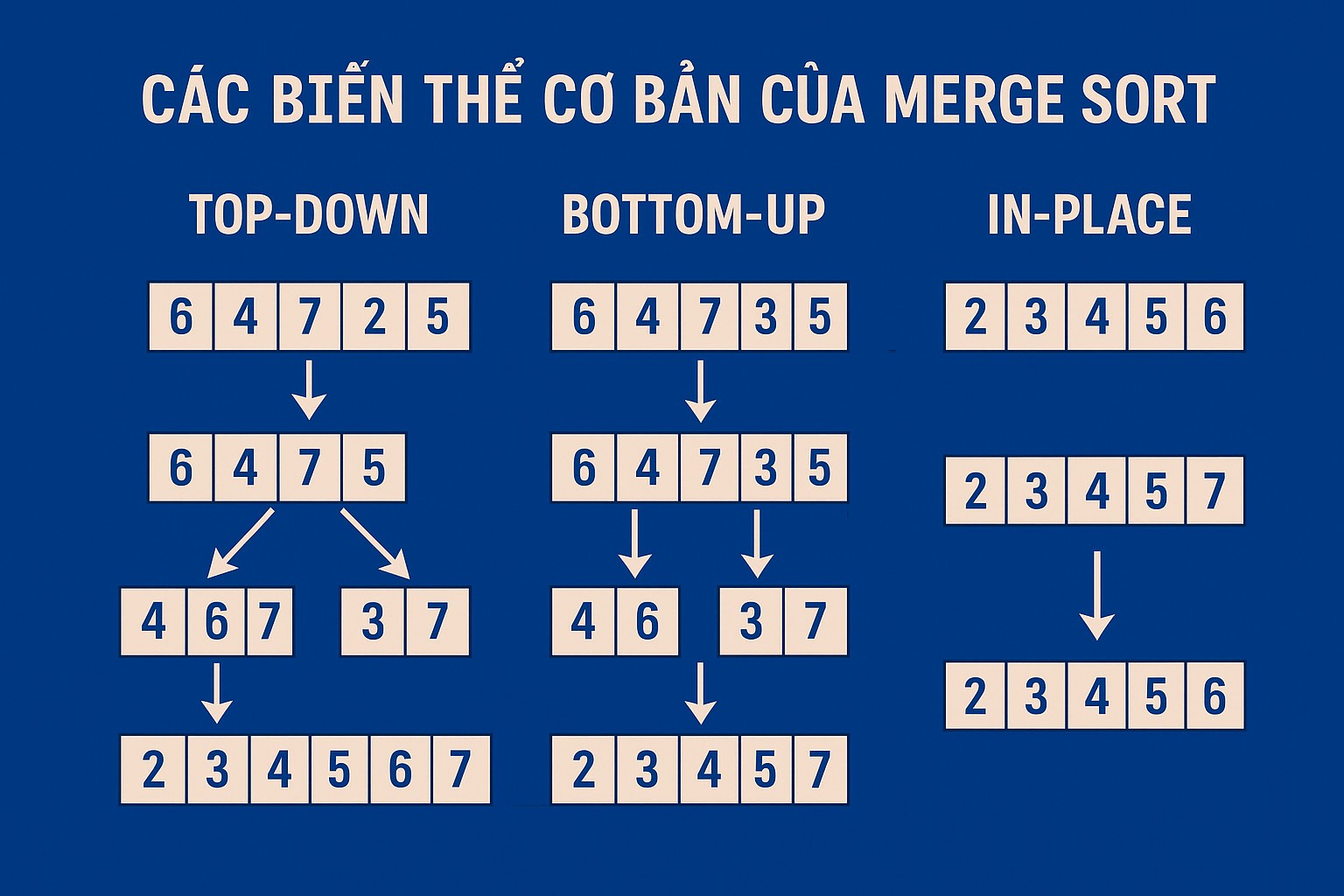
1. Merge Sort Đệ quy (Top-Down Merge Sort)
Đây chính là hình thức kinh điển và dễ hiểu nhất của Merge Sort mà chúng ta đã học. Giải thuật hoạt động theo hướng từ trên xuống, tức là bắt đầu từ mảng lớn nhất, chia nhỏ nó ra cho đến khi gặp các mảng con có kích thước bằng 1 (được coi là đã sắp xếp), sau đó mới bắt đầu quá trình trộn ngược trở lại.
Nguyên lý:
- Chia mảng: Phân chia mảng ban đầu thành hai nửa bằng nhau.
- Trị (Đệ quy): Gọi đệ quy Merge Sort cho từng nửa.
- Trộn: Trộn hai nửa đã được sắp xếp lại với nhau để tạo thành mảng con lớn hơn đã sắp xếp.
Ưu điểm: Dễ hiểu, cấu trúc code gọn gàng nhờ đệ quy.
- Nhược điểm: Tiêu tốn bộ nhớ ngăn xếp (stack space) cho các lời gọi đệ quy, có thể gây tràn ngăn xếp với mảng quá lớn (mặc dù hiếm gặp trong thực tế với kích thước mảng thông thường).
Hãy nhắc lại một chút về cài đặt của biến thể này. Chúng ta cần một hàm merge để trộn hai mảng con đã sắp xếp và một hàm mergeSort đệ quy.
#include <iostream>
#include <vector>
#include <algorithm> // Để dùng std::copy
// Hàm trộn hai mảng con đã sắp xếp
// left là chỉ số bắt đầu của mảng con thứ nhất
// mid là chỉ số kết thúc của mảng con thứ nhất (và mid + 1 là bắt đầu của mảng con thứ hai)
// right là chỉ số kết thúc của mảng con thứ hai
void merge(std::vector<int>& arr, int left, int mid, int right) {
// Tính kích thước của hai mảng con
int n1 = mid - left + 1;
int n2 = right - mid;
// Tạo mảng tạm để lưu trữ dữ liệu của hai mảng con
std::vector<int> L(n1);
std::vector<int> R(n2);
// Sao chép dữ liệu vào mảng tạm L và R
for (int i = 0; i < n1; i++)
L[i] = arr[left + i];
for (int j = 0; j < n2; j++)
R[j] = arr[mid + 1 + j];
// Biến để duyệt qua các mảng con và mảng gốc
int i = 0; // Chỉ số ban đầu của mảng con thứ nhất (L)
int j = 0; // Chỉ số ban đầu của mảng con thứ hai (R)
int k = left; // Chỉ số ban đầu của mảng gốc đã trộn
// Trộn các phần tử từ L và R vào mảng gốc arr
// So sánh phần tử ở đầu mỗi mảng con và lấy phần tử nhỏ hơn
while (i < n1 && j < n2) {
if (L[i] <= R[j]) {
arr[k] = L[i];
i++;
} else {
arr[k] = R[j];
j++;
}
k++; // Di chuyển con trỏ trong mảng gốc
}
// Sao chép các phần tử còn lại của L (nếu có)
while (i < n1) {
arr[k] = L[i];
i++;
k++;
}
// Sao chép các phần tử còn lại của R (nếu có)
while (j < n2) {
arr[k] = R[j];
j++;
k++;
}
}
// Hàm Merge Sort đệ quy
// arr: mảng cần sắp xếp
// left: chỉ số bắt đầu của mảng con
// right: chỉ số kết thúc của mảng con
void recursiveMergeSort(std::vector<int>& arr, int left, int right) {
// Điều kiện dừng đệ quy: mảng con có 0 hoặc 1 phần tử (đã sắp xếp)
if (left >= right) {
return;
}
// Tìm điểm giữa để chia mảng
int mid = left + (right - left) / 2; // Cách tính mid này tránh tràn số hơn (left+right)/2
// Gọi đệ quy sắp xếp cho hai nửa
recursiveMergeSort(arr, left, mid);
recursiveMergeSort(arr, mid + 1, right);
// Trộn hai nửa đã sắp xếp
merge(arr, left, mid, right);
}
/*
int main() {
std::vector<int> arr = {12, 11, 13, 5, 6, 7};
int arr_size = arr.size();
std::cout << "Mảng ban đầu: ";
for (int x : arr) {
std::cout << x << " ";
}
std::cout << std::endl;
recursiveMergeSort(arr, 0, arr_size - 1);
std::cout << "Mảng sau khi sắp xếp (Recursive): ";
for (int x : arr) {
std::cout << x << " ";
}
std::cout << std::endl;
return 0;
}
*/
Giải thích code:
- Hàm
mergenhận vào mảngarrvà các chỉ sốleft,mid,rightđịnh nghĩa ranh giới của hai mảng con cần trộn. Nó tạo ra hai mảng tạmLvàRđể chứa dữ liệu của hai mảng con. Sau đó, nó sử dụng ba con trỏ (i,j,k) để duyệt quaL,Rvàarrvà trộn các phần tử theo thứ tự tăng dần. Cuối cùng, sao chép các phần tử còn lại từLhoặcR(nếu có) vàoarr. - Hàm
recursiveMergeSortlà hàm đệ quy. Trường hợp cơ bản là khileft >= right, tức mảng con chỉ có 0 hoặc 1 phần tử, thì không cần làm gì cả. Nếu không, nó tính điểmmid, gọi đệ quy cho nửa trái (leftđếnmid) và nửa phải (mid + 1đếnright), rồi cuối cùng gọimergeđể trộn hai nửa đã sắp xếp lại.
Đây là nền tảng cho các biến thể khác.
2. Merge Sort Lặp (Bottom-Up Merge Sort)
Biến thể này tránh việc sử dụng đệ quy bằng cách làm việc theo hướng từ dưới lên. Thay vì chia nhỏ mảng trước, nó bắt đầu bằng cách coi các phần tử đơn lẻ là các mảng con đã sắp xếp (kích thước 1), sau đó trộn các mảng con này theo cặp để tạo ra các mảng con đã sắp xếp có kích thước 2, rồi tiếp tục trộn các mảng con kích thước 2 để tạo ra mảng con kích thước 4, cứ thế tiếp diễn cho đến khi toàn bộ mảng được trộn lại thành một mảng đã sắp xếp duy nhất.
Nguyên lý:
- Bắt đầu với các "run" (phần đã sắp xếp) có kích thước 1.
- Lặp lại: Trộn các cặp "run" cạnh nhau để tạo ra các "run" mới có kích thước gấp đôi.
- Dừng khi chỉ còn một "run" duy nhất có kích thước bằng kích thước mảng ban đầu.
Ưu điểm:
- Không sử dụng đệ quy, do đó không có overhead của ngăn xếp và tránh được lỗi tràn ngăn xếp.
- Có thể có hiệu suất tốt hơn trong một số trường hợp do tối ưu hóa cache (truy cập dữ liệu tuần tự hơn).
- Nhược điểm: Code phức tạp hơn một chút trong việc quản lý các chỉ số và kích thước của các mảng con cần trộn trong các vòng lặp.
Biến thể này sử dụng lại hàm merge từ phiên bản đệ quy, nhưng logic sắp xếp chính nằm trong các vòng lặp.
#include <iostream>
#include <vector>
#include <algorithm>
// Hàm merge (tương tự như phiên bản đệ quy)
// left là chỉ số bắt đầu của mảng con thứ nhất
// mid là chỉ số kết thúc của mảng con thứ nhất (và mid + 1 là bắt đầu của mảng con thứ hai)
// right là chỉ số kết thúc của mảng con thứ hai
void merge(std::vector<int>& arr, int left, int mid, int right) {
// ... (code hàm merge y hệt như trên) ...
int n1 = mid - left + 1;
int n2 = right - mid;
std::vector<int> L(n1);
std::vector<int> R(n2);
for (int i = 0; i < n1; i++)
L[i] = arr[left + i];
for (int j = 0; j < n2; j++)
R[j] = arr[mid + 1 + j];
int i = 0;
int j = 0;
int k = left;
while (i < n1 && j < n2) {
if (L[i] <= R[j]) {
arr[k] = L[i];
i++;
} else {
arr[k] = R[j];
j++;
}
k++;
}
while (i < n1) {
arr[k] = L[i];
i++;
k++;
}
while (j < n2) {
arr[k] = R[j];
j++;
k++;
}
}
// Hàm Merge Sort lặp (Bottom-Up)
// arr: mảng cần sắp xếp
void iterativeMergeSort(std::vector<int>& arr) {
int n = arr.size();
// Vòng lặp ngoài điều khiển kích thước của các mảng con (merge_size)
// Bắt đầu từ 1, nhân đôi sau mỗi lần lặp (1, 2, 4, 8, ...)
for (int merge_size = 1; merge_size <= n - 1; merge_size = 2 * merge_size) {
// Vòng lặp trong để chọn các cặp mảng con cần trộn
// left là chỉ số bắt đầu của mảng con thứ nhất trong cặp hiện tại
// Duyệt qua mảng với bước nhảy là 2 * merge_size (kích thước của 2 mảng con cộng lại)
for (int left = 0; left < n - 1; left += 2 * merge_size) {
// Tìm điểm giữa (mid) và điểm kết thúc (right) của hai mảng con
// Mảng con thứ nhất: từ left đến left + merge_size - 1
// Mảng con thứ hai: từ left + merge_size đến min(left + 2 * merge_size - 1, n - 1)
int mid = std::min(left + merge_size - 1, n - 1); // Điểm cuối của mảng 1
// Điểm cuối của mảng 2: có thể vượt quá giới hạn mảng, nên cần lấy min(..., n-1)
int right = std::min(left + 2 * merge_size - 1, n - 1); // Điểm cuối của mảng 2
// Chỉ trộn nếu mảng con thứ hai tồn tại (mid < right)
// Nếu mid >= right, nghĩa là chỉ có mảng con thứ nhất, hoặc mảng con thứ nhất
// có ít hơn merge_size phần tử và đã chạm đến cuối mảng, không cần trộn.
if (mid < right) {
merge(arr, left, mid, right);
}
}
}
}
/*
int main() {
std::vector<int> arr = {12, 11, 13, 5, 6, 7, 9, 8}; // Thêm vài phần tử để thấy rõ hơn
int arr_size = arr.size();
std::cout << "Mảng ban đầu: ";
for (int x : arr) {
std::cout << x << " ";
}
std::cout << std::endl;
iterativeMergeSort(arr);
std::cout << "Mảng sau khi sắp xếp (Iterative): ";
for (int x : arr) {
std::cout << x << " ";
}
std::cout << std::endl;
return 0;
}
*/
Giải thích code:
- Hàm
iterativeMergeSortsử dụng hai vòng lặp lồng nhau. - Vòng lặp ngoài (
for (int merge_size = 1; ... )) điều khiển kích thước hiện tại của các mảng con đã được coi là sắp xếp (ban đầu là 1, sau đó 2, 4, 8, ...). - Vòng lặp trong (
for (int left = 0; ... )) duyệt qua mảng để tìm các điểm bắt đầu (left) của các cặp mảng con cần trộn. Bước nhảy là2 * merge_sizevì mỗi lần trộn, chúng ta xử lý một đoạn có độ dài bằng tổng kích thước của hai mảng con. - Trong mỗi lần lặp của vòng trong, chúng ta tính
midvàrightlà các chỉ số cuối của hai mảng con trong cặp hiện tại.midlà điểm cuối của mảng con thứ nhất (bắt đầu từleft, kích thướcmerge_size).rightlà điểm cuối của mảng con thứ hai (bắt đầu từmid + 1, kích thướcmerge_size, nhưng phải đảm bảo không vượt quá cuối mảngn - 1). - Chỉ gọi
mergenếu mảng con thứ hai thực sự tồn tại trong phạm vi[mid+1, right], tức là khimid < right.
Biến thể lặp này hoàn toàn tương đương về mặt kết quả với biến thể đệ quy, nhưng thay thế sự phức tạp của ngăn xếp đệ quy bằng sự phức tạp trong logic vòng lặp và tính chỉ số.
3. Natural Merge Sort
Cả hai biến thể trên đều bỏ qua cấu trúc tự nhiên của dữ liệu ban đầu. Chúng luôn chia mảng thành các nửa có kích thước cố định hoặc trộn các đoạn có kích thước cố định (1, 2, 4, ...). Natural Merge Sort lại tận dụng lợi thế của các "run" - các đoạn dữ liệu đã được sắp xếp sẵn có trong mảng ban đầu.
Ví dụ: Mảng [3, 4, 2, 1, 5, 6, 7, 8, 9, 10, 1]
Các run tự nhiên là:
[3, 4][2][1, 5, 6, 7, 8, 9, 10][1]
Natural Merge Sort sẽ tìm các run này và sau đó trộn các run kề nhau. Điều này có thể giảm đáng kể số lần trộn và số lượng dữ liệu cần xử lý nếu mảng ban đầu đã gần sắp xếp hoặc chứa nhiều run dài.
Nguyên lý:
- Quét mảng để xác định vị trí kết thúc của tất cả các "run" tự nhiên.
- Lưu trữ danh sách các run (ví dụ: chỉ số bắt đầu và kết thúc của mỗi run).
- Lặp lại: Lấy hai run đầu tiên từ danh sách, trộn chúng bằng hàm
merge, và đưa run kết quả vào cuối danh sách. - Dừng khi chỉ còn một run duy nhất trong danh sách (đó là toàn bộ mảng đã sắp xếp).
Ưu điểm:
- Rất hiệu quả trên dữ liệu đã gần sắp xếp.
- Tránh được nhiều thao tác trộn không cần thiết so với Merge Sort truyền thống nếu có nhiều run dài.
- Nhược điểm:
- Cần thêm logic để tìm và quản lý các run (thường dùng một danh sách liên kết hoặc queue để lưu trữ các run).
- Hiệu suất tương đương với Merge Sort truyền thống trên dữ liệu ngẫu nhiên.
Đây là biến thể phức tạp hơn một chút để cài đặt đầy đủ vì nó đòi hỏi việc quản lý các run. Tuy nhiên, ý tưởng cốt lõi vẫn là sử dụng hàm merge trên các đoạn dữ liệu được xác định là run.
Hãy xem xét cài đặt một phiên bản đơn giản của Natural Merge Sort, tập trung vào việc tìm run và sử dụng hàm merge.
#include <iostream>
#include <vector>
#include <algorithm>
#include <list> // Sử dụng list để quản lý các run
// Hàm merge (tương tự như phiên bản đệ quy và lặp)
// ... (code hàm merge y hệt như trên) ...
void merge(std::vector<int>& arr, int left, int mid, int right) {
int n1 = mid - left + 1;
int n2 = right - mid;
std::vector<int> L(n1);
std::vector<int> R(n2);
for (int i = 0; i < n1; i++)
L[i] = arr[left + i];
for (int j = 0; j < n2; j++)
R[j] = arr[mid + 1 + j];
int i = 0;
int j = 0;
int k = left;
while (i < n1 && j < n2) {
if (L[i] <= R[j]) {
arr[k] = L[i];
i++;
} else {
arr[k] = R[j];
j++;
}
k++;
}
while (i < n1) {
arr[k] = L[i];
i++;
k++;
}
while (j < n2) {
arr[k] = R[j];
j++;
k++;
}
}
// Tìm điểm kết thúc của một run (đoạn đã sắp xếp) bắt đầu từ chỉ số start
// Trả về chỉ số cuối cùng của run (bao gồm cả start)
int findRunEnd(const std::vector<int>& arr, int start, int n) {
int end = start;
// Run phải có ít nhất 1 phần tử
if (start < n) {
// Tăng end miễn là phần tử hiện tại nhỏ hơn hoặc bằng phần tử kế tiếp
while (end + 1 < n && arr[end] <= arr[end + 1]) {
end++;
}
}
return end;
}
// Hàm Natural Merge Sort
void naturalMergeSort(std::vector<int>& arr) {
int n = arr.size();
if (n <= 1) return; // Mảng có 0 hoặc 1 phần tử đã sắp xếp
// Sử dụng một list để lưu trữ các run. Mỗi element trong list là chỉ số bắt đầu của một run.
// Chúng ta không cần lưu chỉ số kết thúc vì có thể tìm lại bằng findRunEnd.
std::list<int> runs;
int current = 0;
while (current < n) {
runs.push_back(current);
current = findRunEnd(arr, current, n) + 1;
}
// Lặp lại quá trình trộn cho đến khi chỉ còn 1 run duy nhất
while (runs.size() > 1) {
// Lấy ra chỉ số bắt đầu của hai run đầu tiên
int left = runs.front(); runs.pop_front();
int mid_end = findRunEnd(arr, left, n); // Chỉ số kết thúc của run đầu tiên
int next_run_start = runs.front(); runs.pop_front();
int right_end = findRunEnd(arr, next_run_start, n); // Chỉ số kết thúc của run thứ hai
// mid_end chính là mid trong hàm merge
// next_run_start chính là mid + 1 trong hàm merge
// Trộn hai run
merge(arr, left, mid_end, right_end);
// Thêm chỉ số bắt đầu của run kết quả (là left) vào cuối danh sách
runs.push_back(left);
}
// Khi vòng lặp kết thúc, runs.front() là chỉ số bắt đầu của mảng đã sắp xếp (luôn là 0)
}
/*
int main() {
std::vector<int> arr_natural = {3, 4, 2, 1, 5, 6, 7, 8, 9, 10, 1, 11}; // Mảng có các run tự nhiên
int arr_size_natural = arr_natural.size();
std::cout << "Mảng ban đầu (Natural): ";
for (int x : arr_natural) {
std::cout << x << " ";
}
std::cout << std::endl;
naturalMergeSort(arr_natural);
std::cout << "Mảng sau khi sắp xếp (Natural): ";
for (int x : arr_natural) {
std::cout << x << " ";
}
std::cout << std::endl;
return 0;
}
*/
Giải thích code:
- Hàm
findRunEndlà helper function dùng để quét từ một điểmstartvà trả về chỉ số cuối cùng của đoạn tăng dần (run) đó. - Trong
naturalMergeSort, đầu tiên, chúng ta quét qua mảng để tìm tất cả các run ban đầu và lưu trữ chỉ số bắt đầu của chúng vào mộtstd::listcó tênruns. - Vòng lặp
while (runs.size() > 1)là trung tâm của giải thuật. Nó lặp lại cho đến khi chỉ còn một run duy nhất (toàn bộ mảng đã sắp xếp). - Trong mỗi lần lặp, nó lấy ra hai chỉ số bắt đầu của hai run đầu tiên từ
list, tìm chỉ số kết thúc của chúng bằngfindRunEnd, sau đó gọi hàmmergeđể trộn hai run này. - Sau khi trộn, mảng con từ
leftđếnright_endđã được sắp xếp. Đây là một run mới. Chỉ số bắt đầu của run mới này làleft. Chúng ta thêmleftvào cuốilist<runs>để nó có thể được trộn với các run khác trong các vòng lặp sau. - Quá trình này tiếp diễn cho đến khi chỉ còn một run duy nhất.
Natural Merge Sort là cơ sở cho các giải thuật sắp xếp thực tế hiệu quả cao như Timsort (được sử dụng trong Python, Java và Android), kết hợp Natural Merge Sort với Insertion Sort.
4. Tối ưu hóa: Sử dụng Insertion Sort cho mảng con nhỏ
Một điểm yếu của Merge Sort truyền thống (cả đệ quy và lặp) là chi phí cố định (overhead) cho mỗi lần chia nhỏ hoặc mỗi lần trộn. Khi kích thước của mảng con trở nên rất nhỏ (ví dụ: dưới 10-20 phần tử), chi phí của việc gọi đệ quy/lặp và tạo mảng tạm cho hàm merge có thể lớn hơn chi phí của một giải thuật đơn giản hơn như Insertion Sort.
Insertion Sort, mặc dù có độ phức tạp O(n^2) trong trường hợp xấu nhất, nhưng lại rất nhanh và hiệu quả cho các mảng nhỏ vì nó có overhead rất thấp.
Nguyên lý:
- Trong Merge Sort (thường áp dụng cho biến thể đệ quy), khi kích thước của mảng con cần sắp xếp giảm xuống dưới một ngưỡng (
cutoff) nhất định, thay vì gọi đệ quy tiếp, chúng ta sử dụng Insertion Sort để sắp xếp mảng con đó. - Các bước trộn vẫn diễn ra như bình thường ở các tầng cao hơn của cây đệ quy.
- Trong Merge Sort (thường áp dụng cho biến thể đệ quy), khi kích thước của mảng con cần sắp xếp giảm xuống dưới một ngưỡng (
Ưu điểm: Cải thiện hiệu suất thực tế, đặc biệt là do giảm số lượng cuộc gọi đệ quy và thao tác
mergetrên các đoạn cực nhỏ, nơi mà overhead chiếm tỷ trọng lớn.- Nhược điểm: Phải xác định một ngưỡng
cutoffphù hợp (thường phải thử nghiệm để tìm giá trị tối ưu cho từng môi trường cụ thể). Cần cài đặt thêm hàm Insertion Sort.
Để thực hiện tối ưu hóa này, chúng ta chỉ cần sửa đổi hàm recursiveMergeSort.
#include <iostream>
#include <vector>
#include <algorithm>
// Hàm merge (tương tự như các phiên bản trước)
// ... (code hàm merge y hệt như trên) ...
void merge(std::vector<int>& arr, int left, int mid, int right) {
int n1 = mid - left + 1;
int n2 = right - mid;
std::vector<int> L(n1);
std::vector<int> R(n2);
for (int i = 0; i < n1; i++)
L[i] = arr[left + i];
for (int j = 0; j < n2; j++)
R[j] = arr[mid + 1 + j];
int i = 0;
int j = 0;
int k = left;
while (i < n1 && j < n2) {
if (L[i] <= R[j]) {
arr[k] = L[i];
i++;
} else {
arr[k] = R[j];
j++;
}
k++;
}
while (i < n1) {
arr[k] = L[i];
i++;
k++;
}
while (j < n2) {
arr[k] = R[j];
j++;
k++;
}
}
// Hàm Insertion Sort cho một mảng con từ left đến right
void insertionSort(std::vector<int>& arr, int left, int right) {
for (int i = left + 1; i <= right; i++) {
int key = arr[i];
int j = i - 1;
// Di chuyển các phần tử lớn hơn key về phía sau
while (j >= left && arr[j] > key) {
arr[j + 1] = arr[j];
j--;
}
arr[j + 1] = key; // Chèn key vào đúng vị trí
}
}
// Ngưỡng kích thước mảng con để chuyển sang Insertion Sort
const int INSERTION_SORT_CUTOFF = 10; // Giá trị có thể điều chỉnh
// Hàm Merge Sort đệ quy được tối ưu hóa
void optimizedRecursiveMergeSort(std::vector<int>& arr, int left, int right) {
// Nếu kích thước mảng con nhỏ hơn hoặc bằng ngưỡng, dùng Insertion Sort
if (right - left + 1 <= INSERTION_SORT_CUTOFF) {
insertionSort(arr, left, right);
return;
}
// Nếu không, tiếp tục chia và gọi đệ quy như Merge Sort truyền thống
int mid = left + (right - left) / 2;
optimizedRecursiveMergeSort(arr, left, mid);
optimizedRecursiveMergeSort(arr, mid + 1, right);
// Trộn hai nửa đã sắp xếp
merge(arr, left, mid, right);
}
/*
int main() {
std::vector<int> arr_optimized = {12, 11, 13, 5, 6, 7, 9, 8, 1, 4, 2, 10, 15, 0};
int arr_size_optimized = arr_optimized.size();
std::cout << "Mảng ban đầu (Optimized): ";
for (int x : arr_optimized) {
std::cout << x << " ";
}
std::cout << std::endl;
optimizedRecursiveMergeSort(arr_optimized, 0, arr_size_optimized - 1);
std::cout << "Mảng sau khi sắp xếp (Optimized): ";
for (int x : arr_optimized) {
std::cout << x << " ";
}
std::cout << std::endl;
return 0;
}
*/
Giải thích code:
- Chúng ta thêm hàm
insertionSortnhận vào mảngarrvà phạm vileft,right. Hàm này hoạt động tương tự như Insertion Sort thông thường nhưng chỉ trên một phần của mảng. - Trong
optimizedRecursiveMergeSort, chúng ta thêm một điều kiệnif (right - left + 1 <= INSERTION_SORT_CUTOFF). Nếu kích thước của mảng con hiện tại (right - left + 1) nhỏ hơn hoặc bằng hằng sốINSERTION_SORT_CUTOFF, chúng ta gọiinsertionSorttrên mảng con đó và kết thúc lời gọi đệ quy. - Nếu kích thước lớn hơn ngưỡng, giải thuật tiếp tục hoạt động như Merge Sort đệ quy ban đầu.
Việc tối ưu hóa này là rất phổ biến trong các cài đặt Merge Sort thực tế và cũng là một phần quan trọng của Timsort.
Bài tập ví dụ:
Dãy lá kỳ diệu
Trong một chuyến dã ngoại đến rừng già, FullHouse Dev đã phát hiện ra một loài cây kỳ lạ với những chiếc lá có độ chênh lệch độ dài đặc biệt. Điều này khiến họ nghĩ đến một bài toán thú vị về dãy số và độ chênh lệch giữa các phần tử.
Bài toán
Cho một mảng \(A\) gồm \(N\) số nguyên. Một dãy con của mảng được gọi là "tốt" nếu mọi cặp phần tử trong dãy con đó có độ chênh lệch tuyệt đối không quá 10.
Nhiệm vụ
Xác định độ dài tối đa có thể của dãy con "tốt".
INPUT FORMAT:
- Dòng đầu tiên chứa một số nguyên \(N\).
- Dòng thứ hai chứa một mảng \(A\) gồm \(N\) số nguyên.
OUTPUT FORMAT:
- In ra độ dài tối đa có thể của dãy con "tốt".
Ràng buộc:
- \(1 \leq N \leq 10^5\)
- \(1 \leq A[i] \leq 10^9\)
VÍ DỤ
INPUT
10
4 5 10 101 2 129 131 130 118 14OUTPUT
4Giải thích
Trong ví dụ này:
- Dãy con [4, 5, 10, 14] là "tốt" và có độ dài tối đa.
- Vì vậy, kết quả là 4.
FullHouse Dev nhận ra rằng bài toán này giống như việc chọn những chiếc lá có độ dài tương đồng nhất từ cây kỳ lạ họ vừa phát hiện. Họ quyết định áp dụng kiến thức lập trình của mình để giải quyết vấn đề này, biến một hiện tượng tự nhiên thành một thử thách lập trình thú vị. Tuyệt vời! Đây là cách tiếp cận bài toán "Dãy lá kỳ diệu" một cách hiệu quả bằng C++ mà không cần cung cấp code hoàn chỉnh:
Phân tích yêu cầu: Chúng ta cần tìm dãy con dài nhất (không nhất thiết liên tục trong mảng gốc) mà bất kỳ hai phần tử nào trong đó có độ chênh lệch tuyệt đối không quá 10.
Nhận xét quan trọng: Nếu một tập hợp các số thỏa mãn điều kiện "độ chênh lệch tuyệt đối giữa mọi cặp không quá 10", thì sự chênh lệch giữa số lớn nhất và số nhỏ nhất trong tập hợp đó cũng không quá 10. Ngược lại, nếu sự chênh lệch giữa số lớn nhất và số nhỏ nhất trong một tập hợp không quá 10, thì sự chênh lệch giữa bất kỳ hai số nào trong tập hợp đó cũng không quá 10. Điều này có nghĩa là, một dãy con là "tốt" khi và chỉ khi hiệu giữa phần tử lớn nhất và phần tử nhỏ nhất trong dãy con đó không vượt quá 10.
Ý tưởng chính: Dựa vào nhận xét trên, bài toán trở thành tìm tập hợp con các phần tử từ mảng gốc có kích thước lớn nhất sao cho hiệu của phần tử lớn nhất và nhỏ nhất trong tập hợp con đó <= 10. Việc làm việc với các tập hợp con không liên tục trong mảng gốc là phức tạp.
Sắp xếp giúp ích: Hãy thử sắp xếp mảng gốc
A. Gọi mảng đã sắp xếp làB. Nếu chúng ta chọn một tập hợp các phần tử từAtạo thành một dãy con "tốt", thì khi các phần tử này được sắp xếp, chúng sẽ tạo thành một dãy các số liên tục trong mảngB. Ví dụ, nếuA = [4, 5, 10, 14](đây đã là dãy tốt), mảng sắp xếp làB = [2, 4, 5, 10, 14, 101, ...]. Dãy con tốt[4, 5, 10, 14]xuất hiện như một đoạn liên tục trong mảngB.Chuyển bài toán: Bài toán gốc tương đương với việc tìm đoạn con liên tục dài nhất trong mảng
B(đã sắp xếp) sao cho hiệu giữa phần tử cuối cùng và phần tử đầu tiên của đoạn con đó không vượt quá 10.Thuật toán hiệu quả: Trên mảng đã sắp xếp
B, chúng ta có thể sử dụng kỹ thuật hai con trỏ (hoặc cửa sổ trượt) để tìm đoạn con liên tục dài nhất thỏa mãn điều kiện.- Duy trì hai con trỏ,
leftvàright, đại diện cho ranh giới của cửa sổ trượt (B[left...right]). - Tăng con trỏ
rightđể mở rộng cửa sổ. - Tại mỗi bước tăng
right, kiểm tra điều kiện:B[right] - B[left] <= 10. - Nếu điều kiện không thỏa mãn (
B[right] - B[left] > 10), có nghĩa là phần tửB[right]quá xa so vớiB[left]. Chúng ta cần thu nhỏ cửa sổ từ bên trái bằng cách tăng con trỏleftcho đến khi điều kiệnB[right] - B[left] <= 10được thỏa mãn trở lại (hoặcleftvượt quaright). - Độ dài của cửa sổ hiện tại là
right - left + 1. Cập nhật độ dài tối đa tìm được. - Lặp lại cho đến khi
rightduyệt hết mảng.
- Duy trì hai con trỏ,
Các bước thực hiện ngắn gọn:
- Đọc
Nvà mảngA. - Sắp xếp mảng
A. - Khởi tạo
maxLength = 0,left = 0. - Duyệt con trỏ
righttừ 0 đếnN-1. - Bên trong vòng lặp của
right, sử dụng vòng lặpwhileđể tăngleftmiễn làA[right] - A[left] > 10. - Cập nhật
maxLength = max(maxLength, right - left + 1). - In ra
maxLength.
- Đọc
Làm thêm nhiều bài tập miễn phí tại đây
Khóa học liên quan
 Giảm giá!
Giảm giá!
Comments