Bài 14.2. Chiến lược chọn pivot và tối ưu
Bài 14.2. Chiến lược chọn pivot và tối ưu
Chào mừng các bạn quay trở lại với series bài viết về Cấu trúc dữ liệu và Giải thuật! Trong các bài trước, chúng ta đã tìm hiểu về các giải thuật sắp xếp và chọn phần tử, đặc biệt là những giải thuật dựa trên nguyên lý phân hoạch (partitioning) như QuickSort và Quickselect. Hôm nay, chúng ta sẽ đào sâu vào một yếu tố cực kỳ quan trọng quyết định hiệu suất của những giải thuật này: chiến lược chọn pivot và các kỹ thuật tối ưu đi kèm.
Bạn đã bao giờ thắc mắc tại sao cùng là QuickSort hoặc Quickselect mà khi chạy với dữ liệu khác nhau lại cho tốc độ khác nhau đáng kể không? Câu trả lời nằm ở việc chọn pivot.
Tầm Quan Trọng Của Pivot: Linh Hồn (hoặc Ác Mộng) Của Phân Hoạch
Hãy nhớ lại nguyên lý cơ bản của phân hoạch: chọn một phần tử làm pivot, sau đó di chuyển các phần tử nhỏ hơn pivot về một bên và các phần tử lớn hơn pivot về bên còn lại.
- Mục tiêu lý tưởng: Sau khi phân hoạch, pivot nằm ở vị trí cuối cùng của nó trong mảng đã sắp xếp, và mảng được chia thành hai mảng con có kích thước gần bằng nhau. Điều này dẫn đến thời gian chạy hiệu quả O(N log N) cho QuickSort và O(N) trung bình cho Quickselect.
- Thảm họa: Nếu pivot luôn là phần tử nhỏ nhất hoặc lớn nhất trong mảng con hiện tại, mỗi bước phân hoạch sẽ tạo ra một mảng con cực kỳ mất cân bằng (một bên kích thước N-1, một bên kích thước 0). Điều này đẩy thời gian chạy lên mức ác mộng O(N^2) trong trường hợp xấu nhất.
Chính vì thế, việc lựa chọn pivot không chỉ là một chi tiết kỹ thuật, mà là một chiến lược then chốt.
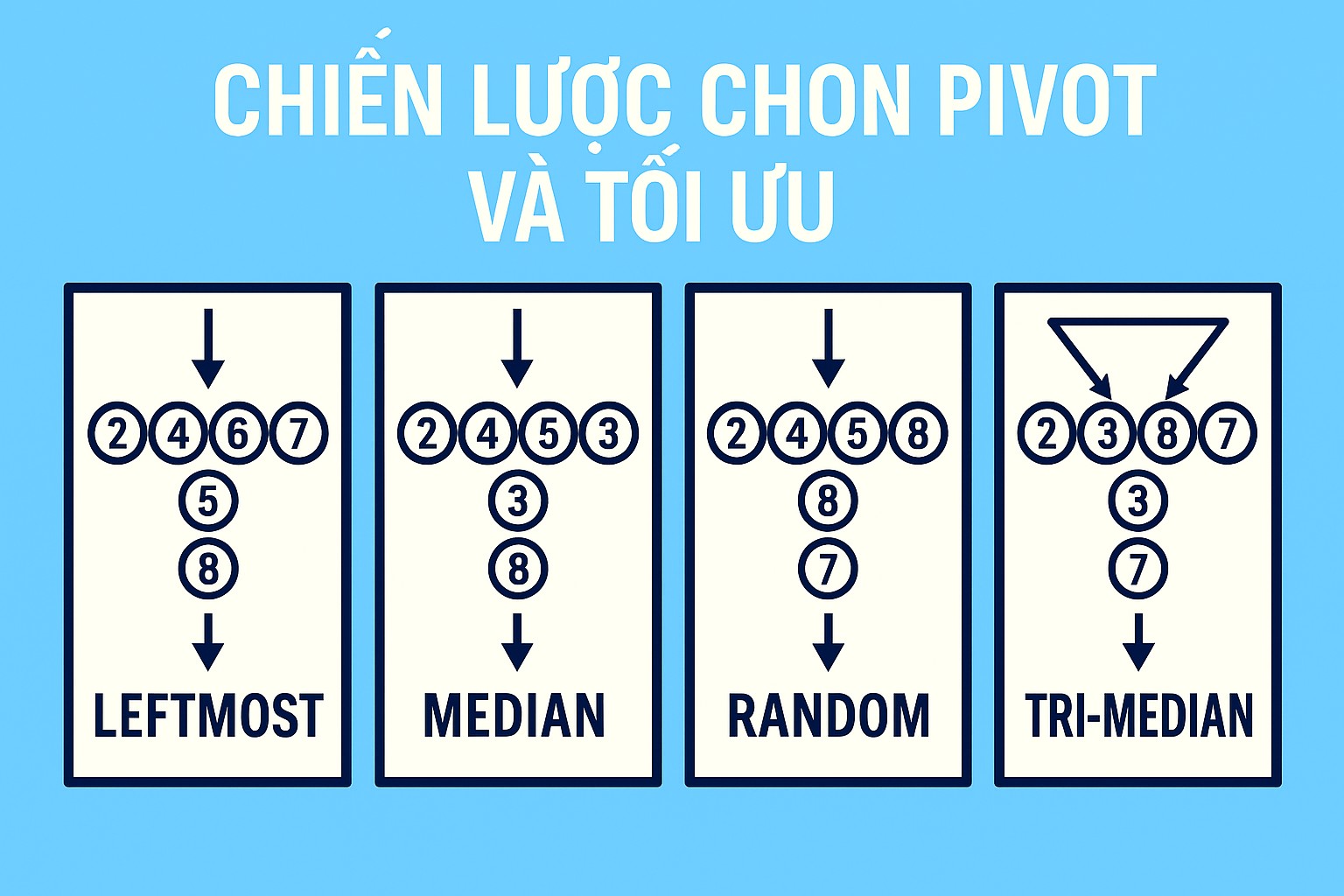
Các Chiến Lược Chọn Pivot Phổ Biến (và Nhược Điểm)
Hãy điểm qua một số cách chọn pivot đơn giản mà bạn có thể nghĩ đến đầu tiên:
Chọn phần tử đầu tiên (hoặc cuối cùng):
- Ưu điểm: Cực kỳ đơn giản để cài đặt.
- Nhược điểm: Thảm họa nếu mảng đầu vào đã được sắp xếp hoặc gần sắp xếp (tăng dần hoặc giảm dần). Pivot sẽ luôn là phần tử nhỏ nhất hoặc lớn nhất, dẫn đến trường hợp xấu nhất O(N^2).
// Example: Lấy phần tử đầu tiên làm pivot int select_first_pivot(vector<int>& arr, int low, int high) { return low; // Trả về chỉ số của phần tử đầu tiên }- Giải thích: Hàm này chỉ đơn giản trả về chỉ số
low, là chỉ số của phần tử đầu tiên trong đoạn mảng[low...high]. Đây là cách chọn pivot đơn giản nhất nhưng tiềm ẩn rủi ro hiệu suất cao nhất với dữ liệu có cấu trúc.
Chọn phần tử ở giữa:
- Ưu điểm: Tốt hơn một chút so với chọn đầu/cuối nếu dữ liệu có phân phối ngẫu nhiên.
- Nhược điểm: Vẫn có thể gặp trường hợp xấu nhất O(N^2) với các dạng dữ liệu có cấu trúc đặc biệt (ví dụ: mảng "lượn sóng").
// Example: Lấy phần tử ở giữa làm pivot int select_middle_pivot(vector<int>& arr, int low, int high) { return low + (high - low) / 2; // Trả về chỉ số phần tử ở giữa }- Giải thích: Hàm này tính chỉ số ở giữa đoạn
[low...high]và trả về chỉ số đó. Đây là một cải tiến nhỏ nhưng không giải quyết được vấn đề trường hợp xấu nhất về mặt lý thuyết.
Những chiến lược đơn giản này dễ cài đặt nhưng không đảm bảo hiệu suất ổn định. Chúng ta cần những phương pháp tốt hơn.
Nâng Cấp Chiến Lược: Hướng Tới Sự Cân Bằng
1. Chọn Pivot Ngẫu Nhiên (Random Pivot)
Đây là một chiến lược phổ biến và hiệu quả trong thực tế. Thay vì chọn pivot theo một quy tắc cố định (đầu, cuối, giữa), chúng ta chọn một phần tử ngẫu nhiên trong mảng con hiện tại làm pivot.
- Ưu điểm: Với dữ liệu bất kỳ, việc chọn pivot ngẫu nhiên khiến cho trường hợp xấu nhất O(N^2) trở nên cực kỳ khó xảy ra. Trung bình, pivot ngẫu nhiên sẽ tạo ra các phân hoạch tương đối cân bằng, đảm bảo thời gian chạy trung bình O(N log N) cho QuickSort và O(N) cho Quickselect.
- Nhược điểm: Không loại bỏ trường hợp xấu nhất về mặt lý thuyết. Vẫn có khả năng (dù rất nhỏ) chọn phải các phần tử tồi tệ liên tục, dẫn đến O(N^2). Tuy nhiên, xác suất này là siêu nhỏ.
Để cài đặt, chúng ta chỉ cần sinh một số ngẫu nhiên trong phạm vi chỉ số của mảng con và đổi chỗ phần tử tại chỉ số đó với phần tử đầu tiên (hoặc cuối cùng), sau đó tiến hành phân hoạch như bình thường với phần tử đã đổi chỗ.
#include <vector>
#include <algorithm> // For swap
#include <cstdlib> // For rand, srand
#include <ctime> // For time
// Hàm hỗ trợ đổi chỗ
void swap(vector<int>& arr, int i, int j) {
swap(arr[i], arr[j]);
}
// Hàm phân hoạch (partition) sử dụng phần tử cuối làm pivot sau khi chọn
// Đây là một biến thể của phân hoạch Lomuto hoặc Hoare
int partition(vector<int>& arr, int low, int high) {
int pivot_value = arr[high]; // Giả sử pivot đã được đặt ở cuối
int i = (low - 1); // Chỉ số của phần tử nhỏ hơn pivot
for (int j = low; j <= high - 1; j++) {
if (arr[j] <= pivot_value) {
i++;
swap(arr, i, j);
}
}
swap(arr, i + 1, high);
return (i + 1); // Trả về chỉ số cuối cùng của pivot
}
// Hàm chọn pivot ngẫu nhiên và chuẩn bị cho phân hoạch
int select_random_pivot_and_partition(vector<int>& arr, int low, int high) {
// Khởi tạo seed cho bộ sinh số ngẫu nhiên (chỉ nên gọi 1 lần trong toàn bộ chương trình)
// srand(static_cast<unsigned int>(time(0)));
// Chọn một chỉ số ngẫu nhiên trong đoạn [low, high]
int random_index = low + rand() % (high - low + 1);
// Đổi chỗ phần tử ngẫu nhiên với phần tử cuối để sử dụng hàm partition chuẩn
swap(arr, random_index, high);
// Tiến hành phân hoạch với pivot (bây giờ là phần tử cuối)
return partition(arr, low, high);
}
- Giải thích:
- Chúng ta sử dụng
rand()để sinh số ngẫu nhiên.srand(static_cast<unsigned int>(time(0)))được dùng để khởi tạo "hạt giống" cho bộ sinh số ngẫu nhiên, đảm bảo dãy số ngẫu nhiên thay đổi mỗi lần chạy chương trình. Quan trọng: Chỉ nên gọisrandmột lần duy nhất ở đầu chương trình. random_indexlà chỉ số ngẫu nhiên được chọn trong phạm vi[low, high].- Phần tử tại
random_indexđược đổi chỗ với phần tử tạihigh. - Sau đó, hàm
partitionđược gọi trên mảng con[low...high]với giả định pivot là phần tử tạihigh. Hàmpartitionnày (là biến thể của phân hoạch Lomuto) sẽ đặt pivot vào đúng vị trí cuối cùng của nó và trả về chỉ số đó.
- Chúng ta sử dụng
Chiến lược ngẫu nhiên là lựa chọn tốt cho hầu hết các ứng dụng thực tế vì sự đơn giản và hiệu quả trung bình cao.
2. Chọn Pivot là Trung vị của Ba Phần tử (Median-of-Three)
Ý tưởng là thay vì chỉ chọn một phần tử duy nhất, chúng ta chọn ba phần tử (ví dụ: phần tử đầu, phần tử giữa, và phần tử cuối của mảng con hiện tại), tìm trung vị (median) của ba giá trị này, và sử dụng trung vị đó làm pivot.
- Ưu điểm: Chiến lược này giảm đáng kể khả năng gặp phải trường hợp xấu nhất khi dữ liệu có cấu trúc đơn giản (như đã sắp xếp hoặc gần sắp xếp). Nếu dữ liệu đã sắp xếp, trung vị của ba phần tử đầu, giữa, cuối sẽ là phần tử ở giữa, giúp phân hoạch cân bằng hơn nhiều so với chọn đầu hoặc cuối. Đây là một kỹ thuật tối ưu phổ biến trong các cài đặt QuickSort/Quickselect thực tế.
- Nhược điểm: Vẫn có thể gặp trường hợp xấu nhất O(N^2) với các dạng dữ liệu được thiết kế đặc biệt để "đánh lừa" chiến lược trung vị của ba (dù khó xảy ra hơn). Cần thêm một chút thao tác để tìm và đặt trung vị làm pivot.
Cách triển khai: Chọn 3 chỉ số (thường là low, high, và mid = low + (high - low) / 2), sắp xếp 3 phần tử tại các chỉ số này, và đổi chỗ phần tử trung vị với phần tử cuối cùng (hoặc bất kỳ vị trí nào phù hợp để sử dụng trong hàm partition).
#include <vector>
#include <algorithm> // For swap, sort
#include <cmath> // For floor
// Hàm hỗ trợ tìm chỉ số của trung vị trong 3 chỉ số
int median_of_three_index(vector<int>& arr, int a, int b, int c) {
// Sắp xếp 3 giá trị và tìm chỉ số của giá trị ở giữa
if ((arr[a] < arr[b] && arr[b] < arr[c]) || (arr[c] < arr[b] && arr[b] < arr[a]))
return b;
else if ((arr[b] < arr[a] && arr[a] < arr[c]) || (arr[c] < arr[a] && arr[a] < arr[b]))
return a;
else
return c;
}
// Hàm chọn pivot trung vị của ba và chuẩn bị cho phân hoạch
int select_median_of_three_and_partition(vector<int>& arr, int low, int high) {
int mid = low + (high - low) / 2;
// Tìm chỉ số của trung vị giữa arr[low], arr[mid], arr[high]
int pivot_index = median_of_three_index(arr, low, mid, high);
// Đổi chỗ phần tử trung vị với phần tử cuối (hoặc trước cuối)
// Thường đổi chỗ với high-1 nếu partition chỉ xét đến high-1
// Ở đây ta đổi chỗ với high để dùng lại hàm partition ở trên
swap(arr, pivot_index, high);
// Tiến hành phân hoạch với pivot (bây giờ là phần tử cuối)
return partition(arr, low, high); // Sử dụng lại hàm partition từ ví dụ random pivot
}
- Giải thích:
- Hàm
median_of_three_indexnhận 3 chỉ số và trả về chỉ số của phần tử có giá trị trung vị trong số 3 phần tử đó. select_median_of_three_and_partitiontính chỉ số giữamid.- Gọi
median_of_three_indexđể tìm chỉ số của trung vị giữaarr[low],arr[mid], vàarr[high]. - Đổi chỗ phần tử tại chỉ số trung vị với phần tử cuối (
arr[high]). - Sử dụng lại hàm
partitionđã viết (giả sử pivot ở cuối) để phân hoạch.
- Hàm
Chiến lược trung vị của ba là một sự cân bằng tốt giữa hiệu suất và độ phức tạp cài đặt, được sử dụng rộng rãi.
3. Trung Vị của các Trung Vị (Median of Medians)
Đây là một chiến lược nâng cao và phức tạp, được phát triển để đảm bảo trường hợp xấu nhất của giải thuật chọn phần tử (Selection Algorithm - giống Quickselect) chạy trong thời gian tuyến tính O(N). Chiến lược này đảm bảo rằng pivot được chọn sẽ "đủ tốt", tức là nó sẽ đứng giữa 30% và 70% các phần tử trong mảng con hiện tại.
Ý tưởng:
- Chia mảng đầu vào thành các nhóm nhỏ, mỗi nhóm có kích thước cố định (thường là 5 phần tử).
- Tìm trung vị của mỗi nhóm nhỏ bằng một phương pháp đơn giản (ví dụ: sắp xếp nhóm nhỏ và lấy phần tử ở giữa).
- Thu thập tất cả các trung vị này vào một mảng mới.
- Gọi đệ quy giải thuật này để tìm trung vị của mảng các trung vị vừa thu thập được. Trung vị này chính là pivot được chọn.
- Tiến hành phân hoạch mảng gốc sử dụng pivot vừa tìm được.
- Dựa vào vị trí của pivot sau phân hoạch, quyết định sẽ tiếp tục tìm kiếm ở mảng con bên trái hay bên phải (như Quickselect).
Ưu điểm: Đảm bảo thời gian chạy tuyến tính O(N) trong trường hợp xấu nhất cho bài toán chọn phần tử (Quickselect).
- Nhược điểm: Phức tạp để cài đặt. Hằng số ẩn trong ký hiệu O lớn có thể lớn hơn so với các chiến lược đơn giản hơn trên dữ liệu trung bình. Chủ yếu mang ý nghĩa lý thuyết hoặc cần thiết trong các ứng dụng yêu cầu đảm bảo hiệu suất trong mọi trường hợp.
Cài đặt hoàn chỉnh Median of Medians khá dài và phức tạp, đòi hỏi cài đặt cả hàm tìm trung vị của nhóm nhỏ, hàm chọn đệ quy cho mảng trung vị, và tích hợp vào quá trình phân hoạch và chọn. Dưới đây chỉ mô tả ý tưởng và một hàm giả định để minh họa cách sử dụng:
// Hàm giả định cho Median of Medians (cài đặt thực tế phức tạp hơn nhiều)
// Mục tiêu: Trả về chỉ số của một pivot được đảm bảo "đủ tốt"
int select_median_of_medians_pivot(vector<int>& arr, int low, int high); // Khai báo
// Ví dụ cấu trúc hàm selection với Median of Medians
int median_of_medians_select(vector<int>& arr, int low, int high, int k) {
if (k < 0 || k >= arr.size()) {
// Xử lý lỗi k không hợp lệ
return -1; // Hoặc ném ngoại lệ
}
if (low == high) { // Trường hợp cơ sở: mảng con chỉ có 1 phần tử
return arr[low];
}
// Bước 1: Chọn pivot bằng Median of Medians
int pivot_index = select_median_of_medians_pivot(arr, low, high);
// Đổi chỗ pivot được chọn về vị trí cuối để sử dụng hàm partition
swap(arr, pivot_index, high);
// Bước 2: Phân hoạch mảng sử dụng pivot
int pivot_final_index = partition(arr, low, high); // Sử dụng hàm partition ở trên
// Bước 3: So sánh k với vị trí của pivot
if (k == pivot_final_index) {
return arr[k]; // Đã tìm thấy phần tử thứ k
} else if (k < pivot_final_index) {
// Phần tử thứ k nằm ở mảng con bên trái của pivot
return median_of_medians_select(arr, low, pivot_final_index - 1, k);
} else {
// Phần tử thứ k nằm ở mảng con bên phải của pivot
// Vị trí tương đối của k trong mảng con mới là k, không cần điều chỉnh
return median_of_medians_select(arr, pivot_final_index + 1, high, k);
}
}
/*
Giải thích về select_median_of_medians_pivot (ý tưởng):
Hàm này sẽ thực hiện các bước:
1. Chia arr[low...high] thành các nhóm 5 phần tử.
2. Đối với mỗi nhóm 5, sắp xếp nó (dùng Insertion Sort cho nhóm nhỏ rất hiệu quả) và lấy trung vị.
3. Thu thập các trung vị này vào một mảng tạm.
4. Gọi đệ quy chính nó (select_median_of_medians_pivot) trên mảng tạm các trung vị để tìm trung vị của các trung vị.
5. Trả về chỉ số của phần tử đó trong mảng gốc arr[low...high].
Điều này đảm bảo rằng pivot_value (và do đó pivot_final_index) sẽ phân hoạch mảng sao cho cả hai mảng con đều có kích thước ít nhất là khoảng 30% của mảng gốc (high - low + 1), đảm bảo độ sâu đệ quy O(log N) đối với số lượng phần tử cần xử lý, dẫn đến thời gian tổng thể O(N) cho bài toán Select.
*/
- Giải thích: Đoạn mã trên chủ yếu minh họa cách một hàm Quickselect (
median_of_medians_select) sẽ sử dụng một hàm chọn pivotselect_median_of_medians_pivot(được giả định tồn tại và thực hiện logic phức tạp của Median of Medians). Hàmselect_median_of_medians_pivotsẽ là nơi chứa logic chia nhóm, tìm trung vị nhóm, gọi đệ quy tìm trung vị của các trung vị. Sau khi pivot được chọn, nó được đổi chỗ và dùng hàmpartitionthông thường. Logic đệ quy tìm kiếm phần tử thứktương tự như Quickselect cơ bản, nhưng hiệu suất trường hợp xấu nhất được cải thiện nhờ chất lượng của pivot.
Median of Medians mang lại đảm bảo lý thuyết mạnh mẽ nhưng ít được sử dụng trong các cài đặt thư viện chuẩn cho QuickSort/Quickselect vì độ phức tạp và hằng số lớn hơn.
Các Kỹ Thuật Tối Ưu Khác
Bên cạnh việc chọn pivot, có những kỹ thuật khác có thể cải thiện hiệu suất của QuickSort/Quickselect, đặc biệt là giảm chi phí overhead và xử lý hiệu quả các trường hợp nhỏ:
Tối ưu đệ quy đuôi (Tail Recursion Optimization): Trong QuickSort hoặc Quickselect, chúng ta gọi đệ quy trên hai (QuickSort) hoặc một (Quickselect) mảng con. Nếu luôn gọi đệ quy trên mảng con nhỏ hơn trước và xử lý mảng con lớn hơn bằng một vòng lặp, chúng ta có thể giới hạn độ sâu của stack đệ quy xuống O(log N) thay vì O(N) trong trường hợp xấu nhất. Điều này giúp tránh lỗi tràn stack trên dữ liệu lớn hoặc có cấu trúc xấu.
```c++ // Ví dụ cấu trúc Quickselect với tối ưu đệ quy đuôi int quick_select_optimized(vector<int>& arr, int low, int high, int k) {
// k là vị trí (chỉ số) cần tìm, 0-based if (k < low || k > high) { // Xử lý lỗi k không hợp lệ trong phạm vi [low, high] // Thực tế k thường là vị trí trong mảng gốc, nên kiểm tra k < 0 || k >= arr.size() ở ngoài // Nếu k là vị trí trong mảng gốc, chúng ta tìm phần tử thứ k // relative to the current subarray [low...high] // Chú ý: Với bài toán tìm phần tử thứ k trong toàn bộ mảng, // k là vị trí tuyệt đối 0-based. // Trong hàm đệ quy, chúng ta tìm phần tử có chỉ số k trong mảng gốc. }
// Vòng lặp để xử lý đệ quy đuôi
while (low <= high) {
// Chọn pivot (ví dụ: dùng Median-of-Three)
int pivot_index = select_median_of_three_and_partition(arr, low, high); // Sử dụng hàm đã viết
// So sánh k với vị trí của pivot
if (k == pivot_index) {
return arr[k]; // Đã tìm thấy phần tử thứ k
} else if (k < pivot_index) {
// Phần tử thứ k nằm ở mảng con bên trái
high = pivot_index - 1; // Cập nhật giới hạn trên và lặp lại
} else {
// Phần tử thứ k nằm ở mảng con bên phải
low = pivot_index + 1; // Cập nhật giới hạn dưới và lặp lại
}
// Không cần gọi đệ quy cho phần lớn hơn, chỉ cần điều chỉnh low/high
// Vòng lặp while(low <= high) sẽ tiếp tục xử lý
}
// Trường hợp không tìm thấy (thường không xảy ra nếu k hợp lệ)
return -1; // Hoặc ném ngoại lệ
}
// Lưu ý: Với QuickSort, bạn sẽ gọi đệ quy trên mảng con nhỏ hơn và lặp cho mảng con lớn hơn.
// if (left_part_size < right_part_size) {
// quicksort(arr, low, pivot_index - 1); // Đệ quy phần nhỏ hơn
// low = pivot_index + 1; // Lặp cho phần lớn hơn
// } else {
// quicksort(arr, pivot_index + 1, high); // Đệ quy phần nhỏ hơn
// high = pivot_index - 1; // Lặp cho phần lớn hơn
// }
```
* *Giải thích:* Thay vì gọi đệ quy cho *cả hai* nhánh (hoặc một nhánh trong Quickselect), chúng ta chỉ gọi đệ quy cho nhánh *nhỏ hơn*. Nhánh *lớn hơn* được xử lý bằng cách điều chỉnh các biến `low` và `high` và quay trở lại đầu vòng lặp `while`. Điều này biến một trong hai cuộc gọi đệ quy thành một thao tác lặp đơn giản, giữ cho độ sâu stack tối thiểu.Sử dụng Insertion Sort cho các mảng con nhỏ: Khi mảng con trở nên rất nhỏ (dưới một ngưỡng kích thước nhất định, thường là 10-20 phần tử), chi phí overhead của đệ quy và phân hoạch trong QuickSort/Quickselect có thể lớn hơn chi phí của một giải thuật đơn giản như Insertion Sort.
- Kỹ thuật: Khi kích thước của mảng con
(high - low + 1)nhỏ hơn ngưỡng, dừng việc gọi đệ quy/lặp và sử dụng Insertion Sort để sắp xếp mảng con đó. Một cách khác là dừng đệ quy/lặp khi mảng con nhỏ và chỉ chạy Insertion Sort một lần trên toàn bộ mảng sau khi QuickSort/Quickselect đã hoàn thành.
// Hàm Insertion Sort cho một đoạn của mảng void insertion_sort(vector<int>& arr, int low, int high) { for (int i = low + 1; i <= high; i++) { int key = arr[i]; int j = i - 1; while (j >= low && arr[j] > key) { arr[j + 1] = arr[j]; j--; } arr[j + 1] = key; } } // Ví dụ cấu trúc QuickSort với ngưỡng Insertion Sort void quick_sort_with_threshold(vector<int>& arr, int low, int high) { // Ngưỡng kích thước mảng con để chuyển sang Insertion Sort const int INSERTION_SORT_THRESHOLD = 10; // Nếu mảng con đủ nhỏ, sử dụng Insertion Sort và dừng đệ quy if (high - low + 1 <= INSERTION_SORT_THRESHOLD) { insertion_sort(arr, low, high); return; } // Nếu không, tiếp tục QuickSort // ... (logic chọn pivot và phân hoạch tương tự như QuickSort chuẩn) ... // int pivot_final_index = partition(arr, low, high); // Sử dụng hàm partition // quick_sort_with_threshold(arr, low, pivot_final_index - 1); // Đệ quy trái // quick_sort_with_threshold(arr, pivot_final_index + 1, high); // Đệ quy phải } // Với Quickselect, bạn cũng có thể dừng lặp khi mảng con nhỏ và dùng Insertion Sort để tìm phần tử thứ k // trong mảng con đó, hoặc chỉ đơn giản là dừng và để Insertion Sort cuối cùng sắp xếp // Tuy nhiên, chiến lược phổ biến hơn cho Quickselect là tối ưu đệ quy đuôi. // Việc dùng Insertion Sort cho Quickselect thường chỉ có ý nghĩa nếu bạn cần sắp xếp hoàn toàn mảng con nhỏ đó.- Giải thích: Trước khi thực hiện phân hoạch hoặc gọi đệ quy, chúng ta kiểm tra kích thước của mảng con
(high - low + 1). Nếu nó nhỏ hơnINSERTION_SORT_THRESHOLD, chúng ta gọi hàminsertion_sorttrên đoạn[low...high]và thoát khỏi hàm đệ quy/lặp cho nhánh đó. Ngưỡng này có thể được tinh chỉnh để đạt hiệu suất tốt nhất tùy thuộc vào hệ thống.
- Kỹ thuật: Khi kích thước của mảng con
Bài tập ví dụ:
Công suất tối đa
Trong một buổi điều tra, FullHouse Dev được viện kiểm sát giao cho một bài toán phức tạp. Họ cần phải tính toán công suất tối đa có thể đạt được từ một mảng số nguyên sau khi thực hiện một phép hoán đổi. Với tinh thần kiên trì và tỉ mỉ, FullHouse Dev bắt đầu phân tích và giải quyết vấn đề này.
Bài toán
Cho một mảng \(A\) gồm \(N\) số nguyên khác nhau.
Công suất của mảng được định nghĩa như sau:
- Với mỗi \(i\), \(j\) là chỉ số lớn nhất nhỏ hơn \(i\) sao cho \(A[j] < A[i]\).
- Công suất của mảng là tổng của tất cả các \(j\).
Ví dụ: Nếu mảng là \({1,2,5}\), thì công suất của mảng là \(0 + 1 + 2 = 3\).
Phép toán cho phép: Bạn được phép chọn hai chỉ số bất kỳ \(x\) và \(y\) và hoán đổi \(A[x]\) và \(A[y]\). Hãy tìm công suất tối đa có thể đạt được.
Lưu ý: Bạn chỉ được phép thực hiện phép toán trên tối đa một lần.
INPUT FORMAT:
- Dòng đầu tiên chứa một số nguyên \(T\), là số lượng bộ test.
- Dòng đầu tiên của mỗi bộ test chứa một số nguyên \(N\).
- Dòng thứ hai của mỗi bộ test chứa \(N\) số nguyên cách nhau bởi dấu cách, biểu diễn mảng \(A\).
OUTPUT FORMAT:
- Với mỗi bộ test, in ra công suất tối đa có thể đạt được trên một dòng mới.
Ràng buộc:
- \(1 \leq T \leq 10\)
- \(2 \leq N \leq 10^5\)
- \(1 \leq A[i] \leq 10^9\)
Ví dụ
INPUT
2
2
9 10
4
2 3 4 1OUTPUT
1
3Giải thích
- Ở bộ test đầu tiên, không cần thực hiện hoán đổi nào, công suất tối đa đạt được là 1.
- Ở bộ test thứ hai, ta có thể hoán đổi \(A[3]\) và \(A[4]\) để mảng trở thành 2 3 1 4, và công suất sẽ là 3. ## Hướng dẫn giải bài toán "Công suất tối đa"
Đây là một bài toán yêu cầu tối ưu hóa một giá trị được định nghĩa dựa trên cấu trúc của mảng sau khi thực hiện tối đa một phép hoán đổi.
1. Hiểu rõ định nghĩa Công suất:
Công suất của mảng được tính bằng tổng các chỉ số j thỏa mãn:
jlà chỉ số (1-based indexing dựa trên ví dụ)j < i(vớiilà chỉ số hiện tại, 1-based indexing)A[j] < A[i]jlà chỉ số lớn nhất thỏa mãn hai điều kiện trên cho mỗii.- Nếu không tồn tại
jnhư vậy cho mộti, chỉ số đó không đóng góp vào tổng (hoặc đóng góp 0).
Dựa vào ví dụ {1, 2, 5}:
- i=1 (giá trị 1): Không có j < 1. Đóng góp 0.
- i=2 (giá trị 2): j < 2 là j=1. A[1]=1 < A[2]=2. j=1 là chỉ số lớn nhất nhỏ hơn 2 thỏa mãn A[j] < A[2]. Đóng góp 1.
- i=3 (giá trị 5): j < 3 là j=1, 2. A[1]=1 < A[3]=5. A[2]=2 < A[3]=5. Chỉ số lớn nhất trong {1, 2} là 2. Đóng góp 2.
- Tổng công suất: 0 + 1 + 2 = 3.
Như vậy, công suất là tổng của
prev_smaller_index[i](chỉ số lớn nhất j) + 1, vớiichạy từ 2 đến N (1-based indexing). Hoặc tương đương, tổng củaprev_smaller_index[i](0-based indexing) + 1, vớiichạy từ 1 đến N-1 (0-based indexing).
2. Tính công suất ban đầu:
Việc tìm chỉ số j lớn nhất nhỏ hơn i sao cho A[j] < A[i] (còn gọi là "Previous Smaller Element Index") là một bài toán kinh điển có thể giải bằng Stack trong O(N).
- Thuật toán tính
prev_smaller_index(0-based):- Khởi tạo mảng
psi[0...N-1], gán giá trị -1. - Khởi tạo một stack rỗng để lưu các cặp
(giá trị, chỉ_số). - Duyệt qua mảng
Atừ trái sang phải (chỉ sốitừ 0 đến N-1). - Với mỗi
A[i]:- Trong khi stack chưa rỗng và giá trị ở đỉnh stack (
stack.top().first) lớn hơn hoặc bằngA[i], loại bỏ phần tử ở đỉnh stack. - Nếu stack không rỗng sau khi loại bỏ, chỉ số của phần tử ở đỉnh stack (
stack.top().second) chính làprev_smaller_index[i](lớn nhấtj < ivớiA[j] < A[i]). Gánpsi[i] = stack.top().second. - Đẩy cặp
(A[i], i)vào stack.
- Trong khi stack chưa rỗng và giá trị ở đỉnh stack (
- Khởi tạo mảng
- Tính công suất ban đầu:
- Sau khi tính được mảng
psi, công suất ban đầu là tổng củapsi[i] + 1cho tất cả cácitừ 1 đến N-1, trong đó chỉ cộng vào nếupsi[i] != -1. Hoặc đơn giản hơn, tổng củamax(0, psi[i] + 1)choitừ 1 đến N-1.
- Sau khi tính được mảng
Thời gian thực hiện: O(N) cho việc tính psi và O(N) cho việc tính tổng. Tổng cộng O(N).
3. Xét phép hoán đổi:
Bạn được phép hoán đổi A[x] và A[y] tối đa một lần. Mục tiêu là tìm công suất tối đa.
Có O(N^2) cặp chỉ số (x, y) có thể hoán đổi. Đối với mỗi cặp:
- Thực hiện hoán đổi
A[x]vàA[y]. - Tính lại công suất của mảng mới.
- Cập nhật công suất tối đa nếu cần.
- Hoàn tác hoán đổi.
Việc tính lại công suất cho mỗi hoán đổi mất O(N). Tổng thời gian cho cách tiếp cận O(N^2) hoán đổi là O(N^3). Với N=10^5, cách này quá chậm.
4. Tối ưu hóa việc tính công suất sau hoán đổi:
Vấn đề nằm ở chỗ làm thế nào để tính công suất của mảng sau hoán đổi một cách nhanh chóng, hoặc tính được thay đổi công suất một cách nhanh chóng.
Khi hoán đổi A[x] và A[y] (giả sử x < y), chỉ các chỉ số i > x mới có khả năng bị thay đổi prev_smaller_index[i].
- Đối với
i <= x: tiền tốA[0...i-1]không thay đổi, nênpsi[i]không thay đổi. - Đối với
x < i <= y: tiền tốA[0...i-1]thay đổi ở vị tríx(giá trị cũ củaA[x]được thay bằng giá trị cũ củaA[y]). - Đối với
i > y: tiền tốA[0...i-1]thay đổi ở hai vị tríxvày.
Việc tính psi'[i] cho mảng sau hoán đổi A' đòi hỏi duyệt lại tiền tố A'[0...i-1]. Điều này vẫn có vẻ tốn O(i) hoặc O(log i) nếu dùng cấu trúc dữ liệu phức tạp. Tổng lại vẫn có thể dẫn đến O(N) cho mỗi lần tính công suất sau hoán đổi.
Để đạt được O(N log N) hoặc O(N) trên tổng số hoán đổi (hoặc chỉ xét O(N) hoán đổi "quan trọng"), cần một cách hiệu quả hơn để tính thay đổi công suất.
Sự thay đổi công suất cho một chỉ số i > x là (psi'[i] + 1) - (psi[i] + 1) = psi'[i] - psi[i].
psi[i] là chỉ số j < i lớn nhất sao cho A[j] < A[i].
psi'[i] là chỉ số j < i lớn nhất sao cho A'[j] < A'[i]. (Lưu ý A'[i] = A[i] vì i > y >= x).
psi'[i] là chỉ số lớn nhất j < i thỏa mãn:
j \notin \{x, y\}$ vàA[j] < A[i]`- HOẶC
j = xvàA[y] < A[i] - HOẶC
j = yvàA[x] < A[i]
Điều này có nghĩa là psi'[i] là giá trị lớn nhất trong tập:
{ j < i | j \notin \{x, y\}, A[j] < A[i] } \cup \{x \text{ nếu } A[y] < A[i] \text{ và } x < i \} \cup \{y \text{ nếu } A[x] < A[i] \text{ và } y < i \}.
Đối với i > y, cả x < i và y < i đều đúng.
`psi'[i] = \max ( \max{ j < i | j \notin {x, y}, A[j] < A[i] } \cup {x \text{ nếu } A[y] < A[i]} \cup {y \text{ nếu } A[x] < A[i]} \cup {-1} )$.
Việc tìm \max\{ j < i | j \notin \{x, y\}, A[j] < A[i] \} (chỉ số Previous Smaller Index bỏ qua x và y) có thể được thực hiện bằng cách tìm Previous Smaller Index bình thường, và Previous Smaller Index thứ hai (hoặc thứ k nếu x, y là các psi quan trọng ban đầu).
Việc tính Previous Smaller Index thứ hai (hoặc thứ k) có thể được thực hiện trong O(N). Tuy nhiên, điều này chỉ giúp tính psi_rest[i] cho một cặp x, y cố định. Vẫn cần làm điều này cho O(N^2) cặp x, y.
Cách tối ưu O(N log N) hoặc O(N) thường liên quan đến việc sử dụng các cấu trúc dữ liệu (Segment Tree, Fenwick Tree) hoặc thuật toán chia để trị để tính tổng psi[i] hoặc thay đổi của nó trên các đoạn một cách nhanh chóng, sau khi các phần tử được "cập nhật" bởi phép hoán đổi.
Một hướng tiếp cận hiệu quả có thể là:
- Tính công suất ban đầu O(N). Lưu mảng
psi. - Khởi tạo
max_power = initial_power. - Duyệt qua tất cả các cặp chỉ số
(x, y)có thể hoán đổi (O(N^2) cặp). - Với mỗi cặp
(x, y), tính thay đổi công suất do hoán đổiA[x], A[y]. - Thay đổi này là tổng của
(psi'[i] - psi[i])choitừmin(x, y) + 1đếnN-1. - Việc tính tổng thay đổi này cho một cặp
(x, y)cần được làm nhanh hơn O(N). Đây là phần khó nhất và cần sử dụng cấu trúc dữ liệu hoặc tính chất của bài toán PSI. Có thể sử dụng Segment Tree để duy trì và truy vấn thông tin về PSI trên các đoạn hoặc theo giá trị.
Do yêu cầu chỉ hướng dẫn ngắn gọn và không code hoàn chỉnh, tôi sẽ tóm tắt lại hướng giải dựa trên các bước cơ bản và điểm khó cần tối ưu:
Tóm tắt hướng giải:
- Tính công suất ban đầu: Sử dụng thuật toán Stack để tìm
prev_smaller_indexcho từng phần tử trong mảng ban đầu (O(N)). Tổng cácprev_smaller_index[i] + 1(với 0-based indexpsi[i] != -1) là công suất ban đầu. - Duyệt qua tất cả các cặp hoán đổi: Lặp qua tất cả các cặp chỉ số
(x, y)có thể hoán đổi (O(N^2) cặp). - Tính công suất sau hoán đổi (Tối ưu hóa): Thay vì thực hiện hoán đổi thật và tính lại công suất từ đầu (O(N^3) tổng), tính thay đổi công suất do hoán đổi
A[x]vàA[y]một cách hiệu quả hơn. Thay đổi này chỉ xảy ra với các chỉ sốilớn hơnmin(x, y). Việc tính tổng thay đổipsi'[i] - psi[i]cho tất cải > min(x, y)là điểm mấu chốt cần tối ưu. Điều này có thể đòi hỏi sử dụng các cấu trúc dữ liệu nâng cao như Segment Tree hoặc Fenwick Tree để nhanh chóng tính toán lại các chỉ số Previous Smaller hoặc tổng các chỉ số này trên các đoạn, có tính đến sự thay đổi giá trị tạixvày. - Cập nhật kết quả: So sánh công suất sau mỗi hoán đổi với công suất tối đa đã ghi nhận và cập nhật nếu cần.
- Kết quả: In ra công suất tối đa tìm được. S ## Làm thêm nhiều bài tập miễn phí tại đây
Comments