Bài 7.5: Bài tập tổng hợp về Stack, Queue và Deque
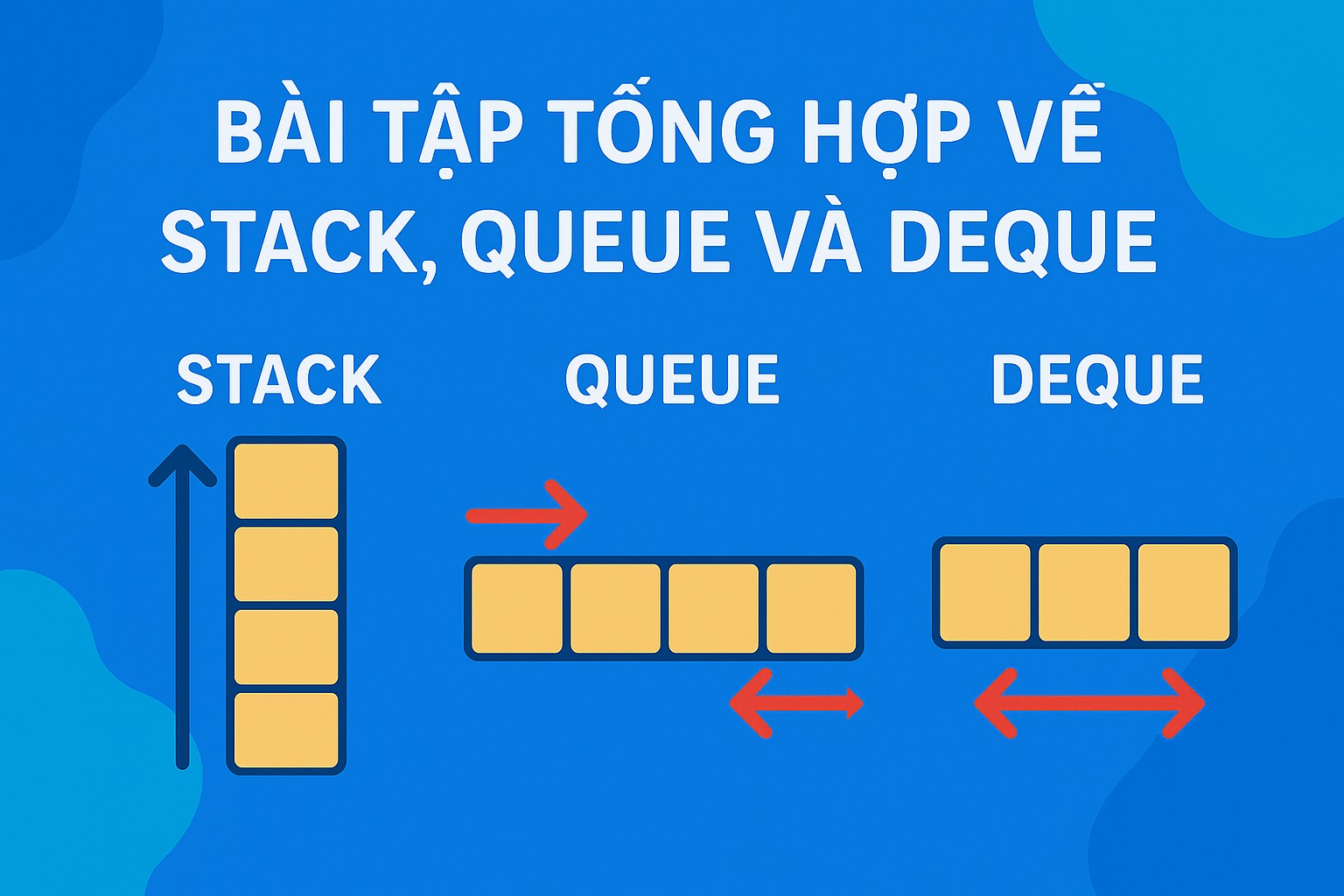
Bài 7.5: Bài tập tổng hợp về Stack, Queue và Deque
Chào mừng bạn quay trở lại với series về Cấu trúc dữ liệu và Giải thuật! Sau khi đã cùng nhau khám phá lý thuyết sâu sắc về Stack, Queue và Deque, đã đến lúc chúng ta xắn tay áo lên và đối mặt với những thách thức thực tế! Lý thuyết là nền tảng, nhưng thực hành mới là chìa khóa để biến kiến thức thành kỹ năng thực thụ.
Bài viết này sẽ tổng hợp lại những gì chúng ta đã học thông qua các bài tập vận dụng cụ thể, giúp bạn củng cố hiểu biết và tự tin hơn khi làm việc với ba cấu trúc dữ liệu mạnh mẽ này trong C++. Hãy cùng bắt đầu nào!
Bài Tập Vận Dụng
Chúng ta sẽ đi qua một vài bài tập kinh điển và thực tế để thấy cách Stack, Queue, và Deque được áp dụng hiệu quả như thế nào.
Bài Tập 1: Đảo ngược chuỗi sử dụng Stack
Đây là một bài tập kinh điển để minh họa cách hoạt động của Stack.
- Vấn đề: Làm thế nào để đảo ngược thứ tự các ký tự trong một chuỗi?
Tại sao lại dùng Stack? Stack hoạt động theo nguyên tắc LIFO (Last-In, First-Out). Khi bạn đưa các ký tự của chuỗi vào Stack theo thứ tự từ trái sang phải, ký tự cuối cùng được đưa vào sẽ là ký tự đầu tiên được lấy ra. Điều này hoàn toàn phù hợp với thao tác đảo ngược!
Code C++:
#include <iostream>
#include <stack>
#include <string>
#include <algorithm> // Cần cho std::reverse nếu muốn so sánh, nhưng ở đây dùng stack
std::string reverseString(const std::string& str) {
std::stack<char> charStack;
// Đẩy từng ký tự của chuỗi vào stack
for (char c : str) {
charStack.push(c);
}
std::string reversedStr = "";
// Lấy từng ký tự từ stack ra và nối vào chuỗi mới
// Các ký tự sẽ được lấy ra theo thứ tự ngược lại khi push
while (!charStack.empty()) {
reversedStr += charStack.top(); // Lấy phần tử trên cùng
charStack.pop(); // Xóa phần tử trên cùng
}
return reversedStr;
}
int main() {
std::string myString = "Hello Stack!";
std::string reversed = reverseString(myString);
std::cout << "Chuoi goc: " << myString << std::endl;
std::cout << "Chuoi sau khi dao nguoc: " << reversed << std::endl;
return 0;
}
- Giải thích Code:
- Chúng ta khai báo một
std::stack<char>để lưu trữ các ký tự. - Vòng lặp
for (char c : str)duyệt qua từng ký tựctrong chuỗi đầu vàostr. - Với mỗi ký tự, chúng ta dùng hàm
charStack.push(c)để đưa nó vào đỉnh của Stack. Ký tự đầu tiên của chuỗi nằm dưới đáy Stack, và ký tự cuối cùng nằm trên đỉnh. - Sau khi đẩy hết các ký tự, chúng ta khai báo một chuỗi
reversedStrrỗng để xây dựng chuỗi kết quả. - Vòng lặp
while (!charStack.empty())tiếp tục chạy cho đến khi Stack rỗng. - Trong mỗi lần lặp, chúng ta dùng
charStack.top()để truy cập (nhưng không xóa) phần tử ở đỉnh Stack (là ký tự được đẩy vào gần nhất). - Chúng ta nối ký tự này vào cuối chuỗi
reversedStr. - Sau đó, chúng ta dùng
charStack.pop()để xóa phần tử ở đỉnh Stack. - Quá trình này lặp lại, lấy ra các ký tự theo thứ tự ngược lại với khi chúng được đưa vào, hiệu quả là đảo ngược chuỗi ban đầu.
- Chúng ta khai báo một
Bài Tập 2: Kiểm tra tính hợp lệ của dấu ngoặc đơn
Một bài toán phổ biến khác thể hiện sức mạnh của Stack trong việc theo dõi trạng thái cần khớp nối.
- Vấn đề: Cho một chuỗi chỉ chứa các ký tự
'(',')','{','}','[',']', hãy kiểm tra xem chuỗi đó có hợp lệ hay không. Chuỗi hợp lệ nếu các dấu ngoặc mở được đóng lại bằng đúng loại dấu ngoặc đó theo đúng thứ tự. Tại sao lại dùng Stack? Khi gặp một dấu ngoặc mở, chúng ta biết rằng sau này sẽ cần một dấu ngoặc đóng tương ứng. Tuy nhiên, nếu có các dấu ngoặc mở khác xuất hiện trước khi dấu ngoặc hiện tại được đóng, thì dấu ngoặc đóng phải khớp với dấu ngoặc mở gần nhất chưa được đóng. Đây chính xác là nguyên tắc LIFO của Stack!
Code C++:
#include <iostream>
#include <stack>
#include <string>
#include <unordered_map>
bool areBracketsValid(const std::string& str) {
std::stack<char> bracketStack;
// Map để kiểm tra cặp ngoặc tương ứng
std::unordered_map<char, char> matchingBrackets = {
{')', '('},
{'}', '{'},
{']', '['}
};
for (char c : str) {
// Nếu là dấu ngoặc mở, đẩy vào stack
if (c == '(' || c == '{' || c == '[') {
bracketStack.push(c);
}
// Nếu là dấu ngoặc đóng
else if (c == ')' || c == '}' || c == ']') {
// Stack rỗng mà gặp ngoặc đóng -> không hợp lệ
if (bracketStack.empty()) {
return false;
}
// Kiểm tra xem đỉnh stack có khớp với ngoặc đóng hiện tại không
// Dùng matchingBrackets[c] để lấy ngoặc mở tương ứng của ngoặc đóng c
if (bracketStack.top() != matchingBrackets[c]) {
return false; // Không khớp -> không hợp lệ
}
// Nếu khớp, xóa ngoặc mở tương ứng khỏi stack
bracketStack.pop();
}
// Bỏ qua các ký tự khác nếu có
}
// Sau khi duyệt hết chuỗi, stack phải rỗng
// Nếu stack còn phần tử, nghĩa là có ngoặc mở chưa được đóng
return bracketStack.empty();
}
int main() {
std::string test1 = "()[]{}}"; // Không hợp lệ
std::string test2 = "([{}])"; // Hợp lệ
std::string test3 = "(]"; // Không hợp lệ
std::string test4 = "{[()]}"; // Hợp lệ
std::string test5 = ""; // Hợp lệ (chuỗi rỗng)
std::cout << test1 << " is valid? " << (areBracketsValid(test1) ? "True" : "False") << std::endl;
std::cout << test2 << " is valid? " << (areBracketsValid(test2) ? "True" : "False") << std::endl;
std::cout << test3 << " is valid? " << (areBracketsValid(test3) ? "True" : "False") << std::endl;
std::cout << test4 << " is valid? " << (areBracketsValid(test4) ? "True" : "False") << std::endl;
std::cout << test5 << " is valid? " << (areBracketsValid(test5) ? "True" : "False") << std::endl;
return 0;
}
- Giải thích Code:
- Chúng ta sử dụng
std::stack<char>để lưu trữ các dấu ngoặc mở chưa được đóng. std::unordered_mapgiúp chúng ta nhanh chóng tìm được dấu ngoặc mở tương ứng với một dấu ngoặc đóng.- Duyệt qua từng ký tự
ctrong chuỗi:- Nếu
clà dấu ngoặc mở ((,{,[), chúng ta đẩy nó vào Stack. Điều này ghi nhớ rằng chúng ta cần tìm dấu ngoặc đóng tương ứng sau này. - Nếu
clà dấu ngoặc đóng (),},]), chúng ta thực hiện kiểm tra:- Đầu tiên, nếu Stack rỗng, nghĩa là chúng ta gặp một dấu ngoặc đóng mà không có dấu ngoặc mở nào trước đó chưa được đóng. Chuỗi không hợp lệ.
- Nếu Stack không rỗng, chúng ta so sánh phần tử ở đỉnh Stack (
bracketStack.top()) với dấu ngoặc mở tương ứng với dấu ngoặc đóng hiện tại (tìm trongmatchingBrackets). - Nếu chúng không khớp, nghĩa là dấu ngoặc đóng hiện tại không khớp với dấu ngoặc mở gần nhất chưa được đóng. Chuỗi không hợp lệ.
- Nếu chúng khớp, điều đó có nghĩa là dấu ngoặc mở ở đỉnh Stack đã tìm thấy "đối tác" của nó. Chúng ta xóa phần tử đó khỏi Stack bằng
bracketStack.pop().
- Nếu
- Sau khi duyệt hết chuỗi, nếu Stack vẫn còn phần tử, nghĩa là có dấu ngoặc mở nào đó chưa được đóng. Chuỗi không hợp lệ.
- Nếu Stack rỗng sau khi duyệt hết chuỗi, tất cả các dấu ngoặc mở đều đã được đóng đúng cách. Chuỗi hợp lệ.
- Chúng ta sử dụng
Bài Tập 3: Mô phỏng hàng đợi xử lý đơn giản sử dụng Queue
Queue là cấu trúc dữ liệu hoàn hảo để mô phỏng các hệ thống xử lý theo trình tự thời gian.
- Vấn đề: Mô phỏng một hàng đợi khách hàng tại ngân hàng, nơi khách hàng được phục vụ theo thứ tự đến trước phục vụ trước.
Tại sao lại dùng Queue? Nguyên tắc FIFO (First-In, First-Out) của Queue mô tả chính xác cách thức hoạt động của một hàng đợi thực tế. Người đến trước sẽ được xếp vào đầu hàng và được phục vụ trước.
Code C++:
#include <iostream>
#include <queue>
#include <string>
#include <vector>
int main() {
std::queue<std::string> customerQueue;
// Khách hàng lần lượt đến và xếp hàng (push vào queue)
std::cout << "--- Khach hang den ---" << std::endl;
customerQueue.push("Alice"); // Alice den truoc
std::cout << "Alice da vao hang doi." << std::endl;
customerQueue.push("Bob"); // Bob den sau Alice
std::cout << "Bob da vao hang doi." << std::endl;
customerQueue.push("Charlie"); // Charlie den sau Bob
std::cout << "Charlie da vao hang doi." << std::endl;
std::cout << "\n--- Bat dau phuc vu ---" << std::endl;
// Phu vu khach hang theo thu tu den truoc (pop tu queue)
while (!customerQueue.empty()) {
// Xem khach hang tiep theo (phan tu dau queue)
std::string currentCustomer = customerQueue.front();
std::cout << "Dang phuc vu: " << currentCustomer << std::endl;
// Phu vu xong, khach hang roi di (xoa phan tu dau queue)
customerQueue.pop();
std::cout << currentCustomer << " da roi khoi hang doi." << std::endl;
// Kiem tra so nguoi con lai trong hang doi
std::cout << "So khach hang con lai trong hang doi: " << customerQueue.size() << std::endl;
std::cout << "--------------------" << std::endl;
}
std::cout << "\nTat ca khach hang da duoc phuc vu." << std::endl;
return 0;
}
- Giải thích Code:
- Chúng ta sử dụng
std::queue<std::string>để lưu tên khách hàng. - Khi khách hàng mới đến, chúng ta dùng
customerQueue.push(tên_khách_hàng)để thêm họ vào cuối hàng đợi. - Vòng lặp
while (!customerQueue.empty())chạy khi nào hàng đợi còn khách. - Trong mỗi lần lặp,
customerQueue.front()truy cập (nhưng không xóa) phần tử ở đầu hàng đợi (người đến trước nhất). - Chúng ta xử lý khách hàng này (trong ví dụ là in ra tên).
- Sau khi xử lý, chúng ta dùng
customerQueue.pop()để xóa phần tử ở đầu hàng đợi. - Quá trình này tiếp tục, đảm bảo rằng khách hàng được phục vụ theo đúng thứ tự họ đến, minh họa rõ ràng nguyên tắc FIFO.
- Chúng ta sử dụng
Bài Tập 4: Kiểm tra Palindrome sử dụng Deque
Deque (Double-Ended Queue) cho phép thêm/xóa phần tử ở cả hai đầu, rất hữu ích trong những bài toán cần thao tác từ cả hai phía.
- Vấn đề: Kiểm tra xem một chuỗi có phải là palindrome hay không. Palindrome là chuỗi đọc xuôi hay ngược đều giống nhau (ví dụ: "level", "madam"). Bỏ qua khoảng trắng và không phân biệt chữ hoa/thường.
Tại sao lại dùng Deque? Để kiểm tra palindrome, chúng ta cần so sánh ký tự đầu tiên với ký tự cuối cùng, ký tự thứ hai với ký tự kế cuối, và cứ thế tiếp tục cho đến khi gặp nhau ở giữa. Deque cho phép truy cập và xóa phần tử một cách hiệu quả từ cả hai đầu (
pop_front()vàpop_back()), làm cho việc thực hiện so sánh cặp này trở nên rất thuận tiện.Code C++:
#include <iostream>
#include <deque>
#include <string>
#include <cctype> // Cần cho std::isalpha, std::tolower
bool isPalindrome(const std::string& str) {
std::deque<char> charDeque;
// 1. Tiền xử lý chuỗi: chỉ lấy ký tự chữ cái và chuyển thành chữ thường
for (char c : str) {
if (std::isalpha(c)) { // Chỉ lấy ký tự chữ cái
charDeque.push_back(std::tolower(c)); // Chuyển thành chữ thường và thêm vào cuối deque
}
}
// 2. So sánh các ký tự từ hai đầu của deque
// Lặp cho đến khi deque có 0 hoặc 1 phần tử
while (charDeque.size() > 1) {
char frontChar = charDeque.front(); // Lấy ký tự đầu tiên
char backChar = charDeque.back(); // Lấy ký tự cuối cùng
// Nếu hai ký tự không giống nhau, không phải palindrome
if (frontChar != backChar) {
return false;
}
// Nếu giống nhau, loại bỏ cả hai ký tự để so sánh cặp kế tiếp
charDeque.pop_front(); // Xóa ký tự đầu tiên
charDeque.pop_back(); // Xóa ký tự cuối cùng
}
// Nếu vòng lặp kết thúc, nghĩa là tất cả các cặp đã khớp
// Chuỗi là palindrome
return true;
}
int main() {
std::string test1 = "Racecar"; // Palindrome
std::string test2 = "Hello, World!"; // Not Palindrome
std::string test3 = "Madam, I'm Adam"; // Palindrome (bỏ qua khoảng trắng, không phân biệt hoa/thường)
std::string test4 = "A man, a plan, a canal: Panama"; // Palindrome
std::string test5 = "No lemon, no melon"; // Palindrome
std::cout << "\"" << test1 << "\" is palindrome? " << (isPalindrome(test1) ? "True" : "False") << std::endl;
std::cout << "\"" << test2 << "\" is palindrome? " << (isPalindrome(test2) ? "True" : "False") << std::endl;
std::cout << "\"" << test3 << "\" is palindrome? " << (isPalindrome(test3) ? "True" : "False") << std::endl;
std::cout << "\"" << test4 << "\" is palindrome? " << (isPalindrome(test4) ? "True" : "False") << std::endl;
std::cout << "\"" << test5 << "\" is palindrome? " << (isPalindrome(test5) ? "True" : "False") << std::endl;
return 0;
}
- Giải thích Code:
- Chúng ta sử dụng
std::deque<char>để lưu trữ các ký tự sau khi tiền xử lý. - Vòng lặp đầu tiên duyệt qua chuỗi đầu vào
str. Chúng ta chỉ quan tâm đến các ký tự chữ cái (std::isalpha(c)). - Mọi ký tự chữ cái đều được chuyển thành chữ thường (
std::tolower(c)) và thêm vào cuối Deque bằngcharDeque.push_back(). Điều này đảm bảo việc so sánh không bị ảnh hưởng bởi chữ hoa/thường và bỏ qua các ký tự không phải chữ cái. - Vòng lặp
while (charDeque.size() > 1)tiếp tục chạy miễn là Deque còn ít nhất 2 phần tử (cần ít nhất một cặp để so sánh). - Trong mỗi lần lặp, chúng ta lấy ký tự ở đầu Deque (
charDeque.front()) và ký tự ở cuối Deque (charDeque.back()). - Nếu hai ký tự này khác nhau, chuỗi rõ ràng không phải là palindrome, và chúng ta trả về
false. - Nếu hai ký tự này giống nhau, chúng ta dùng
charDeque.pop_front()để xóa ký tự ở đầu vàcharDeque.pop_back()để xóa ký tự ở cuối. Điều này hiệu quả là "thu hẹp" phạm vi kiểm tra vào phần còn lại của chuỗi (hiện đang nằm giữa Deque). - Nếu vòng lặp
whilekết thúc (khi Deque còn 0 hoặc 1 phần tử), điều đó có nghĩa là tất cả các cặp ký tự đã được so sánh và đều khớp. Chuỗi là palindrome, và chúng ta trả vềtrue.
- Chúng ta sử dụng
Bài tập ví dụ:
Trò Chơi Số
Trong một dự án thủy lợi, FullHouse Dev được giao nhiệm vụ thiết kế hệ thống theo dõi mực nước. Để tối ưu hóa hệ thống, họ cần giải quyết một bài toán về dãy số liên quan đến các chỉ số đo lường.
Bài toán
FullHouse Dev được cung cấp một mảng \(A\) gồm \(N\) số nguyên. Hai hàm \(F\) và \(G\) được định nghĩa như sau:
- \(F(x)\): là số nhỏ nhất \(Z\) thỏa mãn \(Z > x\) và \(Z\) thuộc mảng \(A\)
- \(G(x)\): là số nhỏ nhất \(Z\) thỏa mãn \(Z < x\) và \(Z\) thuộc mảng \(A\)
Nhiệm vụ của nhóm là tìm \(G(F(A_i))\) với mỗi chỉ số \(i\) của mảng. Nếu không tồn tại giá trị thỏa mãn với chỉ số \(i\) nào đó, in ra -1 cho vị trí đó.
INPUT FORMAT:
- Dòng đầu tiên chứa một số nguyên \(N\) - kích thước của mảng \(A\)
- \(N\) dòng tiếp theo, mỗi dòng chứa một số nguyên \(A_i\)
OUTPUT FORMAT:
- In ra một dòng gồm \(N\) số nguyên, số thứ \(i\) biểu thị giá trị của \(G(F(A_i))\) hoặc -1 nếu không tồn tại
Ràng buộc:
- \(1 \leq N \leq 10^5\)
- \(1 \leq A_i \leq 10^9\)
Ví dụ
INPUT
8
3
7
1
7
8
4
5
2OUTPUT
1 4 4 4 -1 2 -1 -1Giải thích
Với mỗi phần tử trong mảng:
- 3: F(3) = 7, G(7) = 1
- 7: F(7) = 8, G(8) = 4
- 1: F(1) = 7, G(7) = 4
- 7: F(7) = 8, G(8) = 4
- 8: F(8) không tồn tại, nên kết quả là -1
- 4: F(4) = 5, G(5) = 2
- 5: F(5) không tồn tại, nên kết quả là -1
- 2: F(2) không tồn tại, nên kết quả là -1 Tuyệt vời, một bài toán kinh điển áp dụng cấu trúc dữ liệu ngăn xếp (stack)! Dựa vào ví dụ và ràng buộc, có vẻ như định nghĩa F và G không hoàn toàn theo nghĩa "số nhỏ nhất trong toàn bộ mảng A", mà có liên quan đến vị trí của các phần tử trong mảng gốc.
Dựa vào ví dụ giải thích, ta có thể suy luận định nghĩa ẩn ý của bài toán như sau:
F(A_i): Là giá trị của phần tử đầu tiênA_jxuất hiện bên phảiA_i(tức làj > i) thỏa mãnA_j > A_i. Nếu không có phần tử nào như vậy,F(A_i)không tồn tại.- Giả sử
F(A_i)làA_j(tức là tìm đượcj > inhỏ nhất sao choA_j > A_i). G(F(A_i))hayG(A_j): Là giá trị của phần tử đầu tiênA_kxuất hiện bên phảiA_j(tức làk > j) thỏa mãnA_k < A_j. Nếu không có phần tử nào như vậy,G(A_j)không tồn tại.
Nhiệm vụ là tìm G(F(A_i)) cho mỗi i.
Đây là bài toán tìm "Phần tử lớn hơn kế tiếp bên phải" (Next Greater Element - NGE) kết hợp với "Phần tử nhỏ hơn kế tiếp bên phải" (Next Smaller Element - NSE). Cụ thể:
- Bước 1: Tìm NGE cho mỗi
A_i. Kết quả cần lưu là chỉ số của NGE. - Bước 2: Đối với chỉ số
jcủa NGE tìm được ở Bước 1, tìm NSE choA_j(tức là phần tử nhỏ hơn kế tiếp bên phảiA_j). Kết quả cần lưu là giá trị của NSE.
Cả hai bài toán NGE và NSE đều có thể giải quyết hiệu quả trong O(N) thời gian sử dụng ngăn xếp.
Gợi ý giải thuật:
Tiền xử lý 1: Tìm chỉ số NGE cho mỗi phần tử
A_i:- Duyệt mảng
Atừ phải sang trái (từ indexN-1về 0). - Sử dụng một stack để lưu trữ các chỉ số của các phần tử mà ta đã duyệt qua (theo thứ tự giảm dần của chỉ số). Stack này sẽ giúp tìm NGE.
- Khi xử lý phần tử
A[i]:- Po p các chỉ số
idxkhỏi stack trong khi stack chưa rỗng VÀA[idx] <= A[i]. Các phần tử tại các chỉ số này sẽ không thể là NGE củaA[i]hoặc các phần tử bên tráiA[i]. - Sau khi po p, nếu stack rỗng, nghĩa là không có phần tử nào bên phải
A[i]lớn hơn nó. Lưu chỉ số NGE củaA[i]là -1 (hoặc một giá trị sentinel). - Nếu stack không rỗng, phần tử ở đỉnh stack (
stack.top()) chính là chỉ số của NGE đầu tiên bên phảiA[i]. Lưu chỉ số này. - Push chỉ số hiện tại
ivào stack.
- Po p các chỉ số
- Lưu trữ kết quả vào một mảng/vector
nge_indexcó kích thước N, trong đónge_index[i]là chỉ số của NGE củaA[i], hoặc -1 nếu không tồn tại.
- Duyệt mảng
Tiền xử lý 2: Tìm giá trị NSE cho mỗi phần tử
A_i:- Duyệt mảng
Atừ phải sang trái (từ indexN-1về 0). - Sử dụng một stack khác để lưu trữ giá trị của các phần tử đã duyệt qua. Stack này giúp tìm NSE.
- Khi xử lý phần tử
A[i]:- Po p các giá trị
valkhỏi stack trong khi stack chưa rỗng VÀval >= A[i]. - Sau khi po p, nếu stack rỗng, nghĩa là không có phần tử nào bên phải
A[i]nhỏ hơn nó. Lưu giá trị NSE củaA[i]là -1. - Nếu stack không rỗng, phần tử ở đỉnh stack (
stack.top()) chính là giá trị của NSE đầu tiên bên phảiA[i]. Lưu giá trị này. - Push giá trị hiện tại
A[i]vào stack.
- Po p các giá trị
- Lưu trữ kết quả vào một mảng/vector
nse_valuecó kích thước N, trong đónse_value[i]là giá trị của NSE củaA[i], hoặc -1 nếu không tồn tại.
- Duyệt mảng
Kết hợp kết quả:
- Duyệt mảng
Atừ trái sang phải (từ index 0 đếnN-1). - Đối với mỗi
i:- Lấy chỉ số NGE của
A[i]từnge_index[i]. Gọi chỉ số này làj. - Nếu
jlà -1 (không có NGE), kết quả choA[i]là -1. - Nếu
jkhông phải -1, giá trịF(A_i)làA[j]. Ta cần tìmG(A[j]), tức là NSE củaA[j]. Giá trị này đã được tính và lưu trongnse_value[j]từ bước tiền xử lý 2. Kết quả choA[i]chính lànse_value[j].
- Lấy chỉ số NGE của
- In các kết quả.
- Duyệt mảng
Tóm tắt các bước cần làm trong code C++:
- Include các thư viện cần thiết (
iostream,vector,stack). - Đọc N.
- Đọc N phần tử vào
std::vector<int> A. - Tạo
std::vector<int> nge_index(N)vàstd::stack<int> st_index. - Implement thuật toán stack O(N) để điền vào
nge_index(lưu chỉ số). - Tạo
std::vector<int> nse_value(N)vàstd::stack<int> st_value. - Implement thuật toán stack O(N) để điền vào
nse_value(lưu giá trị). - Tạo
std::vector<int> result(N). - Lặp từ
i = 0đếnN-1:- Lấy
j = nge_index[i]. - Nếu
j == -1,result[i] = -1. - Ngược lại,
result[i] = nse_value[j].
- Lấy
- In các phần tử của vector
resultcách nhau bởi dấu cách.
Giải thuật này có độ phức tạp thời gian O(N) và độ phức tạp không gian O(N), phù hợp với ràng buộc của bài toán.
Làm thêm nhiều bài tập miễn phí tại đây
Khóa học liên quan
 Giảm giá!
Giảm giá!
Comments