Bài 13.5: So sánh các thuật toán sắp xếp cơ bản
Bài 13.5: So sánh các thuật toán sắp xếp cơ bản
Chào mừng trở lại với series blog về Cấu trúc dữ liệu và Giải thuật! Sau khi đã khám phá các thuật toán sắp xếp riêng lẻ, hôm nay chúng ta sẽ đặt chúng lên bàn cân để so sánh và làm rõ ưu nhược điểm của từng phương pháp. Sắp xếp là một trong những vấn đề cốt lõi và phổ biến nhất trong Khoa học Máy tính. Việc hiểu rõ cách các thuật toán cơ bản hoạt động và khác biệt ra sao không chỉ giúp chúng ta chọn lựa phù hợp (dù hiếm khi dùng các thuật toán cơ bản cho dữ liệu lớn trong thực tế) mà còn là nền tảng vững chắc để tiếp cận các thuật toán phức tạp và hiệu quả hơn sau này.
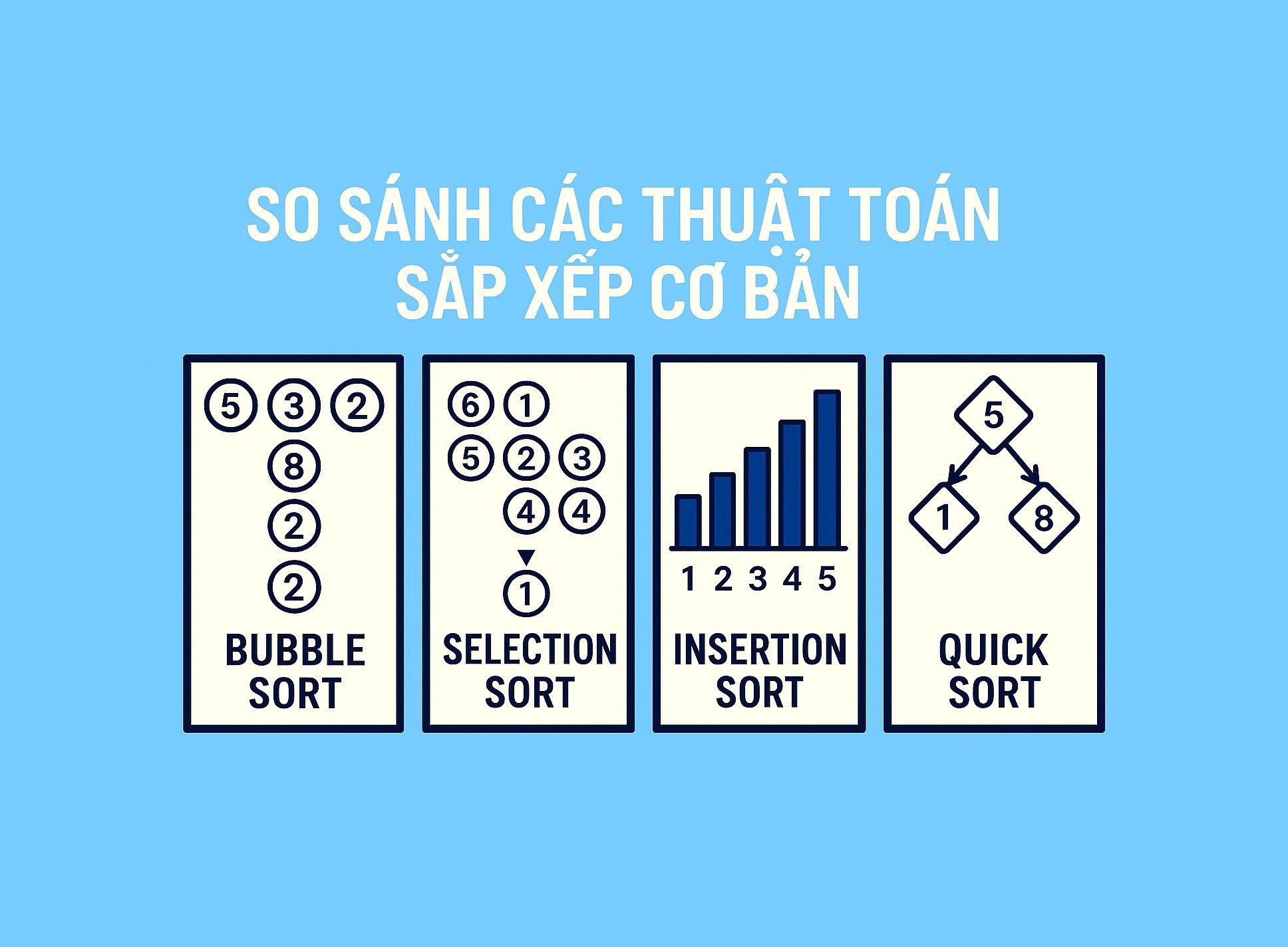
Trong bài viết này, chúng ta sẽ tập trung vào ba "ông lớn" trong nhóm các thuật toán sắp xếp cơ bản và đơn giản nhất để hiểu:
- Bubble Sort (Sắp xếp nổi bọt)
- Selection Sort (Sắp xếp chọn)
- Insertion Sort (Sắp xếp chèn)
Chúng ta sẽ cùng xem cách mỗi thuật toán tiếp cận bài toán sắp xếp một cách khác biệt như thế nào, phân tích độ phức tạp về thời gian và không gian của chúng, và xem xét một số đặc điểm quan trọng khác.
1. Bubble Sort: Sự "Nổi Bọt" Của Các Phần Tử
Ý tưởng chính của Bubble Sort khá trực quan: lặp đi lặp lại qua danh sách, so sánh các phần tử kề nhau và hoán đổi chúng nếu chúng sai thứ tự. Quá trình này được lặp lại cho đến khi toàn bộ danh sách được sắp xếp. Giống như bong bóng khí nhẹ hơn nổi lên mặt nước, các phần tử lớn hơn sẽ "nổi" dần về cuối danh sách qua mỗi lần lặp.
Cơ chế hoạt động:
- Bắt đầu từ đầu danh sách, so sánh phần tử đầu tiên với phần tử thứ hai. Nếu phần tử đầu lớn hơn, hoán đổi chúng.
- Tiếp tục so sánh phần tử thứ hai với thứ ba, hoán đổi nếu cần. Cứ thế cho đến khi so sánh cặp phần tử cuối cùng.
- Sau lần lặp đầu tiên, phần tử lớn nhất chắc chắn sẽ nằm ở vị trí cuối cùng đúng của nó.
- Lặp lại quá trình tương tự với phần còn lại của danh sách (trừ phần tử cuối cùng đã được sắp xếp) cho đến khi không có hoán đổi nào xảy ra trong một lần lặp đầy đủ, tức là danh sách đã được sắp xếp.
Phân tích độ phức tạp:
- Độ phức tạp thời gian:
- Trường hợp xấu nhất (Worst Case): Mảng được sắp xếp ngược. Cần O(n^2) phép so sánh và O(n^2) phép hoán đổi. O(n^2).
- Trường hợp trung bình (Average Case): O(n^2).
- Trường hợp tốt nhất (Best Case): Mảng đã được sắp xếp. Nếu cài đặt có cờ kiểm tra hoán đổi, chỉ cần O(n) phép so sánh. O(n).
- Độ phức tạp không gian: Chỉ sử dụng một vài biến tạm để hoán đổi, nên độ phức tạp không gian là O(1) (In-place sorting).
- Ổn định (Stable): Có. Bubble Sort giữ nguyên thứ tự tương đối của các phần tử có giá trị bằng nhau.
Ví dụ minh họa bằng C++:
Đây là mã C++ cho Bubble Sort. Chú ý đến việc sử dụng cờ swapped để tối ưu hóa trong trường hợp mảng đã được sắp xếp sớm.
#include <iostream>
#include <vector>
#include <algorithm> // For std::swap
// Hàm in mảng
void printArray(const std::vector<int>& arr) {
for (int x : arr) {
std::cout << x << " ";
}
std::cout << std::endl;
}
// Thuật toán Bubble Sort
void bubbleSort(std::vector<int>& arr) {
int n = arr.size();
bool swapped; // Cờ để kiểm tra xem có bất kỳ hoán đổi nào xảy ra trong lần lặp không
// Lặp qua tất cả các phần tử trong mảng
// Vòng lặp ngoài chạy từ 0 đến n-2. Sau mỗi lần lặp này, phần tử lớn nhất chưa sắp xếp
// sẽ nổi lên vị trí đúng ở cuối mảng chưa sắp xếp.
for (int i = 0; i < n - 1; ++i) {
swapped = false; // Giả định chưa có hoán đổi nào xảy ra
// Vòng lặp trong thực hiện so sánh và hoán đổi các phần tử kề nhau.
// Giới hạn j < n - 1 - i là vì i phần tử cuối cùng đã được sắp xếp sau i lần lặp ngoài.
for (int j = 0; j < n - 1 - i; ++j) {
// Nếu phần tử hiện tại lớn hơn phần tử kế tiếp, hoán đổi chúng
if (arr[j] > arr[j + 1]) {
std::swap(arr[j], arr[j + 1]);
swapped = true; // Đánh dấu là đã có hoán đổi
}
}
// Nếu không có hoán đổi nào xảy ra trong vòng lặp trong, tức là mảng đã được sắp xếp
if (!swapped) {
break;
}
// (Tùy chọn) In mảng sau mỗi lần lặp ngoài để thấy quá trình
// std::cout << "Mang sau buoc " << i + 1 << ": ";
// printArray(arr);
}
}
// Hàm main để chạy thử
int main() {
std::vector<int> data = {64, 34, 25, 12, 22, 11, 90};
std::cout << "Mang ban dau: ";
printArray(data);
bubbleSort(data);
std::cout << "Mang sau khi sap xep (Bubble Sort): ";
printArray(data);
return 0;
}
Giải thích mã C++:
- Chúng ta sử dụng một vector
std::vector<int>để mô phỏng mảng. - Hàm
bubbleSortnhận vector làm tham chiếu (&) để có thể sửa đổi trực tiếp. nlà kích thước của mảng.- Vòng lặp ngoài
for (int i = 0; i < n - 1; ++i)kiểm soát số lần "pass" qua mảng. Ở pass thứi, phần tử lớn thứi+1sẽ được đẩy về vị trí cuối cùng của phần chưa sắp xếp. - Vòng lặp trong
for (int j = 0; j < n - 1 - i; ++j)đi qua các cặp phần tử kề nhau trong phần chưa được sắp xếp và thực hiện so sánh/hoán đổi.n - 1 - ilà giới hạn vìiphần tử cuối cùng đã ở đúng vị trí. - Câu lệnh
if (arr[j] > arr[j + 1])là điều kiện để hoán đổi.std::swaplà hàm tiện ích để hoán đổi giá trị hai biến. - Biến
swappedlà một kỹ thuật tối ưu hóa. Nếu trong một lần lặp đầy đủ của vòng lặp trong mà không có bất kỳ hoán đổi nào xảy ra (swappedvẫn làfalse), điều đó có nghĩa là toàn bộ mảng đã được sắp xếp, và chúng ta có thể thoát sớm khỏi vòng lặp ngoài bằngbreak.
Nhận xét:
Bubble Sort là đơn giản nhất để hiểu và cài đặt, nhưng cũng là kém hiệu quả nhất đối với hầu hết các trường hợp do số lượng lớn các phép so sánh và hoán đổi (trừ trường hợp mảng gần như đã được sắp xếp và có sử dụng cờ swapped).
2. Selection Sort: Tìm "Nhà" Cho Từng Phần Tử
Khác với Bubble Sort chỉ hoán đổi các phần tử kề nhau, Selection Sort có ý tưởng là chia mảng thành hai phần: một phần đã được sắp xếp (bắt đầu từ bên trái, ban đầu rỗng) và một phần chưa được sắp xếp (phần còn lại). Thuật toán lặp đi lặp lại việc tìm phần tử nhỏ nhất từ phần chưa sắp xếp và đưa nó về cuối phần đã sắp xếp (tức là đặt nó vào vị trí đầu tiên của phần chưa sắp xếp).
Cơ chế hoạt động:
- Bắt đầu với toàn bộ mảng là phần chưa được sắp xếp.
- Tìm phần tử nhỏ nhất trong toàn bộ mảng chưa sắp xếp.
- Hoán đổi phần tử nhỏ nhất đó với phần tử đầu tiên của phần chưa sắp xếp. Sau thao tác này, phần tử đầu tiên đó sẽ nằm ở vị trí đúng của nó và trở thành một phần của mảng đã sắp xếp.
- Lặp lại quá trình tương tự với phần còn lại của mảng chưa sắp xếp (tức là bắt đầu từ vị trí thứ hai, thứ ba, v.v.) cho đến khi toàn bộ mảng được sắp xếp.
Phân tích độ phức tạp:
- Độ phức tạp thời gian:
- Trường hợp xấu nhất, trung bình, tốt nhất: Luôn cần O(n) bước để tìm phần tử nhỏ nhất trong phần chưa sắp xếp (kích thước n, n-1, n-2,...). Tổng số phép so sánh luôn là n + (n-1) + ... + 1 = O(n^2). Số phép hoán đổi là O(n). Thời gian chủ yếu do phép so sánh. O(n^2) cho mọi trường hợp.
- Độ phức tạp không gian: Tương tự Bubble Sort, chỉ cần O(1) không gian phụ. O(1) (In-place sorting).
- Ổn định (Stable): Không. Selection Sort có thể làm thay đổi thứ tự tương đối của các phần tử bằng nhau khi thực hiện hoán đổi.
Ví dụ minh họa bằng C++:
Mã C++ cho Selection Sort. Lưu ý cách nó tìm chỉ số của phần tử nhỏ nhất trước khi thực hiện hoán đổi.
#include <iostream>
#include <vector>
#include <algorithm> // For std::swap
// Hàm in mảng
void printArray(const std::vector<int>& arr) {
for (int x : arr) {
std::cout << x << " ";
}
std::cout << std::endl;
}
// Thuật toán Selection Sort
void selectionSort(std::vector<int>& arr) {
int n = arr.size();
// Lặp qua từng vị trí cần đặt phần tử nhỏ nhất vào (từ 0 đến n-2)
// Vòng lặp ngoài chạy từ 0 đến n-2. Biến i đánh dấu ranh giới giữa
// mảng đã sắp xếp (arr[0..i-1]) và mảng chưa sắp xếp (arr[i..n-1]).
for (int i = 0; i < n - 1; ++i) {
// Tìm phần tử nhỏ nhất trong mảng chưa sắp xếp (từ i đến n-1)
int min_idx = i; // Giả sử phần tử đầu tiên của phần chưa sắp xếp là nhỏ nhất
// Vòng lặp trong đi từ i+1 đến n-1 để tìm chỉ số của phần tử nhỏ nhất thực sự
for (int j = i + 1; j < n; ++j) {
if (arr[j] < arr[min_idx]) {
min_idx = j; // Cập nhật chỉ số của phần tử nhỏ nhất
}
}
// Nếu phần tử nhỏ nhất không phải là phần tử hiện tại (tại chỉ số i), hoán đổi chúng.
// Điều này đưa phần tử nhỏ nhất về đúng vị trí của nó trong mảng đã sắp xếp.
if (min_idx != i) {
std::swap(arr[i], arr[min_idx]);
}
// (Tùy chọn) In mảng sau mỗi lần tìm và đặt phần tử nhỏ nhất
// std::cout << "Mang sau buoc " << i + 1 << ": ";
// printArray(arr);
}
}
// Hàm main để chạy thử
int main() {
std::vector<int> data = {64, 34, 25, 12, 22, 11, 90};
std::cout << "Mang ban dau: ";
printArray(data);
selectionSort(data);
std::cout << "Mang sau khi sap xep (Selection Sort): ";
printArray(data);
return 0;
}
Giải thích mã C++:
- Hàm
selectionSortcũng làm việc trên vectorarr. - Vòng lặp ngoài
for (int i = 0; i < n - 1; ++i)xác định vị trí hiện tạiimà chúng ta muốn đặt phần tử nhỏ nhất của phần còn lại vào đó. - Biến
min_idxlưu trữ chỉ số của phần tử nhỏ nhất được tìm thấy trong lần lặp hiện tại của vòng lặp ngoài. Ban đầu, nó được gán lài. - Vòng lặp trong
for (int j = i + 1; j < n; ++j)đi qua tất cả các phần tử sau vị tríiđể tìm ra chỉ số thực sự của phần tử nhỏ nhất trong đoạn[i, n-1]. - Sau khi vòng lặp trong kết thúc,
min_idxchứa chỉ số của phần tử nhỏ nhất. - Câu lệnh
if (min_idx != i)kiểm tra xem phần tử nhỏ nhất đã nằm ở vị tríichưa. Nếu chưa, chúng ta hoán đổiarr[i]vàarr[min_idx].
Nhận xét:
Selection Sort có độ phức tạp thời gian nhất quán là O(n^2) cho mọi trường hợp. Mặc dù cũng là O(n^2), nó có một ưu điểm tiềm năng so với Bubble Sort: nó thực hiện ít phép hoán đổi hơn (tối đa n-1 phép hoán đổi), điều này có thể có lợi nếu chi phí hoán đổi rất cao so với chi phí so sánh. Tuy nhiên, nó không ổn định và không thích ứng (adaptive) với dữ liệu gần như đã được sắp xếp.
3. Insertion Sort: Sắp Xếp Như Chơi Bài
Insertion Sort hoạt động theo cách tương tự như cách bạn sắp xếp một bộ bài trong tay: chia mảng thành hai phần, một phần đã được sắp xếp (ban đầu chỉ chứa phần tử đầu tiên) và một phần chưa được sắp xếp. Thuật toán lấy từng phần tử từ phần chưa sắp xếp và chèn nó vào đúng vị trí của nó trong phần đã sắp xếp.
Cơ chế hoạt động:
- Coi phần tử đầu tiên của mảng là phần đã sắp xếp (một mảng con chỉ có 1 phần tử luôn được sắp xếp).
- Lấy phần tử thứ hai từ phần chưa sắp xếp. So sánh nó với các phần tử trong phần đã sắp xếp (từ phải sang trái).
- Trong khi so sánh, nếu phần tử đang xét nhỏ hơn phần tử trong phần đã sắp xếp, dịch chuyển phần tử trong phần đã sắp xếp sang phải để tạo chỗ trống.
- Khi tìm thấy vị trí thích hợp (hoặc đến đầu mảng), chèn phần tử đang xét vào chỗ trống đó.
- Lặp lại quá trình với các phần tử tiếp theo trong phần chưa sắp xếp cho đến khi không còn phần tử nào.
Phân tích độ phức tạp:
- Độ phức tạp thời gian:
- Trường hợp xấu nhất (Worst Case): Mảng được sắp xếp ngược. Mỗi phần tử cần được chèn vào đầu của mảng con đã sắp xếp, yêu cầu nhiều phép dịch chuyển. O(n^2) phép so sánh và O(n^2) phép dịch chuyển/hoán đổi. O(n^2).
- Trường hợp trung bình (Average Case): O(n^2).
- Trường hợp tốt nhất (Best Case): Mảng đã được sắp xếp. Chỉ cần một lần so sánh cho mỗi phần tử (trừ phần tử đầu tiên). O(n). Insertion Sort rất thích ứng (adaptive).
- Độ phức tạp không gian: Chỉ cần O(1) không gian phụ để lưu trữ phần tử đang chèn. O(1) (In-place sorting).
- Ổn định (Stable): Có. Khi gặp các phần tử bằng nhau, Insertion Sort sẽ chèn phần tử mới sau các phần tử bằng nó đã có trong phần đã sắp xếp, giữ nguyên thứ tự tương đối.
Ví dụ minh họa bằng C++:
Mã C++ cho Insertion Sort. Chú ý đến cách nó "nhấc" một phần tử ra và dịch chuyển các phần tử khác để tạo chỗ trống.
#include <iostream>
#include <vector>
// Hàm in mảng
void printArray(const std::vector<int>& arr) {
for (int x : arr) {
std::cout << x << " ";
}
std::cout << std::endl;
}
// Thuật toán Insertion Sort
void insertionSort(std::vector<int>& arr) {
int n = arr.size();
// Bắt đầu từ phần tử thứ hai (chỉ số 1) vì phần tử đầu tiên (chỉ số 0)
// được coi là mảng đã sắp xếp ban đầu (kích thước 1).
// Vòng lặp ngoài chạy từ 1 đến n-1. Biến i đại diện cho phần tử hiện tại
// đang được xét để chèn vào mảng đã sắp xếp (arr[0..i-1]).
for (int i = 1; i < n; ++i) {
// Lưu trữ giá trị của phần tử hiện tại vào biến 'key'
int key = arr[i];
// Biến j là chỉ số của phần tử cuối cùng trong mảng đã sắp xếp
int j = i - 1;
// Di chuyển các phần tử của mảng đã sắp xếp (arr[0..i-1]) mà lớn hơn 'key'
// sang phải một vị trí để tạo chỗ trống cho 'key'.
// Vòng lặp trong chạy lùi từ i-1 về 0.
// Điều kiện j >= 0 đảm bảo không truy cập ra ngoài mảng.
// Điều kiện arr[j] > key kiểm tra xem phần tử trong mảng đã sắp xếp có lớn hơn 'key' không.
while (j >= 0 && arr[j] > key) {
arr[j + 1] = arr[j]; // Dịch chuyển phần tử sang phải
j = j - 1; // Giảm chỉ số j để xét phần tử kế tiếp về bên trái
}
// Chèn 'key' vào vị trí trống vừa tạo ra (j + 1)
arr[j + 1] = key;
// (Tùy chọn) In mảng sau mỗi lần chèn một phần tử
// std::cout << "Mang sau buoc " << i << ": ";
// printArray(arr);
}
}
// Hàm main để chạy thử
int main() {
std::vector<int> data = {64, 34, 25, 12, 22, 11, 90};
std::cout << "Mang ban dau: ";
printArray(data);
insertionSort(data);
std::cout << "Mang sau khi sap xep (Insertion Sort): ";
printArray(data);
return 0;
}
Giải thích mã C++:
- Hàm
insertionSortxử lý vectorarr. - Vòng lặp ngoài
for (int i = 1; i < n; ++i)bắt đầu từ chỉ số 1. Mỗi lần lặp,arr[i]là phần tử mà chúng ta sẽ chèn vào phần đã sắp xếparr[0...i-1]. key = arr[i]lưu giá trị của phần tử cần chèn.j = i - 1là chỉ số của phần tử cuối cùng trong mảng đã sắp xếp hiện tại.- Vòng lặp
while (j >= 0 && arr[j] > key)thực hiện việc dịch chuyển. Nó lùi dần từi-1về 0 trong phần đã sắp xếp. Nếu một phần tửarr[j]lớn hơnkey, nó sẽ được dịch sang phải một vị trí (arr[j + 1] = arr[j]). - Vòng lặp
whiledừng lại khi gặp một phần tửarr[j]nhỏ hơn hoặc bằngkey(hoặc khi đến đầu mảngj < 0). - Vị trí
j + 1chính là nơi cần chènkey. Câu lệnharr[j + 1] = key;thực hiện việc chèn này.
Nhận xét:
Insertion Sort là hiệu quả nhất trong ba thuật toán này khi xử lý các mảng có kích thước nhỏ hoặc các mảng gần như đã được sắp xếp do độ phức tạp tốt nhất là O(n) và số lượng phép dịch chuyển ít hơn so với hoán đổi trong trường hợp tốt nhất. Nó cũng là thuật toán ổn định.
4. Tổng kết và So Sánh
Bây giờ, hãy tổng hợp lại các đặc điểm chính của ba thuật toán này vào một bảng để dễ dàng so sánh:
| Đặc điểm | Bubble Sort | Selection Sort | Insertion Sort |
|---|---|---|---|
| Ý tưởng chính | Hoán đổi kề nhau | Tìm min/max đưa về đầu | Chèn từng phần tử |
| Độ phức tạp TG (Worst) | O(n^2) | O(n^2) | O(n^2) |
| Độ phức tạp TG (Average) | O(n^2) | O(n^2) | O(n^2) |
| Độ phức tạp TG (Best) | O(n) (với cờ) | O(n^2) | O(n) |
| Độ phức tạp KG | O(1) | O(1) | O(1) |
| Ổn định (Stable) | Có | Không | Có |
| Thích ứng (Adaptive) | Có (với cờ) | Không | Có |
| Ưu điểm | Đơn giản nhất | Ít hoán đổi nhất | Hiệu quả với mảng nhỏ/gần sắp xếp |
| Nhược điểm | Nhiều hoán đổi, chậm | Luôn O(n^2) | Chậm với mảng lớn, ngược |
- Khi nào sử dụng?
- Bubble Sort & Selection Sort: Chủ yếu dùng để học và hiểu các khái niệm sắp xếp cơ bản. Rất hiếm khi dùng trong các ứng dụng thực tế với dữ liệu đáng kể do hiệu suất O(n^2). Selection Sort có thể cân nhắc khi chi phí hoán đổi là cực kỳ đắt đỏ so với so sánh (dù vẫn chậm về thời gian).
- Insertion Sort: Có thể dùng cho các mảng có kích thước rất nhỏ hoặc khi biết chắc dữ liệu đầu vào gần như đã được sắp xếp. Trong các thư viện sắp xếp phức tạp hơn (như
std::sorttrong C++), Insertion Sort thường được sử dụng như một bước cuối cùng để sắp xếp các mảng con nhỏ nhằm tối ưu hiệu suất.
Bài tập ví dụ:
Sắp xếp nổi bọt
Trong một buổi học, giáo sư đã đưa ra một bài toán thú vị cho FullHouse Dev. Bài toán này liên quan đến thuật toán sắp xếp nổi bọt và yêu cầu họ phân tích kỹ lưỡng quá trình sắp xếp. Với sự tò mò và nhiệt huyết, FullHouse Dev bắt đầu tìm hiểu bài toán.
Bài toán
Cho một mảng \(A\) gồm \(n\) phần tử. Hãy xác định giá trị trả về của hàm \(f(n)\) trong hình ảnh được cung cấp.
Link đến hình ảnh: https://ibb.co/vzFR5kr

INPUT FORMAT:
- Dòng đầu tiên chứa số nguyên \(n\) (\(1 \leq n \leq 10^5\)) - số lượng phần tử của mảng \(A\).
- Dòng thứ hai chứa \(n\) số nguyên dương (\(1 \leq A_i \leq 10^9\)) - các phần tử của mảng \(A\).
Lưu ý: Đảm bảo rằng tất cả các phần tử của mảng \(A\) là khác nhau.
OUTPUT FORMAT:
In ra một số nguyên biểu thị câu trả lời cho câu hỏi.
VÍ DỤ
INPUT
5
1 3 2 5 4OUTPUT
2FullHouse Dev đã rất hào hứng với bài toán này và bắt đầu phân tích thuật toán sắp xếp nổi bọt để tìm ra câu trả lời chính xác. Họ biết rằng việc hiểu rõ cách hoạt động của thuật toán sẽ giúp họ giải quyết bài toán một cách hiệu quả.
Dựa vào mô tả bài toán và ví dụ, có vẻ như hàm f(n) mà bài toán yêu cầu tính chính là tổng số lần hoán đổi (swaps) được thực hiện trong quá trình sắp xếp mảng A bằng thuật toán Sắp xếp nổi bọt (phiên bản có tối ưu: dừng lại khi không còn hoán đổi nào trong một lượt).
Tổng số lần hoán đổi trong Sắp xếp nổi bọt (phiên bản cơ bản hoặc có tối ưu) luôn bằng với tổng số cặp nghịch thế trong mảng ban đầu. Một cặp nghịch thế là một cặp chỉ số (i, j) sao cho i < j nhưng A[i] > A[j].
Vì n có thể lên đến 10^5, thuật toán đếm cặp nghịch thế trực tiếp bằng cách duyệt tất cả các cặp (i, j) (có độ phức tạp O(n^2)) sẽ quá chậm. Cần một thuật toán hiệu quả hơn.
Hướng giải quyết hiệu quả (O(n log n)):
Có hai phương pháp chính để đếm cặp nghịch thế hiệu quả:
Sử dụng Merge Sort (Sắp xếp trộn):
- Ý tưởng là sửa đổi quá trình trộn (merge) của thuật toán Merge Sort.
- Khi trộn hai mảng con đã được sắp xếp, nếu một phần tử từ mảng con bên trái lớn hơn một phần tử từ mảng con bên phải, thì phần tử bên trái đó sẽ tạo thành nghịch thế với phần tử bên phải và tất cả các phần tử còn lại trong mảng con bên phải (vì mảng con bên phải đã được sắp xếp).
- Đếm số lượng các cặp như vậy trong quá trình trộn và cộng dồn vào tổng số nghịch thế.
- Quá trình đếm được thực hiện đệ quy.
Sử dụng Cây Fenwick (Fenwick Tree / Binary Indexed Tree - BIT) hoặc Cây phân đoạn (Segment Tree):
- Ý tưởng là duyệt qua mảng và sử dụng cấu trúc dữ liệu (BIT/Segment Tree) để đếm số lượng các phần tử đã gặp trước đó (hoặc sau đó) có giá trị lớn hơn (hoặc nhỏ hơn) phần tử hiện tại.
- Vì giá trị các phần tử
A_icó thể lớn (10^9), cần thực hiện chuẩn hóa dữ liệu (coordinate compression) trước. Tức là ánh xạ mỗi giá trị duy nhất trong mảng về thứ hạng của nó trong dãy các giá trị đã sắp xếp (ví dụ: giá trị nhỏ nhất được ánh xạ về 1, giá trị lớn thứ hai ánh xạ về 2, ...). Vì các phần tử là khác nhau, sẽ cónthứ hạng từ 1 đếnn. - Sau khi chuẩn hóa, ta có thể dùng BIT/Segment Tree trên các thứ hạng này (từ 1 đến
n). - Duyệt mảng gốc từ phải sang trái. Với mỗi phần tử
A[i], tìm thứ hạngrcủa nó. Số nghịch thế màA[i]tạo với các phần tử bên phải nó chính là số lượng các phần tử đã được xử lý (ở bên phảii) có thứ hạng nhỏ hơnr. Ta có thể truy vấn BIT để lấy tổng các giá trị tại các chỉ số từ 1 đếnr-1. Sau khi xử lýA[i], cập nhật BIT tại chỉ sốrđể đánh dấu rằng một phần tử với thứ hạngrđã được gặp.
Tóm tắt các bước cho phương pháp BIT:
- Đọc
nvà mảngA. - Chuẩn hóa dữ liệu: Tạo danh sách các cặp
(giá trị, chỉ số gốc), sắp xếp theo giá trị, sau đó tạo mảngrankslưu thứ hạng (từ 1 đếnn) cho từng phần tử ở vị trí gốc của nó trong mảngA. - Khởi tạo BIT có kích thước
n + 1(cho thứ hạng từ 1 đếnn), tất cả các giá trị ban đầu bằng 0. - Khởi tạo biến
total_inversions = 0. - Duyệt mảng
Atừ phải sang trái (từ chỉ sốn-1về 0). - Với mỗi phần tử
A[i]:- Lấy thứ hạng
r = ranks[i]. - Truy vấn BIT để lấy tổng các giá trị từ 1 đến
r-1. Kết quả này chính là số phần tử đã gặp bên phảiA[i]có thứ hạng nhỏ hơnA[i](tức là giá trị nhỏ hơnA[i]). Cộng giá trị này vàototal_inversions. - Cập nhật BIT tại chỉ số
rbằng cách tăng giá trị lên 1 (đánh dấu đã gặp một phần tử có thứ hạngr).
- Lấy thứ hạng
- Kết quả cuối cùng là giá trị của
total_inversions.
Làm thêm nhiều bài tập miễn phí tại đây
Khóa học liên quan
 Giảm giá!
Giảm giá!
Comments